大数据hadoop之 三十七.HBASE与传统数据库的区别
本文于2426天之前发表,文中内容可能已经过时。
一 主要区别
Hbase适合大量插入同时又有读的情况
Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间。
Hbase本质上只有一种操作,就是插入,其更新操作是插入一个带有新的时间戳的行,而删除是插入一个带有插入标记的行。其主要操作是收集内存中一批数据,然后批量的写入硬盘,所以其写入的速度主要取决于硬盘传输的速度。Oracle则不同,因为他经常要随机读写,这样硬盘磁头需要不断的寻找数据所在,所以瓶颈在于硬盘寻道时间。
- Hbase很适合寻找按照时间排序top n的场景。
- 索引不同造成行为的差异。
- Oracle 这样的传统数据库既可以做OLTP又可以做OLAP,但在某种极端的情况下(负荷十分之大),就不适合了。
二 Hbase的局限:
只能做简单的Key value查询,复杂的sql统计做不到。
只能在row key上做快速查询。
三 传统数据库的行式存储
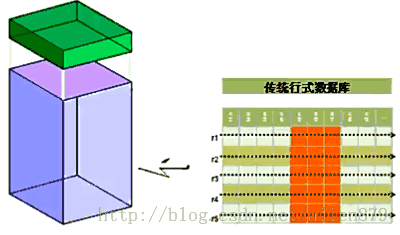
在数据分析的场景里面,我们经常是以某个列作为查询条件,返回的结果经常也只是某些列,不是全部的列。行式数据库在这种情况下的I/O性能会很差,以Oracle为例,Oracle会有一个很大的数据文件,在这个数据文件中,划分了很多block,然后在每个block中放入行,行是一行一行放进去,挤在一起,然后把block塞满,当然也会预留一些空间,用于将来update。这种结构的缺点是:当我们读某个列的时候,比如我们只需要读红色标记的列的时候,不能只读这部分数据,我必须把整个block读取到内存中,然后再把这些列的数据取出来,换句话说,我为了读表中某些列的数据,我必须把整个列的行读完,才可以读到这些列。如果这些列的数据很少,比如1T的数据中只占了100M, 为了读100M数据却要读取1TB的数据到内存中去,则显然是不划算。
四 B+索引
Oracle中采用的数据访问技术主要是B数索引:

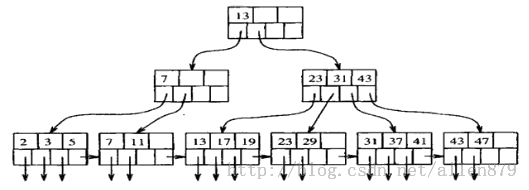
从树的跟节点出发,可以找到叶子节点,其记录了key值对应的那行的位置。
对B树的操作:
B树插入——分裂节点
B数删除——合并节点
五 列式存储
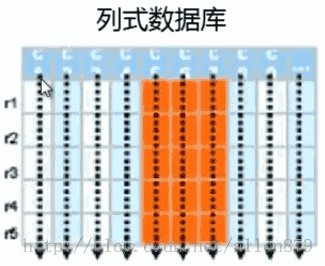
同一个列的数据会挤在一起,比如挤在block里,当我需要读某个列的时候,值需要把相关的文件或块读到内存中去,整个列就会被读出来,这样I/O会少很多。
同一个列的数据的格式比较类似,这样可以做大幅度的压缩。这样节省了存储空间,也节省了I/O,因为数据被压缩了,这样读的数据量随之也少了。
行式数据库适合OLTP,反倒列式数据库不适合OLTP。
当今的数据处理大致可以分成两大类:联机事务处理OLTP(on-line transaction processing)、联机分析处理OLAP(On-Line Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果.
OLTP:
也称为面向交易的处理系统,其基本特征是顾客的原始数据可以立即传送到计算中心进行处理,并在很短的时间内给出处理结果。
这样做的最大优点是可以即时地处理输入的数据,及时地回答。也称为实时系统(Real time System)。衡量联机事务处理系统的一个重要性能指标是系统性能,具体体现为实时响应时间(Response Time),即用户在终端上送入数据之后,到计算机对这个请求给出答复所需要的时间。OLTP是由数据库引擎负责完成的。
OLTP 数据库旨在使事务应用程序仅写入所需的数据,以便尽快处理单个事务。
OLAP:
简写为OLAP,随着数据库技术的发展和应用,数据库存储的数据量从20世纪80年代的兆(M)字节及千兆(G)字节过渡到现在的兆兆(T)字节和千兆兆(P)字节,同时,用户的查询需求也越来越复杂,涉及的已不仅是查询或操纵一张关系表中的一条或几条记录,而且要对多张表中千万条记录的数据进行数据分析和信息综合,关系数据库系统已不能全部满足这一要求。在国外,不少软件厂商采取了发展其前端产品来弥补关系数据库管理系统支持的不足,力图统一分散的公共应用逻辑,在短时间内响应非数据处理专业人员的复杂查询要求。
联机分析处理(OLAP)系统是数据仓库系统最主要的应用,专门设计用于支持复杂的分析操作,侧重对决策人员和高层管理人员的决策支持,可以根据分析人员的要求快速、灵活地进行大数据量的复杂查询处理,并且以一种直观而易懂的形式将查询结果提供给决策人员,以便他们准确掌握企业(公司)的经营状况,了解对象的需求,制定正确的方案。
六 BigTable的LSM(Log Struct Merge)索引
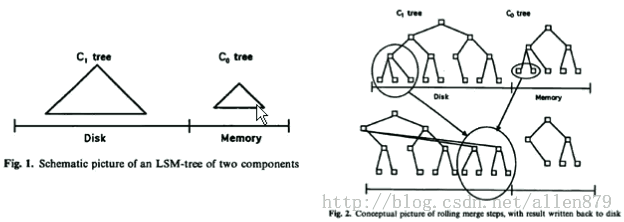
在Hbase中日志即数据,数据就是日志,他们是一体化的。为什么这么说了,因为Hbase的更新时插入一行,删除也是插入一行,然后打上删除标记,则不就是日志吗?
在Hbase中,有Memory Store,还有Store File,其实每个Memory Store和每个Store File就是对每个列族附加上一个B+树(有点像Oracle的索引组织表,数据和索引是一体化的), 也就是图的下面是列族,上面是B+树,当进行数据的查询时,首先会在内存中memory store的B+树中查找,如果找不到,再到Store File中去找。
如果找的行的数据分散在好几个列族中,那怎么把行的数据找全呢?那就需要找好几个B+树,这样效率就比较低了。所以尽量让每次insert的一行的列族都是稀疏的,只在某一个列族上有值,其他列族没有值,