一、概述
概念:
是一个可靠的、可伸缩的、分布式计算的开源软件。
是一个框架,允许跨越计算机集群的大数据及分布式处理,使用简单的编程模型(mapreduce)
可从单台服务器扩展至几千台主机,每个节点提供了计算和存储功能。
不依赖于硬件处理HA,在应用层面实现
特性4V:
volumn 体量大
velocity 速度快
variaty 样式多
value 价值密度低
模块:
hadoop common 公共类库,支持其他模块
HDFS hadoop distributed file system,hadoop分布式文件系统
Hadoop yarn 作业调度和资源管理框架
hadoop mapreduce 基于yarn系统的大数据集并行处理技术。
二、安装部署
2.1 主机规划
| 主机名称 |
IP地址 |
安装节点应用 |
| hadoop-1 |
172.20.2.203 |
namenode/datanode/nodemanager |
| hadoop-2 |
172.20.2.204 |
secondarynode/datanode/nodemanager |
| hadoop-3 |
172.20.2.205 |
resourcemanager/datanode/nodemanager |
2.2 部署
2.2.1 基础环境配置
a.配置java环境
1
2
3
4
5
6
7
| yum install java-1.8.0-openjdk.x86_64 java-1.8.0-openjdk-devel -y
cat >/etc/profile.d/java.sh<<EOF
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-3.b14.el6_9.x86_64
