Flink集群部署
本文于2402天之前发表,文中内容可能已经过时。
独立群集
此页面提供有关如何在静态(但可能是异构)集群上以完全分布式方式运行Flink的说明。
要求
软件要求
Flink可在所有类UNIX环境中运行,例如Linux,Mac OS X和Cygwin(适用于Windows),并期望集群由一个主节点和一个或多个工作节点组成。在开始设置系统之前,请确保在每个节点上安装了以下软件:
- Java 1.8.x或更高版本,
- ssh(必须运行sshd才能使用管理远程组件的Flink脚本)
如果您的集群不满足这些软件要求,则需要安装/升级它。
在所有集群节点上使用无密码SSH和 相同的目录结构将允许您使用我们的脚本来控制所有内容。
JAVA_HOME 配置
Flink要求在JAVA_HOME主节点和所有工作节点上设置环境变量,并指向Java安装的目录。
您可以conf/flink-conf.yaml通过env.java.home键设置此变量。
Flink设置
转到下载页面并获取可立即运行的包。确保选择与您的Hadoop版本匹配的Flink包。如果您不打算使用Hadoop,请选择任何版本。
下载最新版本后,将存档复制到主节点并解压缩:
1 | tar xzf flink-*.tgz |
配置Flink
解压缩系统文件后,需要通过编辑conf / flink-conf.yaml为集群配置Flink 。
将jobmanager.rpc.addressKeys设置为指向主节点。您还应该通过设置jobmanager.heap.mb和taskmanager.heap.mb键来定义允许JVM在每个节点上分配的最大主内存量。
这些值以MB为单位。如果某些工作节点有更多主内存要分配给Flink系统,则可以通过FLINK_TM_HEAP在这些特定节点上设置环境变量来覆盖默认值。
最后,您必须提供集群中所有节点的列表,这些节点将用作工作节点。因此,与HDFS配置类似,编辑文件conf / slaves并输入每个工作节点的IP /主机名。每个工作节点稍后将运行TaskManager。
以下示例说明了具有三个节点(IP地址从10.0.0.1 到10.0.0.3以及主机名master,worker1,worker2)的设置,并显示了配置文件的内容(需要在所有计算机上的相同路径上访问) ):
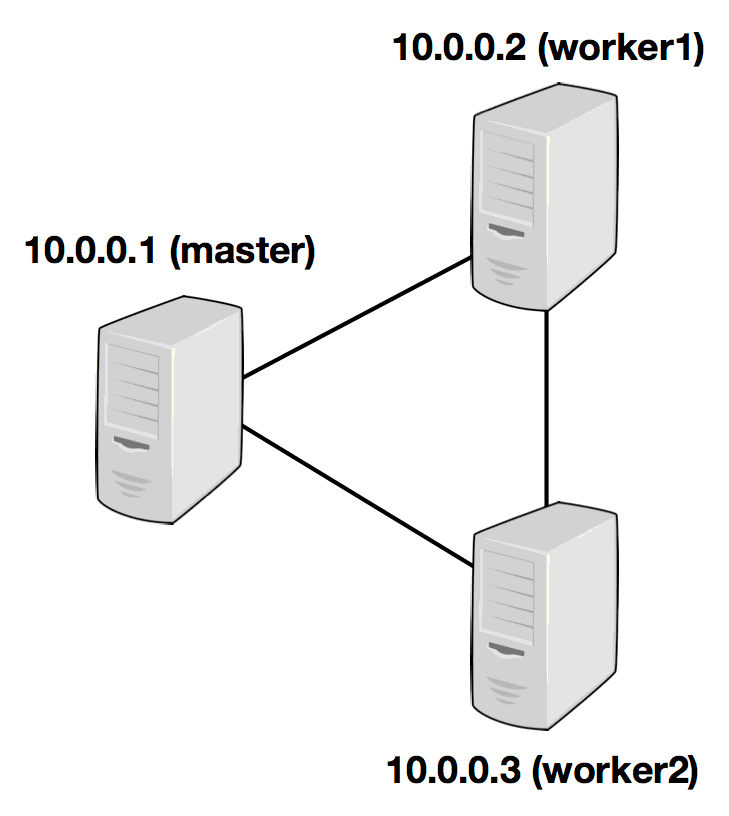
/ path / to / flink / conf / flink-conf.yaml
1 | jobmanager.rpc.address:10.0.0.1 |
/ path / to / flink / conf / slaves
1 | 10.0.0.2 |
Flink目录必须在同一路径下的每个worker上都可用。您可以使用共享NFS目录,也可以将整个Flink目录复制到每个工作节点。
有关详细信息和其他配置选项,请参阅配置页面。
尤其是,
- 每个JobManager(
jobmanager.heap.mb)的可用内存量, - 每个TaskManager(
taskmanager.heap.mb)的可用内存量, - 每台机器的可用CPU数量(
taskmanager.numberOfTaskSlots), - 集群中的CPU总数(
parallelism.default)和 - 临时目录(
taskmanager.tmp.dirs)
是非常重要的配置值。
启动Flink
以下脚本在本地节点上启动JobManager,并通过SSH连接到从属文件中列出的所有工作节点,以在每个节点上启动TaskManager。现在您的Flink系统已启动并正在运行。在本地节点上运行的JobManager现在将接受配置的RPC端口上的作业。
假设您在主节点上并在Flink目录中:
1 | bin/start-cluster.sh |
要停止Flink,还有一个stop-cluster.sh脚本。
将JobManager / TaskManager实例添加到集群
您可以使用bin/jobmanager.sh和bin/taskmanager.sh脚本将JobManager和TaskManager实例添加到正在运行的集群中。
