大数据hadoop之 三十二.HBASE介绍
本文于2430天之前发表,文中内容可能已经过时。
一 引子
在说Hase是个啥家伙之前,首先我们来看看两个概念,面向行存储和面向列存储。面向行存储,我相信大伙儿应该都清楚,我们熟悉的RDBMS就是此种类型的,面向行存储的数据库主要适合于事务性要求严格场合,或者说面向行存储的存储系统适合OLTP,但是根据CAP理论(参考:CAP理论参考),传统的RDBMS,为了实现强一致性,通过严格的ACID事务来进行同步,这就造成了系统的可用性和伸缩性方面大大折扣,而目前的很多NoSQL产品,包括Hbase,它们都是一种最终一致性的系统,它们为了高的可用性牺牲了一部分的一致性。好像,我上面说了面向列存储,那么到底什么是面向列存储呢?Hbase,Casandra,Bigtable都属于面向列存储的分布式存储系统。看到这里,如果您不明白Hbase是个啥东东,不要紧,我再总结一下下:
Hbase是一个面向列存储的分布式存储系统,它的优点在于可以实现高性能的并发读写操作,同时Hbase还会对数据进行透明的切分,这样就使得存储本身具有了水平伸缩性。
二 Hbase是个啥东东?
HBase建立在HDFS之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统。它介于NoSQL和RDBMS之间,仅能通过行键(row key)和行键序列来检索数据,仅支持单行事务(可通过Hive支持来实现多表联合等复杂操作)。主要用来存储非结构化和半结构化的松散数据。与Hadoop一样,HBase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase表一般有这样的特点:
- 大:一个表可以有上亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
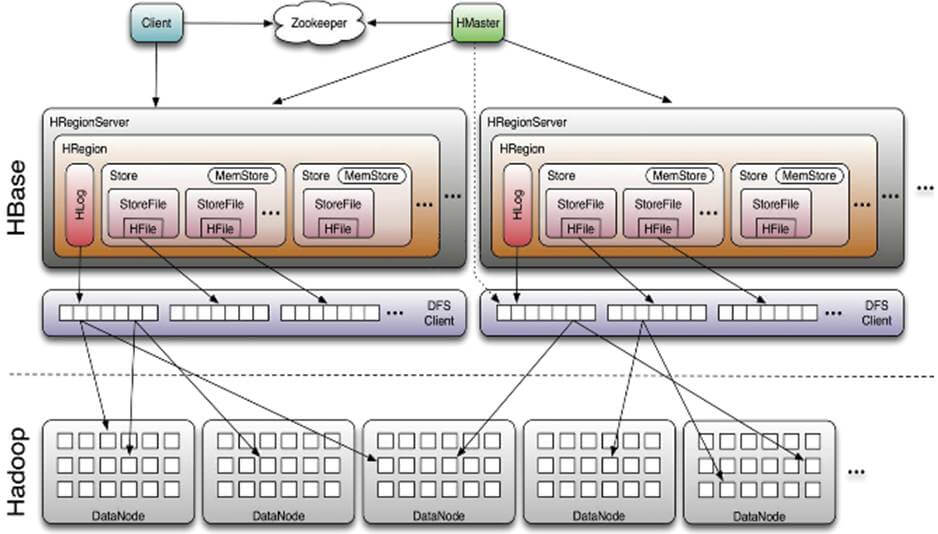
三 HBase体系架构
HBase的服务器体系结构遵循简单的主从服务器架构。它由HRegion Server和HMaster组成,HMaster负责管理所有的HRegion Server,HBase中所有的服务器都通过ZooKeeper来协调。HBase的体系结构如下图所示。
四 Hbase的二类数据模型
HBASE的二类数据模型是指从逻辑模型与物理模型来了解Hbase的数据模型,表是HBase表达数据的逻辑组织方式,而基于列的存储则是数据在底层的组织方式.