export CLASSPATH=.:\$JAVA_HOME/jre/lib/rt.jar:\$JAVA_HOME/lib/dt.jar:\$JAVA_HOME/lib/tools.jar
export PATH=\$PATH:\$JAVA_HOME/bin
EOF
source /etc/profile.d/java.sh
|
b.修改主机名添加hosts
1
2
3
4
5
6
| hostname hadoop-1
cat >>/etc/hosts<<EOF
172.20.2.203 hadoop-1
172.20.2.204 hadoop-2
172.20.2.205 hadoop-3
EOF
|
c.创建用户及目录
1
2
3
4
5
6
7
8
| useradd hadoop
echo "hadoopwd" |passwd hadoop --stdin
mkdir -pv /data/hadoop/hdfs/{nn,snn,dn}
chown -R hadoop:hadoop /data/hadoop/hdfs/
mkdir -p /var/log/hadoop/yarn
mkdir -p /dbapps/hadoop/logs
chmod g+w /dbapps/hadoop/logs/
chown -R hadoop.hadoop /dbapps/hadoop/
|
d.配置hadoop环境变量
1
2
3
4
5
6
7
8
9
| cat>/etc/profile.d/hadoop.sh<<EOF
export HADOOP_PREFIX=/usr/local/hadoop
export PATH=\$PATH:\$HADOOP_PREFIX/bin:\$HADOOP_PREFIX/sbin
