1. 网络拓扑
192.168.1.80 Master
192.168.1.82 Slave1
192.168.1.84 Slave2
2. 安装JDK 所有实验主机都需要正确的安装JDK,具体操作方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 chu888chu888@ubuntu1 :~ $ tar xvfz jdk-8u65-linux-x64.gz chu888chu888@ubuntu1 :~ $ sudo cp -r jdk1.8.0_65 / /usr/lib /jvm/ chu888chu888@ubuntu1 :/usr/lib/jvm $ sudo nano /etc/profile export JAVA_HOME =/usr/lib /jvm/ export JRE_HOME =${ JAVA_HOME }/jre export CLASSPATH =.: ${ JAVA_HOME }/lib: ${ JRE_HOME }/lib export PATH =${ JAVA_HOME }/bin: $PATH chu888chu888@ubuntu1 :/usr/lib/jvm $ source /etc/profile chu888chu888@ubuntu1 :/usr/lib/jvm $ env chu888chu888@ubuntu1 :/usr/lib/jvm $ java -version java version "1.8.0_65" Java (TM ) SE Runtime Environment (build 1.8 .0_65 -b17)Java HotSpot (TM ) 64 -Bit Server VM (build 25.65 -b01, mixed mode)sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/java/bin/java 300 sudo update-alternatives --install /usr/bin/javac javac /usr/lib/jvm/java/bin/javac 300 sudo update-alternatives --install /usr/bin/jar jar /usr/lib/jvm/java/bin/jar 300 sudo update-alternatives --install /usr/bin/javah javah /usr/lib/jvm/java/bin/javah 300 sudo update-alternatives --install /usr/bin/javap javap /usr/lib/jvm/java/bin/javap 300 sudo update-alternatives --config java sudo update-alternatives --config javac
这里面我简单补充一下,其他相关知识,因为涉及到主机之间的安装文件传递,我们可以使用sftp命令进行.
1 2 3 4 5 6 7 8 9 10 11 12 chu888chu888 @ubuntu-hadoop:~$ sftp chu888chu888@192.168.1.84 The authenticity of host '192.168.1.84 (192.168.1.84 )' can't be established.ECDSA key fingerprint is 6 c:00 :fb:9 b:43 :6 c:3 b:29 :96 :98 :a8:28 :d1:23 :11 :13 .Are you sure you want to continue connecting (yes/no)? yesWarning : Permanently added '192.168.1.84 ' (ECDSA) to the list of known hosts.chu888chu888 @192.168.1.84 's password: Connected to 192.168.1.84 .sftp > put jdk-8 u65-linux-x64.gz Uploading jdk-8 u65-linux-x64.gz to /home/chu888chu888/jdk-8 u65-linux-x64.gzjdk -8 u65-linux-x64.gz 100 % 173 MB 28 .8 MB/s 00 :06 sftp >
3. Hadoop用户的创建 1 2 3 4 5 6 7 8 创建hadoop用户组 创建hadoop用户 给hadoop用户添加权限,打开/etc/sudoers文件 chu888chu888@ubuntu1 :/ $ sudo addgroup hadoop chu888chu888@ubuntu1 :/ $ sudo adduser -ingroup hadoop hadoop chu888chu888@ubuntu1 :/ $ sudo nano /etc/sudoers root ALL =(ALL :ALL ) ALL hadoop ALL =(ALL :ALL ) ALL
4. hosts文件修改 所有的主机的hosts都需要修改,在这里我吃了一个大亏,如果在etc配置文件中直接用Ip的话,可能会出现Datanode链接不上Namenode的现象.
1 2 3 4 5 6 7 8 9 10 11 hadoop@ubuntu-hadoop:/usr/local/hadoop/etc/hadoop$ more /etc/hosts 127.0.0.1 localhost192.168.1.80 Master192.168.1.82 Slave1# The following lines are desirable for IPv6 capable hosts ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters hadoop@ubuntu-hadoop:/usr/local/hadoop/etc/hadoop$
5. SSH无密码登录 所有的主机都要进行操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 这个操作是要让Master节点可以在无密码的状态下SSH登录到各个Slave节点上 首先生成Master节点的公钥,在Master节点的终端中执行 # 如果没有该目录,先执行一次ssh localhost $ cd ~/.ssh# 删除之前生成的公钥 $ rm ./id_rsa*# 一直按回车就可以了 $ ssh-keygen -t rsa 让Master节点需能无密码的SSH本机,在Master节点上执行 $ cat ./id_rsa.pub>>./authorized_keys完成后可执行ssh Master验证一下,接着需要把Master节点的公钥上传输到Slave1节点上 $ sftp hadoop@Slave1 接着在Slave1节点上,将ssh公钥加入授权 $ mkdir ~/.ssh$ cat ~/id_rsa.pub>>~/.ssh/authorized_keys$ rm ~/id_rsa.pub如果有其他的Slave节点,也要执行将Master公钥传输到Slave节点,在Slave节点加入授权这两步. 这样,在Master节点就可以无密码SSH到各个Slave节点了.