1 逻辑模型
HBase,Cassandra的数据模型非常类似,他们的思想都是来源于Google的Bigtable,因此这三者的数据模型非常类似,唯一不同的就是Cassandra具有Super cloumn family的概念,而Hbase目前我没发现。
在Hbase里面有以下两个主要的概念,Row key,Column Family,我们首先来看看Column family,Column family中文又名“列族”,Column family是在系统启动之前预先定义好的,每一个Column Family都可以根据“限定符”有多个column.下面我们来举个例子就会非常的清晰了。
假如系统中有一个User表,如果按照传统的RDBMS的话,User表中的列是固定的,比如schema 定义了name,age,sex等属性,User的属性是不能动态增加的。但是如果采用列存储系统,比如Hbase,那么我们可以定义User表,然后定义info 列族,User的数据可以分为:info:name = zhangsan,info:age=30,info:sex=male等,如果后来你又想增加另外的属性,这样很方便只需要info:newProperty就可以了。
也许前面的这个例子还不够清晰,我们再举个例子来解释一下,熟悉SNS的朋友,应该都知道有好友Feed,一般设计Feed,我们都是按照“某人在某时做了标题为某某的事情”,但是同时一般我们也会预留一下关键字,比如有时候feed也许需要url,feed需要image属性等,这样来说,feed本身的属性是不确定的,因此如果采用传统的关系数据库将非常麻烦,况且关系数据库会造成一些为null的单元浪费,而列存储就不会出现这个问题,在Hbase里,如果每一个column 单元没有值,那么是占用空间的。下面我们通过两张图来形象的表示这种关系:

上图是传统的RDBMS设计的Feed表,我们可以看出feed有多少列是固定的,不能增加,并且为null的列浪费了空间。但是我们再看看下图,下图为Hbase,Cassandra,Bigtable的数据模型图,从下图可以看出,Feed表的列可以动态的增加,并且为空的列是不存储的,这就大大节约了空间,关键是Feed这东西随着系统的运行,各种各样的Feed会出现,我们事先没办法预测有多少种Feed,那么我们也就没有办法确定Feed表有多少列,因此Hbase,Cassandra,Bigtable的基于列存储的数据模型就非常适合此场景。说到这里,采用Hbase的这种方式,还有一个非常重要的好处就是Feed会自动切分,当Feed表中的数据超过某一个阀值以后,Hbase会自动为我们切分数据,这样的话,查询就具有了伸缩性,而再加上Hbase的弱事务性的特性,对Hbase的写入操作也将变得非常快。
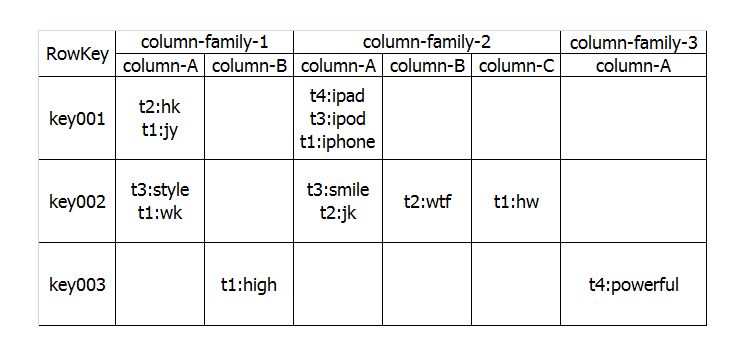
上面说了Column family,那么我之前说的Row key是啥东东,其实你可以理解row key为RDBMS中的某一个行的主键,但是因为Hbase不支持条件查询以及Order by等查询,因此Row key的设计就要根据你系统的查询需求来设计了额。我还拿刚才那个Feed的列子来说,我们一般是查询某个人最新的一些Feed,因此我们Feed的Row key可以有以下三个部分构成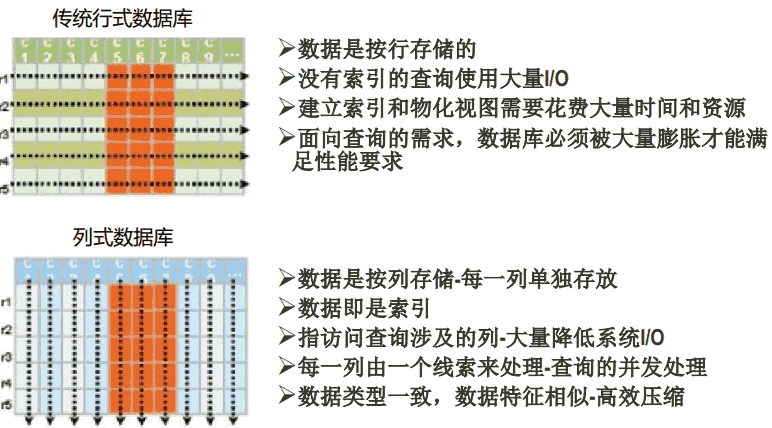