export HADOOP_COMMON_HOME=\${HADOOP_PREFIX}
export HADOOP_HDFS_HOME=\${HADOOP_PREFIX}
export HADOOP_MAPRED_HOME=\${HADOOP_PREFIX}
export HADOOP_YARN_HOME=\${HADOOP_PREFIX}
EOF
source /etc/profile.d/hadoop.sh
|
e.下载并解压软件包
1
2
3
4
5
6
| mkdir /software
cd /software
wget -c http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.5/hadoop-2.7.5.tar.gz
tar -zxf hadoop-2.6.5.tar.gz -C /usr/local
ln -sv /usr/local/hadoop-2.6.5/ /usr/local/hadoop
chown hadoop.hadoop /usr/local/hadoop-2.6.5/ -R
|
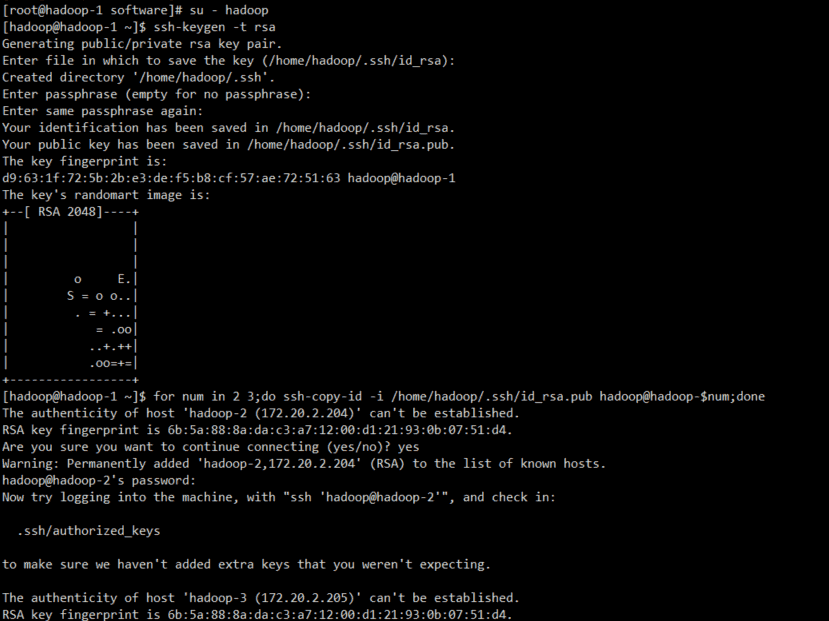
f.hadoop用户免密钥配置
1
2
3
| su - hadoop
ssh-keygen -t rsa
for num in `seq 1 3`;do ssh-copy-id -i /home/hadoop/.ssh/id_rsa.pub hadoop@hadoop-$num;done
|
2.3 配置hadoop
2.3.1 配置各节点
配置master节点
hadoop-1节点运行namenode/datanode/nodemanager,修改hadoop-1的hadoop配置文件