添加JobManager
1 | bin/jobmanager.sh ((start|start-foreground) cluster)|stop|stop-all |
添加TaskManager
1 | bin/taskmanager.sh start|start-foreground|stop|stop-all |
确保在要启动/停止相应实例的主机上调用这些脚本。
YARN设置
快速开始
在YARN上启动长时间运行的Flink集群
与4个TaskManager(每个具有4 GB的Heapspace)启动YARN会话:
1 | # get the hadoop2 package from the Flink download page at |
指定-s每个TaskManager的处理槽数的标志。我们建议将插槽数设置为每台计算机的处理器数。
会话启动后,您可以使用该./bin/flink工具将作业提交到群集。
在YARN上运行Flink作业
1 | # get the hadoop2 package from the Flink download page at |
Flink YARN Session
Apache Hadoop YARN是一个集群资源管理框架。它允许在群集上运行各种分布式应用程序。Flink在其他应用程序旁边的YARN上运行。如果已经有YARN设置,用户不必设置或安装任何东西。
要求
- 至少是Apache Hadoop 2.2
- HDFS(Hadoop分布式文件系统)(或Hadoop支持的其他分布式文件系统)
如果您在使用Flink YARN客户端时遇到麻烦,请查看FAQ部分。
启动Flink会话
请按照以下说明了解如何在YARN群集中启动Flink会话。
会话将启动所有必需的Flink服务(JobManager和TaskManagers),以便您可以将程序提交到群集。请注意,您可以在每个会话中运行多个程序。
下载Flink
从下载页面下载 Hadoop> = 2的Flink软件包。它包含所需的文件。
使用以下方法解压缩包:
1 | tar xvzf flink-1.7-SNAPSHOT-bin-hadoop2.tgz |
启动一个会话
使用以下命令启动会话
1 | ./bin/yarn-session.sh |
此命令将显示以下概述:
1 | Usage: |
请注意,客户要求YARN_CONF_DIR或HADOOP_CONF_DIR环境变量设置为read YARN和HDFS配置。
**示例:**发出以下命令以分配10个TaskManager,每个管理器具有8 GB内存和32个处理插槽:
1 | ./bin/yarn-session.sh -n 10 -tm 8192 -s 32 |
系统将使用配置conf/flink-conf.yaml。如果您想更改某些内容,请按照我们的配置指南 算子操作。
YARN上的Flink将覆盖以下配置参数jobmanager.rpc.address(因为JobManager总是在不同的机器上分配),taskmanager.tmp.dirs(我们使用YARN给出的tmp目录)以及parallelism.default是否已指定插槽数。
如果您不想更改配置文件以设置配置参数,则可以选择通过-D标志传递动态属性。所以你可以这样传递参数:-Dfs.overwrite-files=true -Dtaskmanager.network.memory.min=536346624。
示例调用启动了11个容器(即使只请求了10个容器),因为ApplicationMaster和Job Manager还有一个额外的容器。
在YARN群集中部署Flink后,它将显示JobManager的连接详细信息。
通过停止unix进程(使用CTRL + C)或在客户端输入“stop”来停止YARN会话。
如果群集上有足够的资源,则YARN上的Flink将仅启动所有请求的容器。大多数YARN调度程序考虑了所请求的容器内存,一些帐户也考虑了vcores的数量。默认情况下,vcores的数量等于处理slots(-s)参数。在yarn.containers.vcores允许覆盖vcores的数量与自定义值。为了使此参数起作用,您应该在群集中启用CPU调度。