6. Hadoop的安装 1 2 3 4 chu888chu888@ubuntu1 :~ $ sudo tar xvfz hadoop-2.6 .0 .tar.gz chu888chu888@ubuntu1 :~ $ sudo cp -r hadoop-2.6 .0 /usr/local/hadoop chu888chu888@ubuntu1 :~ $ sudo chmod -R 775 /usr/local/hadoop/ chu888chu888@ubuntu1 :~ $ sudo chown -R hadoop: hadoop /usr/local/hadoop
这里面有一个小的体验技巧,我建议将所有需要的环境变量配置加入到/etc/profile中,这是全局变量.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 export JAVA_HOME =/usr/lib/jvm/export JRE_HOME =${JAVA_HOME} /jreexport CLASSPATH =.:${JAVA_HOME}/lib:${JRE_HOME} /libexport PATH =${JAVA_HOME} /bin:$PATHexport JAVA_HOME =/usr/lib/jvm/export HADOOP_INSTALL =/usr/local/hadoopexport PATH =$PATH :$HADOOP_INSTALL/binexport PATH =$PATH :$JAVA_HOME/binexport PATH =$PATH :$HADOOP_INSTALL/sbinexport HADOOP_MAPRED_HOME =$HADOOP_INSTALL export HADOOP_COMMON_HOME =$HADOOP_INSTALL export HADOOP_HDFS_HOME =$HADOOP_INSTALL export YARN_HOME =$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR =$HADOOP_INSTALL /lib/nativeexport HADOOP_OPTS ="-Djava.library.path=$HADOOP_INSTALL /lib" 还有一个问题就是,在启动hadoop的时候经常会出现,找不到JAVA_HOME的问题,这个问题可以通过修改hadoop环境变量来解决,直接写死变量就可以了. $ more hadoop-env.sh export JAVA_HOME =/usr/lib/jvm/
7. 配置集群环境192.168.1.80 NameNode 集群/分布式模式需要修改 /usr/local/hadoop/etc/hadoop 中的5个配置文件,更多设置项可点击查看官方说明,这里仅设置了正常启动所必须的设置项: slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml 。
8. 文件slaves 文件 slaves,将作为 DataNode 的主机名写入该文件,每行一个,默认为 localhost,所以在伪分布式配置时,节点即作为 NameNode 也作为 DataNode。分布式配置可以保留 localhost,也可以删掉,让 Master 节点仅作为 NameNode 使用。
1 2 3 4 5 6 7 hadoop@ubuntu - hadoop:~ $ cd /usr/ local/hadoop/ etc/hadoop/ hadoop@ubuntu - hadoop:/usr/ local/hadoop/ etc/ hadoop$ sudo nano slaves [sudo] password for hadoop: hadoop@ubuntu - hadoop:/usr/ local/hadoop/ etc/ hadoop$ more slaves Slave1 hadoop@ubuntu - hadoop:/usr/ local/hadoop/ etc/ hadoop$
9. 文件 core-site.xml 改为下面的配置: 1 2 3 4 5 6 7 8 9 10 11 12 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://Master:9000</value > </property > <property > <name > hadoop.tmp.dir</name > <value > file:/usr/local/hadoop/tmp</value > <description > Abase for other temporary directories.</description > </property > </configuration >
10. 文件 hdfs-site.xml,dfs.replication 一般设为 3,但我们只有一个 Slave 节点,所以 dfs.replication 的值还是设为 1: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 <configuration > <property > <name > dfs.namenode.secondary.http-address</name > <value > Master:50090</value > </property > <property > <name > dfs.replication</name > <value > 1</value > </property > <property > <name > dfs.namenode.name.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/name</value > </property > <property > <name > dfs.datanode.data.dir</name > <value > file:/usr/local/hadoop/tmp/dfs/data</value > </property > </configuration >
11. 文件 mapred-site.xml (可能需要先重命名,默认文件名为 mapred-site.xml.template),然后配置修改如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 <configuration > <property > <name > mapreduce.framework.name</name > <value > yarn</value > </property > <property > <name > mapreduce.jobhistory.address</name > <value > Master:10020</value > </property > <property > <name > mapreduce.jobhistory.webapp.address</name > <value > Master:19888</value > </property > </configuration >
12. 文件 yarn-site.xml: 1 2 3 4 5 6 7 8 9 10 <configuration > <property > <name > yarn.resourcemanager.hostname</name > <value > Master</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > </configuration >
13. 在其他Slave节点需要做的 首先通过sftp把Master配置好的hadoop打包,之后转输到Slave节点上,配置好环境变量JDK PATH SSH 基本上与Master是一样的.