core-site.xml(定义namenode节点)
1
2
3
4
5
6
7
8
9
10
11
| cat>/usr/local/hadoop/etc/hadoop/core-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop-1:8020</value>
<final>true</final>
</property>
</configuration>
EOF
|
hdfs-site.xml修改replication为data节点数目 (定义secondary节点)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| cat >/usr/local/hadoop/etc/hadoop/hdfs-site.xml <<EOF
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop-2:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///data/hadoop/hdfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///data/hadoop/hdfs/dn</value>
</property>
<property>
<name>fs.checkpoint.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
<property>
<name>fs.checkpoint.edits.dir</name>
<value>file:///data/hadoop/hdfs/snn</value>
</property>
</configuration>
EOF
|
添加mapred-site.xml
1
2
3
4
5
6
7
8
9
10
| cat >/usr/local/hadoop/etc/hadoop/mapred-site.xml <<EOF
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
EOF
|
yarn-site.xml修改对应values为master的主机名(定义resourcemanager节点)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| cat >/usr/local/hadoop/etc/hadoop/yarn-site.xml<<EOF
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>hadoop-3:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>hadoop-3:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>hadoop-3:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>hadoop-3:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>hadoop-3:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
</configuration>
EOF
|
slaves(定义数据节点)
1
2
3
4
5
| cat >/usr/local/hadoop/etc/hadoop/slaves<<EOF
