Spark部署模式与作业提交
本文于2412天之前发表,文中内容可能已经过时。
一、作业提交
1.1 spark-submit
Spark所有模式均使用spark-submit命令提交作业,其格式如下:
1 | ./bin/spark-submit \ |
需要注意的是:在集群环境下,application-jar必须能被集群中所有节点都能访问,可以是HDFS上的路径;也可以是本地文件系统路径,如果是本地文件系统路径,则要求集群中每一个机器节点上的相同路径都存在该Jar包。
1.2 deploy-mode
deploy-mode有cluster和client两个可选参数,默认为client。这里以Spark On Yarn模式对两者的区别进行说明 :
- 在cluster模式下,Spark Drvier在应用程序的Master进程内运行,该进程由群集上的YARN管理,提交作业的客户端可以在启动应用程序后关闭;
- 在client模式下,Spark Drvier在提交作业的客户端进程中运行,Master进程仅用于从YARN请求资源。
1.3 master-url
master-url的所有可选参数如下表所示:
| Master URL | Meaning |
|---|---|
local |
使用一个线程本地运行Spark |
local[K] |
使用 K 个 worker 线程本地运行 Spark |
local[K,F] |
使用 K 个 worker 线程本地运行 , 第二个参数为Task的失败重试次数 |
local[*] |
使用与CPU核心数一样的线程数在本地运行Spark |
local[*,F] |
使用与CPU核心数一样的线程数在本地运行Spark 第二个参数为Task的失败重试次数 |
spark://HOST:PORT |
连接至指定的 standalone 集群的 master 节点。端口号默认是 7077。 |
spark://HOST1:PORT1,HOST2:PORT2 |
如果standalone集群采用Zookeeper实现高可用,则必须包含由zookeeper设置的所有master主机地址。 |
mesos://HOST:PORT |
连接至给定的Mesos集群。端口默认是 5050。对于使用了 ZooKeeper 的 Mesos cluster 来说,使用 mesos://zk://...来指定地址,使用 --deploy-mode cluster模式来提交。 |
yarn |
连接至一个 YARN 集群,集群由配置的 HADOOP_CONF_DIR 或者 YARN_CONF_DIR 来决定。使用--deploy-mode参数来配置client 或cluster 模式。 |
下面主要介绍三种常用部署模式及对应的作业提交方式。
二、Local模式
Local模式下提交作业最为简单,不需要进行任何配置,提交命令如下:
1 | # 本地模式提交应用 |
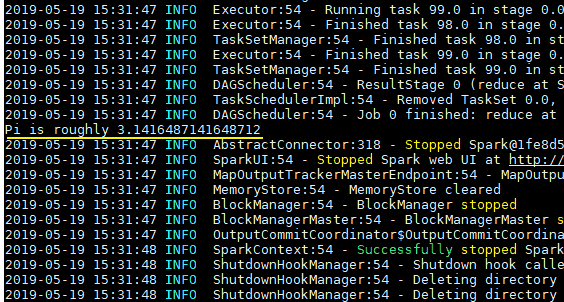
spark-examples_2.11-2.4.0.jar是Spark提供的测试用例包,SparkPi用于计算Pi值,执行结果如下:
三、Standalone模式
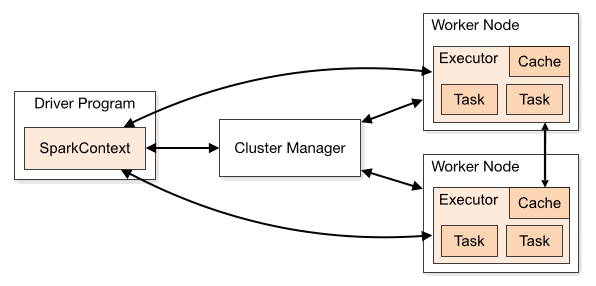
Standalone是Spark提供的一种内置的集群模式,采用内置的资源管理器进行管理。下面按照如图所示演示1个Mater和2个Worker节点的集群配置,这里使用两台主机进行演示:
- hadoop001: 由于只有两台主机,所以hadoop001既是Master节点,也是Worker节点;
- hadoop002 : Worker节点。
3.1 环境配置
首先需要保证Spark已经解压在两台主机的相同路径上。然后进入hadoop001的${SPARK_HOME}/conf/目录下,拷贝配置样本并进行相关配置:
1 | # cp spark-env.sh.template spark-env.sh |
在spark-env.sh中配置JDK的目录,完成后将该配置使用scp命令分发到hadoop002上:
1 | # JDK安装位置 |
3.2 集群配置
在${SPARK_HOME}/conf/目录下,拷贝集群配置样本并进行相关配置:
1 | cp slaves.template slaves |
指定所有Worker节点的主机名:
1 | # A Spark Worker will be started on each of the machines listed below. |
这里需要注意以下三点:
- 主机名与IP地址的映射必须在
/etc/hosts文件中已经配置,否则就直接使用IP地址; - 每个主机名必须独占一行;
- Spark的Master主机是通过SSH访问所有的Worker节点,所以需要预先配置免密登录。
3.3 启动
使用start-all.sh代表启动Master和所有Worker服务。
1 | ./sbin/start-master.sh |
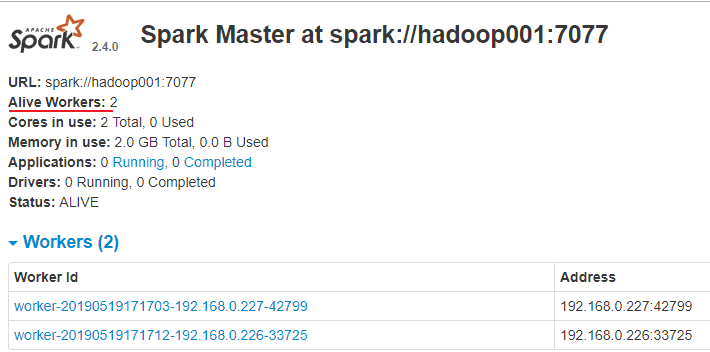
访问8080端口,查看Spark的Web-UI界面,,此时应该显示有两个有效的工作节点:
3.4 提交作业
1 | # 以client模式提交到standalone集群 |
3.5 可选配置
在虚拟机上提交作业时经常出现一个的问题是作业无法申请�足够的资源:```es
Initial job has not accepted any resources;
check your cluster UI to ensure that workers are registered and have sufficient resources
1 |
|
YARN_CONF_DIR=/usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
JDK安装位置
JAVA_HOME=/usr/java/jdk1.8.0_201
1 |
|
start-yarn.sh
start-dfs.sh
1 |
|
以client模式提交到yarn集群
spark-submit
–class org.apache.spark.examples.SparkPi
–master yarn
–deploy-mode client
–executor-memory 2G
–num-executors 10
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar
100
以cluster模式提交到yarn集群
spark-submit
–class org.apache.spark.examples.SparkPi
–master yarn
–deploy-mode cluster
–executor-memory 2G
–num-executors 10
/usr/app/spark-2.4.0-bin-hadoop2.6/examples/jars/spark-examples_2.11-2.4.0.jar
100