1 2 3 4 5 6 7 8 9 cd /usr/localsudo rm -r ./hadoop/tmpsudo rm -r ./hadoop/logs/* tar -cvfz ~/hadoop.master.tar.gz ./hadoop
在Slave节点上执行:
1 2 3 4 sudo rm -r /usr/local/hadoop sudo tar -xvfz ~/hadoop.master.tar.gz -C /usr/localsudo chown -R hadoop:hadoop /usr/local/hadoop
14. 开始启动集群 1 2 3 4 5 6 7 8 9 10 11 12 13 hdfs namenode -format 在Master上执行: $start -dfs.sh$start -yarn.sh$mr -jobhistory-daemon.sh start historyserverCentos6.X需要关闭防火墙 sudo service iptables stop sudo chkconfig iptables off Cent7 systemctl stop firewalld.service systemctl disable firewalld.service
之后分别在Master与Slave上执行jps,会看到不同的结果.缺少任一进程都表示出错。另外还需要在 Master 节点上通过命令 hdfs dfsadmin -report 查看 DataNode 是否正常启动,如果 Live datanodes 不为 0 ,则说明集群启动成功。例如我这边一共有 1 个 Datanodes:
1 2 3 4 $jps $hdfs dfsadmin -report可以访问http:
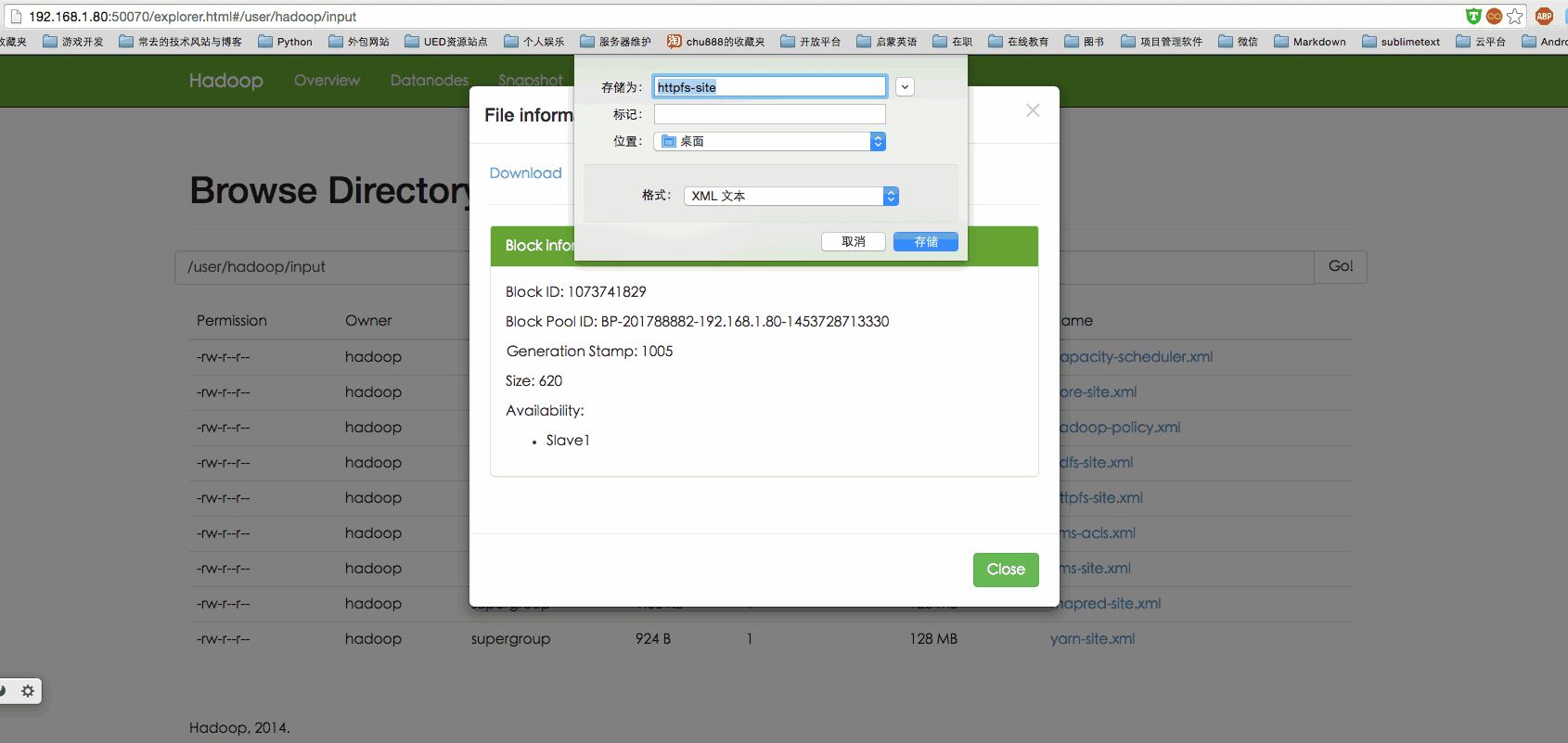