hadoop-1
hadoop-2
hadoop-3
EOF
|
同样的步骤操作hadoop-2/3,建议将hadoop-1的文件直接分发至hadoop-2/3
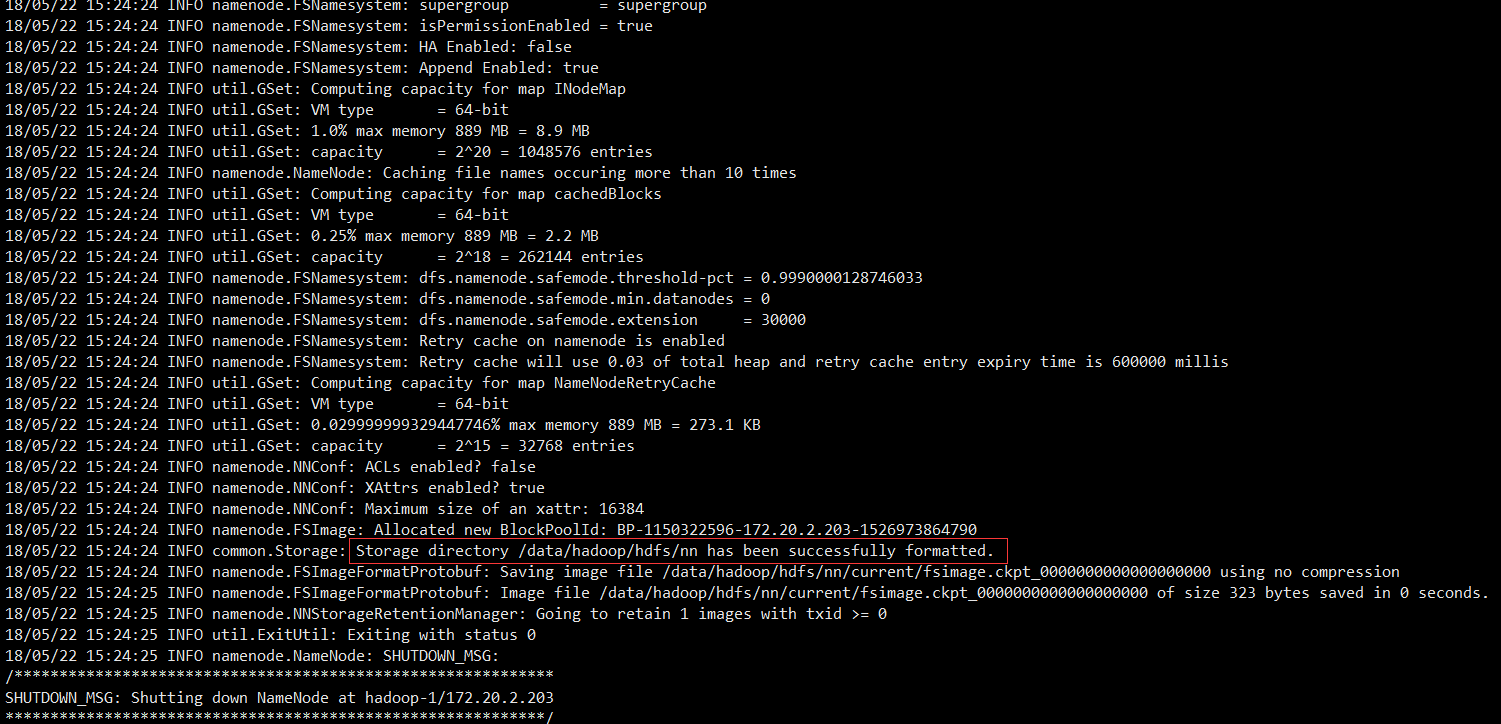
2.3.2 格式化namenode
在NameNode机器上(hadoop-1)执行格式化:


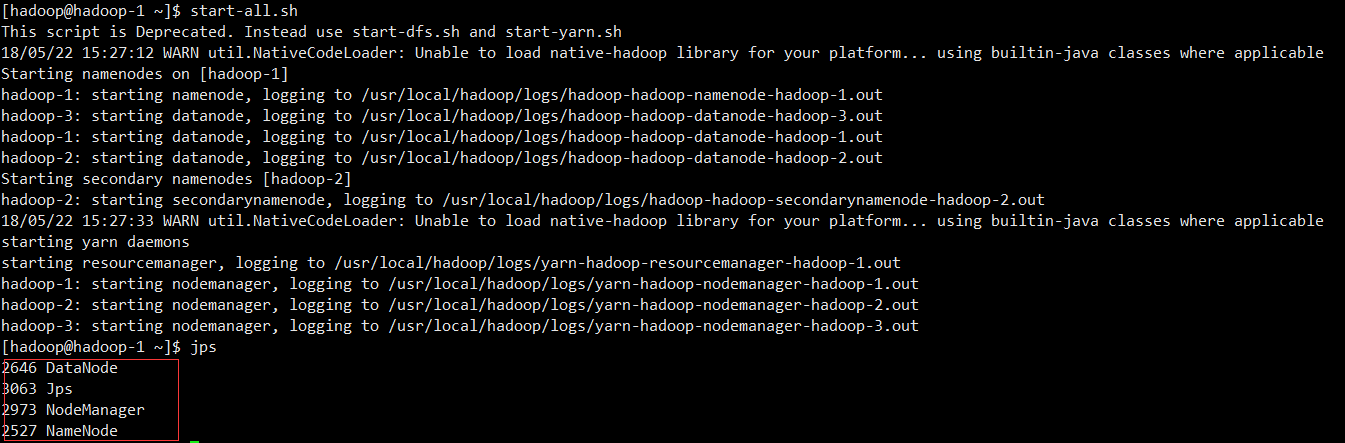
2.3.3 启动服务
在namenode hadoop-1执行start-all.sh启动服务
在hadoop-3启动resourcemanager服务``
hadoop-2服务查看
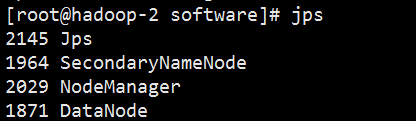
hadoop-3服务查看

2.3.4 运行测试程序
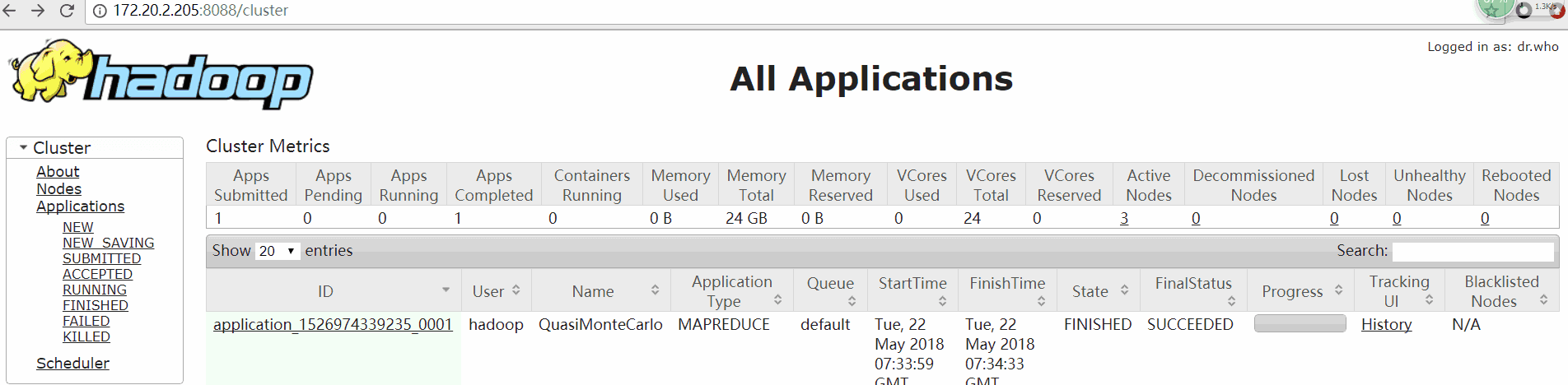
yarn jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.5.jar pi 2 10
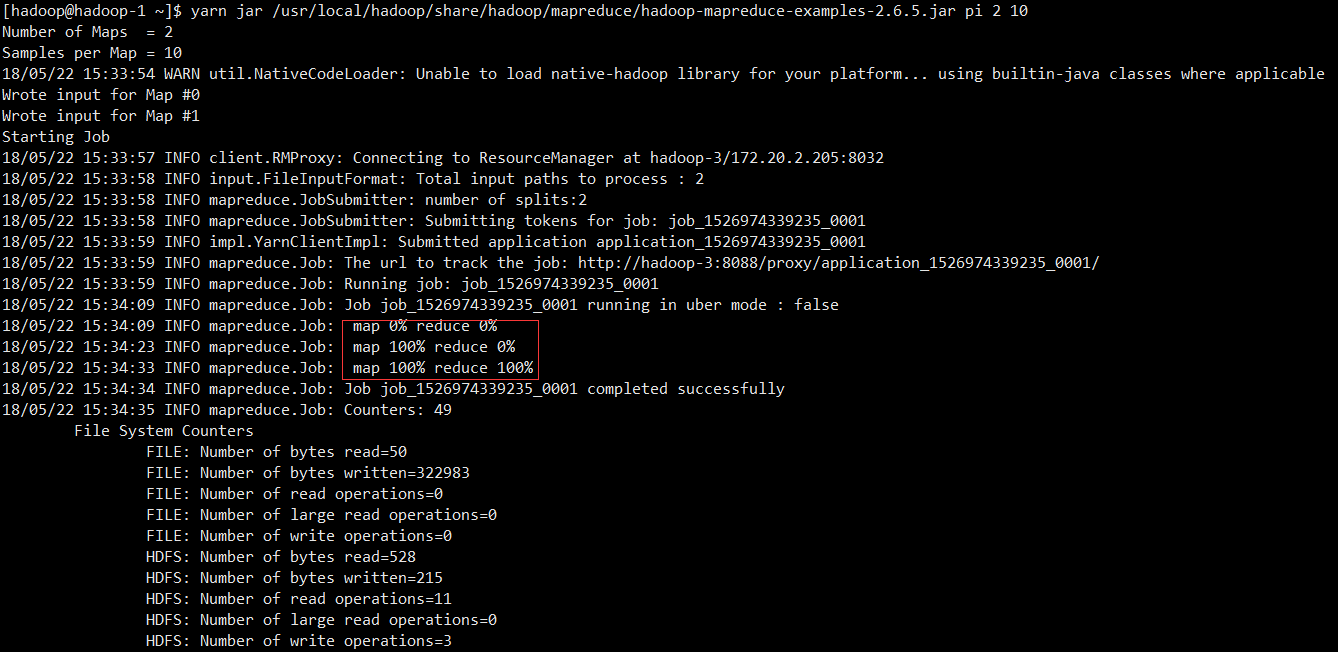
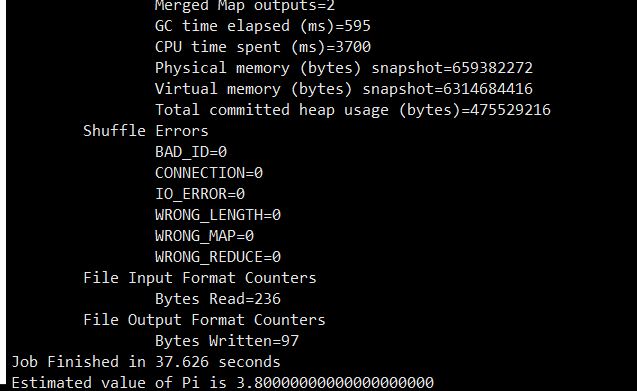
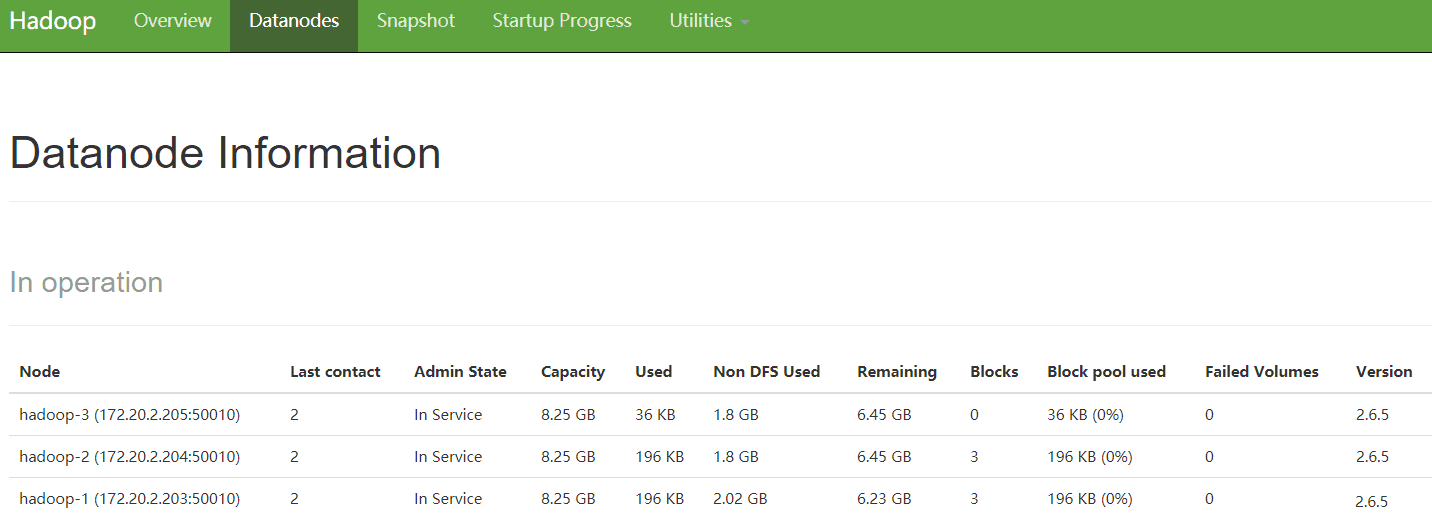
2.3.5 查看web界面
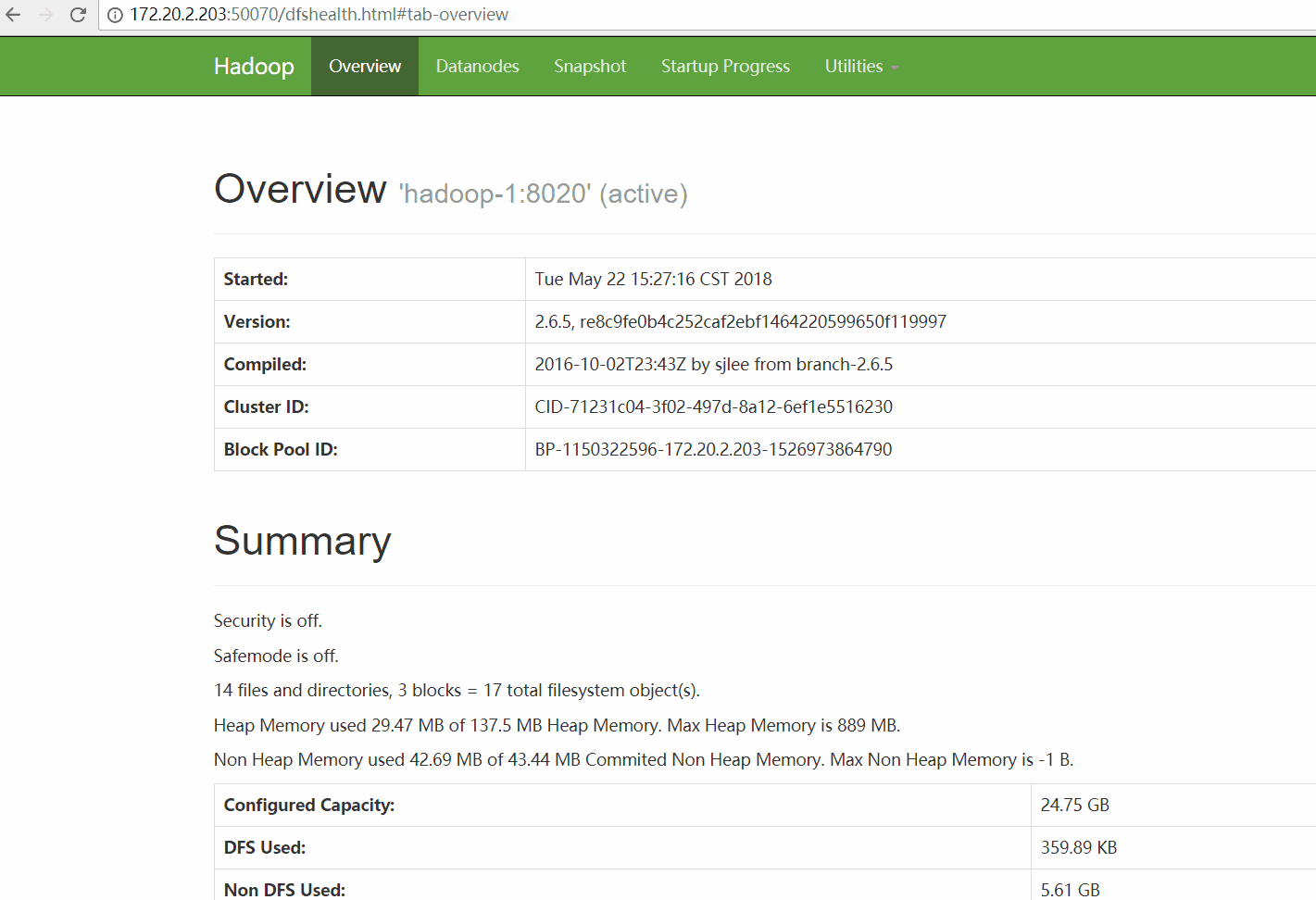
HDFS-NameNode
url:http://172.20.2.203:50070
YARN-ResourceManager
url:http://172.20.2.205:8088