大数据hadoop之 四十.HBASE的数据迁移
本文于2423天之前发表,文中内容可能已经过时。
概述
将数据移到Hbase的方法有以下几种:
- 使用Hbase的Put API
- 使用HBase的批量加载工具
- 使用自定义的MapReduce方法
使用HBase的Put API是最直接的方法.这种方法的使用并不难学,但大多数情况下,它并非总是最有效的方法.特别是在有一大批数据需要移入Hbase并且对移入都是问题又有限定的情况下,这种方法的效率并不高.我们需要处理的数据通常都有很大的数据量,这可能也是我们使用Hbase而不是其他数据库的原因.你必须在HBase的项目的开始阶段就仔细考虑如何将所有数据转入Hbase,否则你将会遇到一些严重的性能问题.
Hbase提供了批量加载的功能来支持高效地将大量数据加载到HBase中.批量加载功能使用了一个MapReduce任务将数据加载到一个特定的Hbase表中.它会生成一些HBase内部的HFile数据格式的文件,然后再将这些数据文件直接加载到正在运行的集群中.使用批量加载功能最简单的方法是使用importtsv工具.Importtsv是一个可将数据从TSV文件加载到HBase中的内置工具.它会运行一些MapReduce任务来读取TSV文件中的数据,然后将其输出直接写入HBASE表或HBASE内部数据格式的文件中.
虽然importtsv工具在将文本数据导入HBASE的时候非常有用,但是在有些情况下,比如导入一些其他格式的数据时,你可能必须以编程的方式来生成数据.MapReduce是处理海量数据最有效方法.它可能也是将海量数据加载到Hbase中唯一可行的方法.当然我们也可以使用Mapreduce将数据导入到HBASE中.然而当数据量非常大的时候,MapReduce任务的负载也可能非常重,如果不正确对待,重负载mapreduce任务运行进的吞吐量也可能很差的.
数据迁移是HBASE上一项写密集的任务,除非我们能先生成好一些内部数据文件然后再把它们直接加载到HBASE中去.尽管HBASE的写操作总是非常快,但是如果不正确配置,在迁移的过程中也会经常出现写操作堵塞的情况.写密集任务的另一个问题是:所有写操作可能针对的都是同一台区域服务器,尤其是在将大量数据加载到一个新的HBASE安装的时候,这种情况更容易发生.因为所有负载都集中在一台服务器上,不能均衡分配给集群中的各个服务器,所以写入速度也会明显减慢.
方案的选择
HBase本身提供了很多种数据导入的方式,通常有两种常用方式:
- 使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase
- 另一种方式就是使用HBase原生Client API
这两种方式由于需要频繁的与数据所存储的RegionServer通信,一次性入库大量数据时,特别占用资源,所以都不是最有效的。了解过HBase底层原理的应该都知道,HBase在HDFS中是以HFile文件结构存储的,一个比较高效便捷的方法就是使用 “Bulk Loading”方法直接生成HFile,即HBase提供的HFileOutputFormat类。
一. MapReduce的方式来实现数据导入
我们采用hbase自带的importtsv工具来导入数据,首先要把数据文件上传到hdfs上,然后导入hbase表,该方法只能导入tsv格式的数据,需要先将txt格式转换为tsv格式.
1. 下载数据
本文中使用 “美国国家海洋和大气管理局 气候平均值”的公共数据集合。访问http://www1.ncdc.noaa.gov/pub/data/normals/1981-2010/下载。 在目录 products | hourly 下的小时温度数据。下载hly-temp-10pctl.txt文件。此数据下载巨慢,可以从内网获取,我已放到FTP服务器Hadoop目录中的TestData目录中.
2. 转换数据
用python脚本将txt文件转换为tsv格式文件,生成之后上传到虚拟机linux下的/home/hadoop/data下,python脚本下载链接
1 | python to_tsv_hly.py -f hly-temp-10pctl.txt -t hly-temp-10pctl.tsv |
3.在hdfs上创建数据存放目录
1 | hadoop fs -mkdir /input |
4. 将数据库copy到hdfs数据存放目录中
1 | hadoop@Master:~$ hadoop fs -ls |
5. 在hbase中创建要导入数据的表
1 | hbase(main):001:0> create 'hly_temp', {NAME => 't', VERSIONS => 1} |
6. 执行数据导入
1 | hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns=HBASE_ROW_KEY,t:v01,t:v02,t:v03,t:v04,t:v05,t:v06,t:v07,t:v08,t:v09,t:v10,t:v11,t:v12,t:v13,t:v14,t:v15,t:v16,t:v17,t:v18,t:v19,t:v20,t:v21,t:v22,t:v23,t:v24 hly_temp /input |
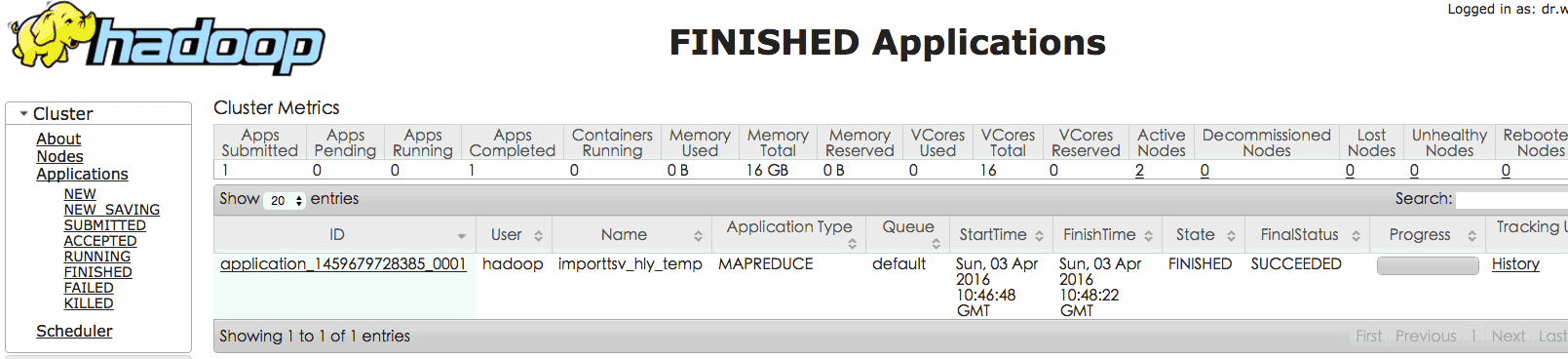
7. 导入后检查数据
1 | hbase(main):002:0> count 'hly_temp' |
二. Put API的方法实现导入
数据迁移最常见的情况可能就是从现有的RDBMS将数据导入到HBASE中了.对于这类任务,可能最简单也最直接的方法就是:用一个客户端来读取数据,然后通过HBASE的PUT API把数据送到HBASE中去.如果需要传输的数据不太多,这种方法非常合适.
1. 准备数据
本文中使用 “美国国家海洋和大气管理局 气候平均值”的公共数据集合。访问http://www1.ncdc.noaa.gov/pub/data/normals/1981-2010/下载。 在目录 products | hourly 下的小时温度数据。下载hly-temp-10pctl.txt文件。此数据下载巨慢,可以从内网获取,我已放到FTP服务器Hadoop目录中的TestData目录中.
在MYSQL数据库中创建一个表 hly_temp_normal
1 | create table hly_temp_normal |
使用insert_gly.py脚本将数据载入到MYSQL数据库中.需要修改insert_gly.py这个脚本中的主机名用户名密码和数据库名称
附带脚本下载
1 | python insert_hly.py -f hly-temp-normal.txt -t hly_temp_normal |