15. 执行分布式的实验-分布式存储 1 2 3 4 5 6 执行分布式实例过程与伪分布式模式一样,首先创建 HDFS 上的用户目录: $ hdfs dfs -mkdir -p /user/hadoop 将 /usr/local/hadoop/etc/hadoop 中的配置文件作为输入文件复制到分布式文件系统中: $ hdfs dfs -mkdir input $ hdfs dfs -put /usr/local/hadoop/etc/hadoop/*.xml input
通过查看 DataNode 的状态(占用大小有改变),输入文件确实复制到了 DataNode 中,如下图所示:
16. 执行分布式的实验-MapReduce 执行MapReduce作业
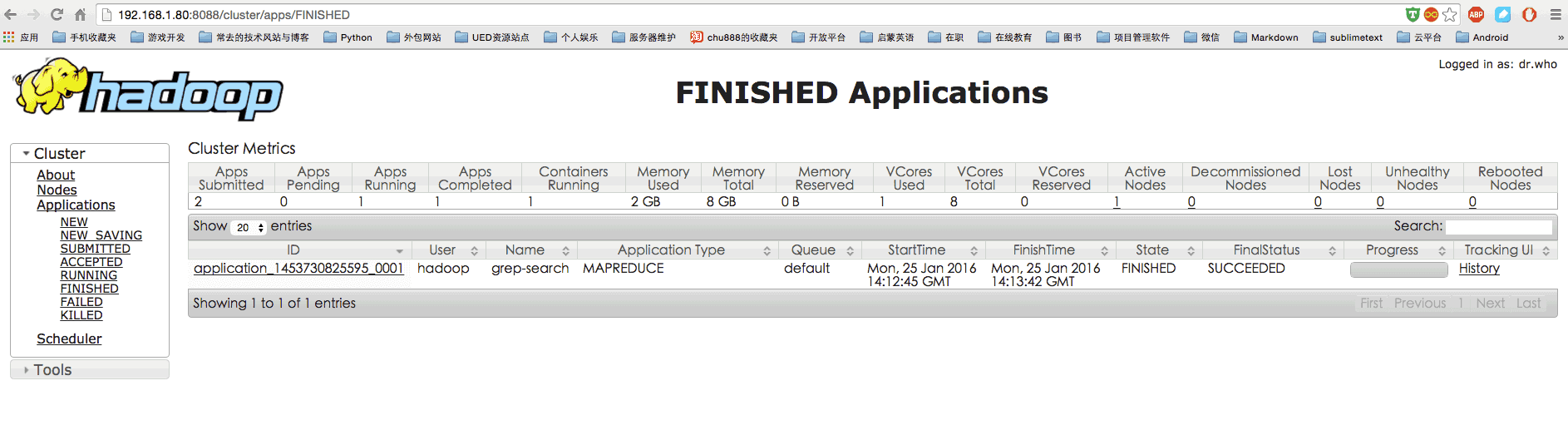
1 2 hadoop jar /usr/ local/hadoop/ share/hadoop/m apreduce/hadoop-mapreduce-examples-*.jar grep /u ser/hadoop/i nput /user/ hadoop/output 'dfs[a-z.]+' 查看http:// 192.168 .1.80 :8088 /cluster看结果
运行时的输出信息与伪分布式类似,会显示 Job 的进度。
可能会有点慢,但如果迟迟没有进度,比如 5 分钟都没看到进度,那不妨重启 Hadoop 再试试。若重启还不行,则很有可能是内存不足引起,建议增大虚拟机的内存,或者通过更改 YARN 的内存配置解决。http://master:8088/cluster,在 Web 界面点击 “Tracking UI” 这一列的 History 连接,可以看到任务的运行信息,如下图所示:
17. 关闭集群 1 2 3 stop -yarn.sh stop -dfs.sh mr-jobhistory-daemon.sh stop historyserver