Spark SQL JOIN
本文于2411天之前发表,文中内容可能已经过时。
一、 数据准备
本文主要介绍Spark SQL的多表连接,需要预先准备测试数据。分别创建员工和部门的Datafame,并注册为临时视图,代码如下:
1 | val spark = SparkSession.builder().appName("aggregations").master("local[2]").getOrCreate() |
两表的主要字段如下:
1 | emp员工表 |
1 | dept部门表 |
注:emp.json,dept.json可以在本仓库的resources目录进行下载。
二、连接类型
Spark中支持多种连接类型:
- Inner Join : 内连接;
- Full Outer Join : 全外连接;
- Left Outer Join : 左外连接;
- Right Outer Join : 右外连接;
- Left Semi Join : 左半连接;
- Left Anti Join : 左反连接;
- Natural Join : 自然连接;
- Cross (or Cartesian) Join : 交叉(或笛卡尔)连接。
其中内,外连接,笛卡尔积均与普通关系型数据库中的相同,如下图所示:
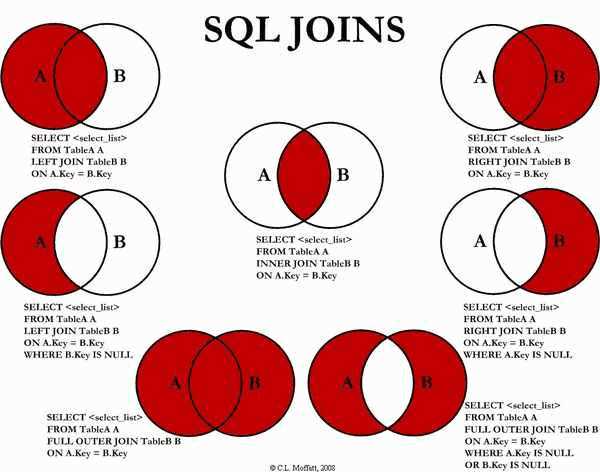
这里解释一下左半连接和左反连接,这两个连接等价于关系型数据库中的IN和NOT IN字句:
1 | -- LEFT SEMI JOIN |
所有连接类型的示例代码如下:
2.1 INNER JOIN
1 | // 1.定义连接表达式 |
2.2 FULL OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "outer").show() |
2.3 LEFT OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "left_outer").show() |
2.4 RIGHT OUTER JOIN
1 | empDF.join(deptDF, joinExpression, "right_outer").show() |
2.5 LEFT SEMI JOIN
1 | empDF.join(deptDF, joinExpression, "left_semi").show() |
2.6 LEFT ANTI JOIN
1 | empDF.join(deptDF, joinExpression, "left_anti").show() |
2.7 CROSS JOIN
1 | empDF.join(deptDF, joinExpression, "cross").show() |
2.8 NATURAL JOIN
自然连接是在两张表中寻找那些数据类型和列名都相同的字段,然后自动地将他们连接起来,并返回所有符合条件的结果。
1 | spark.sql("SELECT * FROM emp NATURAL JOIN dept").show() |
以下是一个自然连接的查询结果,程序自动推断出使用两张表都存在的dept列进行连接,其实际等价于:
1 | spark.sql("SELECT * FROM emp JOIN dept ON emp.deptno = dept.deptno").show() |
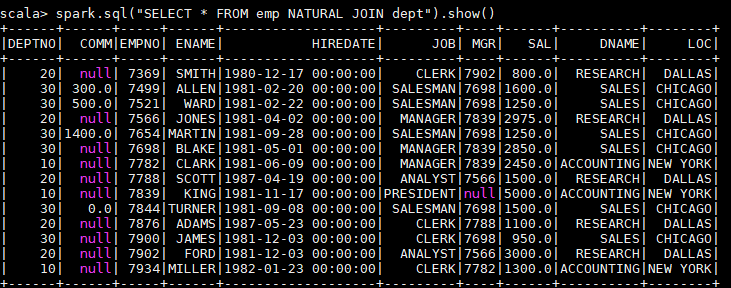
由于自然连接常常会产生不可预期的结果,所以并不推荐使用。
三、连接的执行
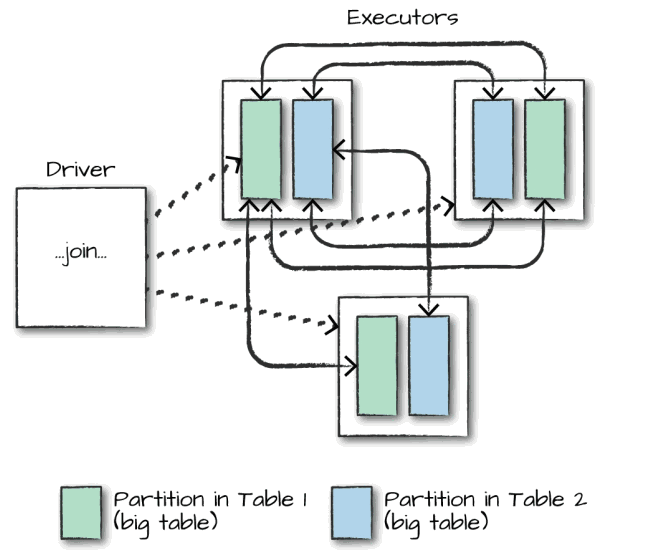
在对大表与大表之间进行连接操作时,通常都会触发Shuffle Join,两表的所有分区节点会进行All-to-All的通讯,这种查询通常比较昂贵,会对网络IO会造成比较大的负担。
而对于大表和小表的连接操作,Spark会在一定程度上进行优化,如果小表的数据量小于Worker Node的内存空间,Spark会考虑将小表的数据广播到每一个Worker Node,在每个工作节点内部执行连接计算,这可以降低网络的IO,但会加大每个Worker Node的CPU负担。
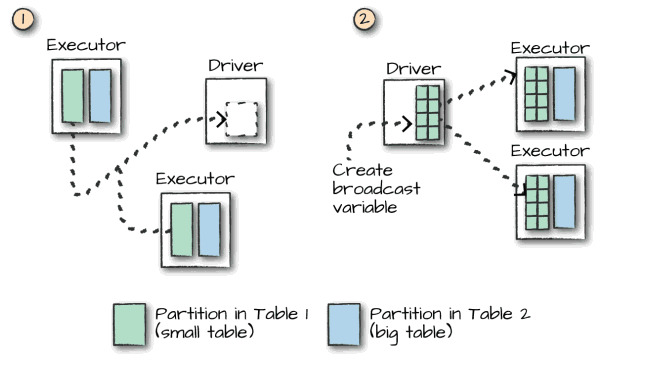
是否采用广播方式进行Join取决于程序内部对小表的判断,如果想明确使用广播方式进行Join,则可以在DataFrame API 中使用broadcast方法指定需要广播的小表:
1 | empDF.join(broadcast(deptDF), joinExpression).show() |
参考资料
- Matei Zaharia, Bill Chambers . Spark: The Definitive Guide[M] . 2018-02