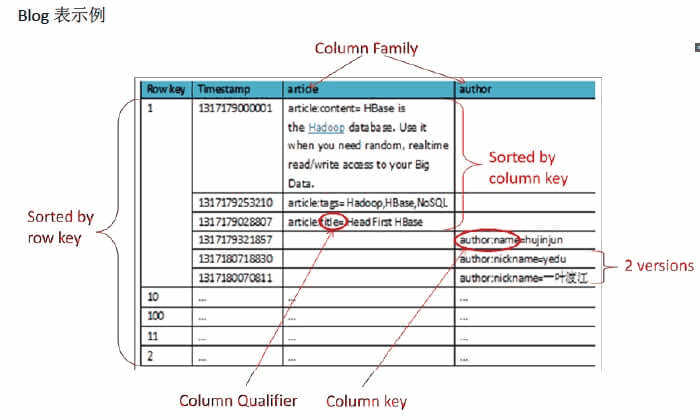
2 物理模型
已经提到过,Table中的所有行都按照row key的字典序排列。
Table 在行的方向上分割为多个Hregion。
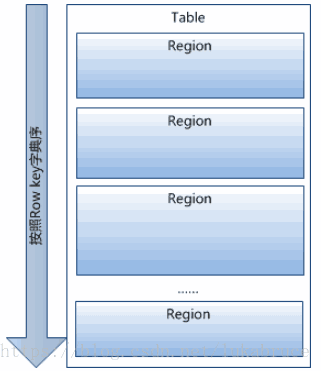
- region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。当table中的行不断增多,就会有越来越多的Hregion。
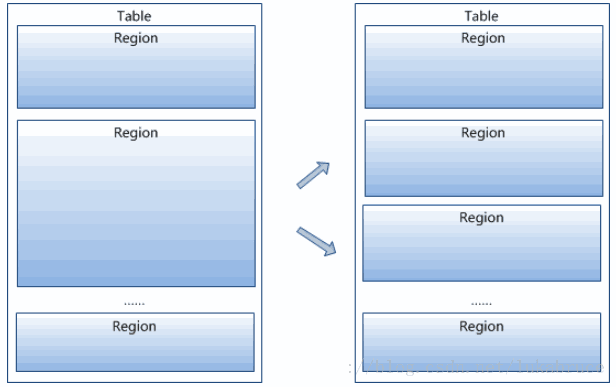
- Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
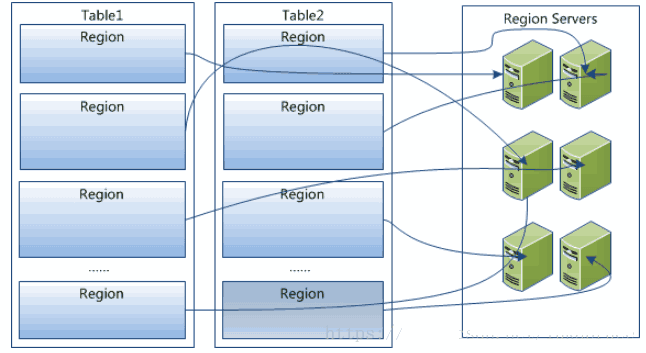
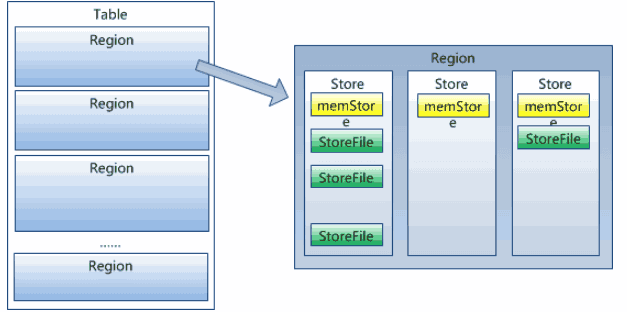
- HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。
事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。如图:
StoreFile以HFile格式保存在HDFS上。
HFile的格式为:
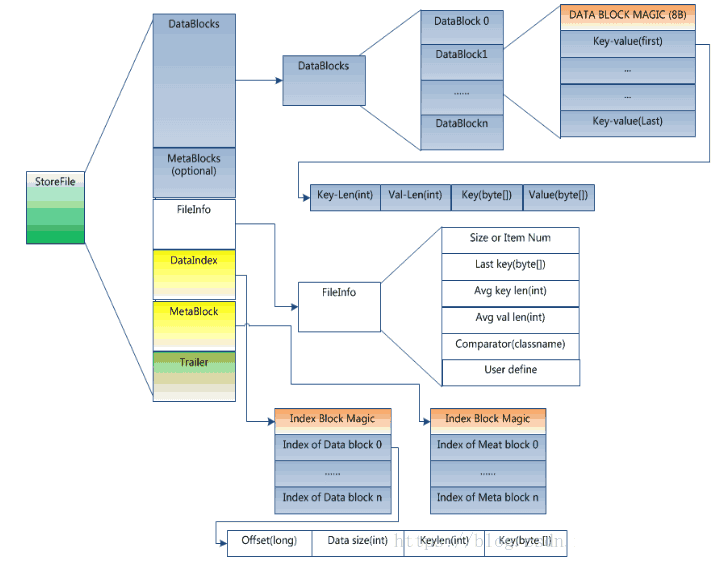
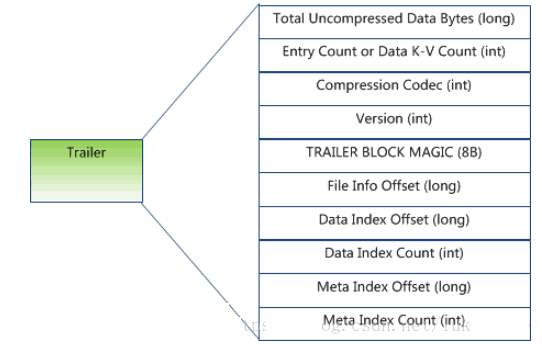
Trailer部分的格式:
HFile分为六个部分:
Data Block 段–保存表中的数据,这部分可以被压缩
Meta Block 段 (可选的)–保存用户自定义的kv对,可以被压缩。
File Info 段–Hfile的元信息,不被压缩,用户也可以在这一部分添加自己的元信息。
Data Block Index 段–Data Block的索引。每条索引的key是被索引的block的第一条记录的key。
Meta Block Index段 (可选的)–Meta Block的索引。
Trailer–这一段是定长的。保存了每一段的偏移量,读取一个HFile时,会首先 读取Trailer,Trailer保存了每个段的起始位置(段的Magic Number用来做安全check),然后,DataBlock Index会被读取到内存中,这样,当检索某个key时,不需要扫描整个HFile,而只需从内存中找到key所在的block,通过一次磁盘io将整个 block读取到内存中,再找到需要的key。DataBlock Index采用LRU机制淘汰。
HFile的Data Block,Meta Block通常采用压缩方式存储,压缩之后可以大大减少网络IO和磁盘IO,随之而来的开销当然是需要花费cpu进行压缩和解压缩。
目标Hfile的压缩支持两种方式:Gzip,Lzo。
