Flink介绍
本文于2402天之前发表,文中内容可能已经过时。
一、Flink介绍
既然有了Apache Spark,为什么还要使用Apache Flink?
因为Flink是一个纯流式计算引擎,而类似于Spark这种微批的引擎,只是Flink流式引擎的一个特例。
Flink是一款分布式的计算引擎,它可以用来做批处理,即处理静态的数据集、历史的数据集;也可以用来做流处理,即实时地处理一些实时数据流,实时地产生数据的结果;也可以用来做一些基于事件的应用,比如说滴滴通过Flink CEP实现实时监测用户及司机的行为流来判断用户或司机的行为是否正当。
使用官网的一句话来介绍 Flink 就是 “Stateful Computations Over Streams”,即数据流上的有状态的计算。这里面有两个关键字,一个是Streams,Flink认为有界数据集是无界数据流的一种特例,所以说有界数据集也是一种数据流,事件流也是一种数据流。Everything is streams,即Flink可以用来处理任何的数据,可以支持批处理、流处理、AI、MachineLearning等等。
另外一个关键词是Stateful,即有状态计算。有状态计算是最近几年来越来越被用户需求的一个功能。举例说明状态的含义,比如说一个网站一天内访问UV数,那么这个UV数便为状态。Flink提供了内置的对状态的一致性的处理,即如果任务发生了Failover,其状态不会丢失、不会被多算少算,同时提供了非常高的性能。
那Flink的受欢迎离不开它身上还有很多的标签,其中包括性能优秀(尤其在流计算领域)、高可扩展性、支持容错,是一种纯内存式的一个计算引擎,做了内存管理方面的大量优化,另外也支持eventime的处理、支持超大状态的Job(在阿里巴巴中作业的state大小超过TB的是非常常见的)、支持exactly-once的处理。
基本特性
流处理特性
- 支持高吞吐、低延迟、高性能的流处理
- 支持带有事件时间的窗口(Window)操作
- 支持有状态计算的Exactly-once语义
- 支持高度灵活的窗口(Window)操作,支持基于time、count、session,以及data-driven的窗口操作
- 支持具有Backpressure功能的持续流模型
- 支持基于轻量级分布式快照(Snapshot)实现的容错
- 一个运行时同时支持Batch on Streaming处理和Streaming处理
- Flink在JVM内部实现了自己的内存管理
- 支持迭代计算
- 支持程序自动优化:避免特定情况下Shuffle、排序等昂贵操作,中间结果有必要进行缓存
API支持
- 对Streaming数据类应用,提供DataStream API
- 对批处理类应用,提供DataSet API(支持Java/Scala)
Libraries支持
- 支持机器学习(FlinkML)
- 支持图分析(Gelly)
- 支持关系数据处理(Table)
- 支持复杂事件处理(CEP)
整合支持
- 支持Flink on YARN
- 支持HDFS
- 支持来自Kafka的输入数据
- 支持Apache HBase
- 支持Hadoop程序
- 支持Tachyon
- 支持ElasticSearch
- 支持RabbitMQ
- 支持Apache Storm
- 支持S3
- 支持XtreemFS
Flink 基石
Apache Flink 之所以能越来越受欢迎,我们认为离不开它最重要的四个基石:Checkpoint、State、Time、Window。
首先是Checkpoint机制,这是Flink最重要的一个特性。Flink基于Chandy-Lamport算法实现了一个分布式的一致性的快照,从而提供了一致性的语义。Chandy-Lamport算法实际上在1985年的时候已经被提出来,但并没有被很广泛的应用,而Flink则把这个算法发扬光大了。Spark最近在实现Continue streaming,Continue streaming的目的是为了降低它处理的延时,其也需要提供这种一致性的语义,最终采用Chandy-Lamport这个算法,说明Chandy-Lamport算法在业界得到了一定的肯定。
提供了一致性的语义之后,Flink为了让用户在编程时能够更轻松、更容易地去管理状态,还提供了一套非常简单明了的State API,包括里面的有ValueState、ListState、MapState,近期添加了BroadcastState,使用State API能够自动享受到这种一致性的语义。
除此之外,Flink还实现了Watermark的机制,能够支持基于事件的时间的处理,或者说基于系统时间的处理,能够容忍数据的延时、容忍数据的迟到、容忍乱序的数据。
另外流计算中一般在对流数据进行操作之前都会先进行开窗,即基于一个什么样的窗口上做这个计算。Flink提供了开箱即用的各种窗口,比如滑动窗口、滚动窗口、会话窗口以及非常灵活的自定义的窗口。
Flink API
Flink分层API主要有三层,如下图:
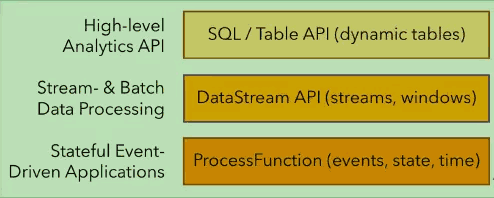
最底层是ProcessFunction,它能够提供非常灵活的功能,它能够访问各种各样的State,用来注册一些timer,利用timer回调的机制能够实现一些基于事件驱动的一些应用。
之上是DataStream API,最上层是SQL/Table API的一种High-level API。
Flink的用途
Flink能用来做什么?回顾一下Flink up前几站的分享,有非常多的嘉宾分享了他们在自己公司里面基于Flink做的一些实践,包括携程、唯品会、饿了么、滴滴、头条等等。他们的应用场景包括实时的机器学习,实时的统计分析,实时的异常监测等等。这些实践案例的共同点就是都用来做实时性的任务。
Flink Title的变化
早期Flink是这样介绍自己的:“我是一个开源的流批统一的计算引擎”,当时跟Spark有点类似。后来Spark改成了一长串的文字,里面有各种各样的形容词:“我是一个分布式的、高性能的、高可用的、高精确的流计算系统”。最近Spark又进行了修改:“我是一个数据流上的有状态的计算”。
通过观察这个变化,可以发现Flink社区重心的变迁,即社区现在主要精力是放在打造它的流计算引擎上。先在流计算领域扎根,领先其他对手几年,然后借助社区的力量壮大社区,再借助社区的力量扩展它的生态。
阿里巴巴Flink是这样介绍自己的:“Flink是一个大数据量处理的统一的引擎”。这个“统一的引擎”包括流处理、批处理、AI、MachineLearning、图计算等等。
总结
Flink 同时支持了流处理和批处理,目前流计算的模型已经相对比较成熟和领先,也经历了各个公司大规模生产的验证。社区在接下来将继续加强流计算方面的性能和功能,包括对 Flink SQL 扩展更丰富的功能和引入更多的优化。另一方面也将加大力量提升批处理、机器学习等生态上的能力。