HLog(WAL log)
WAL 意为Write ahead log(http://en.wikipedia.org/wiki/Write-ahead_logging) ,类似mysql中的binlog,用来 做灾难恢复只用,Hlog记录数据的所有变更,一旦数据修改,就可以从log中进行恢复。
每个Region Server维护一个Hlog,而不是每个Region一个。这样不同region(来自不同table)的日志会混在一起,这样做的目的是不断追加单个 文件相对于同时写多个文件而言,可以减少磁盘寻址次数,因此可以提高对table的写性能。带来的麻烦是,如果一台region server下线,为了恢复其上的region,需要将region server上的log进行拆分,然后分发到其它region server上进行恢复。
HLog文件就是一个普通的Hadoop Sequence File,Sequence File 的Key是HLogKey对象,HLogKey中记录了写入数据的归属信息,除了table和region名字外,同时还包括 sequence number和timestamp,timestamp是”写入时间”,sequence number的起始值为0,或者是最近一次存入文件系统中sequence number。HLog Sequece File的Value是HBase的KeyValue对象,即对应HFile中的KeyValue,可参见上文描述。
五 HBase and Hive?
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
1 区别:
Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
2 关系
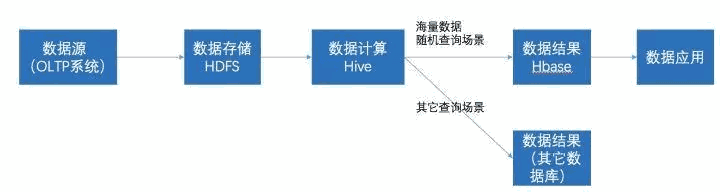
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
通过ETL工具将数据源抽取到HDFS存储;
通过Hive清洗、处理和计算原始数据;
HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
数据应用从HBase查询数据;
3 HBase实例及代码解释
要想使用HBase存取数据必须要有两个步骤:
1)、建立HBase表
1 | create 'test','info' |
上面创建了一个HBase的test表,用于HBase和数据库做映射使用,同时往这个表里put了两行数据,分别是101和102(row key),info代表列簇,包含了name和sex两列的值
2)、建立HBase外表
1 | create external table hbase_test(id string, name string,sex string) |
上述建立了一张外表,stored by制定HBase的存储格式,with后面是序列化和反序列化,作用是进行map映射,从上面的语句可以看出,将id映射成了key、将name、和sex映射成了info(列簇)