分离的YARN会话
如果您不想让Flink YARN客户端一直运行,也可以启动分离的 YARN会话。该参数称为-d或--detached。
在这种情况下,Flink YARN客户端将仅向群集提交Flink,然后自行关闭。请注意,在这种情况下,无法使用Flink停止YARN会话。
使用YARN实用程序(yarn application -kill <appId>)来停止YARN会话。
附加到现有会话
使用以下命令启动会话
1 | ./bin/yarn-session.sh |
此命令将显示以下概述:
1 | Usage: |
如前所述,YARN_CONF_DIR或者HADOOP_CONF_DIR必须设置环境变量以读取YARN和HDFS配置。
**示例:**发出以下命令以附加到正在运行的Flink YARN会话application_1463870264508_0029:
1 | ./bin/yarn-session.sh -id application_1463870264508_0029 |
附加到正在运行的会话使用YARN ResourceManager来确定JobManagerRPC端口。
通过停止unix进程(使用CTRL + C)或在客户端输入“stop”来停止YARN会话。
向Flink提交工作
使用以下命令将Flink程序提交到YARN群集:
1 | ./bin/flink |
请参阅命令行客户端的文档。
该命令将显示如下的帮助菜单:
1 | [...] |
使用运行 算子操作将作业提交给YARN。客户端能够确定JobManager的地址。在极少数问题的情况下,您还可以使用-m参数传递JobManager地址。JobManager地址在YARN控制台中可见。
例
1 | wget -O LICENSE-2.0.txt http://www.apache.org/licenses/LICENSE-2.0.txt |
如果出现以下错误,请确保所有TaskManagers都已启动:
1 | Exception in thread "main" org.apache.flink.compiler.CompilerException: |
您可以在JobManager Web界面中检查TaskManagers的数量。该接口的地址打印在YARN会话控制台中。
如果一分钟后TaskManagers没有出现,您应该使用日志文件调查问题。
在YARN上运行单个Flink作业
上面的文档描述了如何在Hadoop YARN环境中启动Flink集群。也可以仅在执行单个作业时在YARN中启动Flink。
请注意,客户端然后期望设置-yn值(TaskManagers的数量)。
例:
1 | ./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar |
YARN会话的命令行选项也可用于该./bin/flink工具。它们以yor或yarn(对于长参数选项)作为前缀。
注意:您可以通过设置环境变量为每个作业使用不同的配置目录FLINK_CONF_DIR。要使用此副本,请conf从Flink分发中复制目录,并根据每个作业修改日志记录设置。
注意:可以-m yarn-cluster与分离的YARN提交(-yd)组合以“触发并忘记”到YARN群集的Flink作业。在这种情况下,您的应用程序将不会从ExecutionEnvironment.execute()调用获得任何累加器结果或异常!
用户jar和Classpath
默认情况下,Flink将在运行单个作业时将用户jar包含到系统类路径中。可以使用yarn.per-job-cluster.include-user-jar参数控制此行为。
将此设置为DISABLED Flink时,将在用户类路径中包含jar。
可以通过将参数设置为以下之一来控制类路径中的user-jar位置:
ORDER:(默认)根据字典顺序将jar添加到系统类路径。FIRST:将jar添加到系统类路径的开头。LAST:将jar添加到系统类路径的末尾。
Flink在YARN上的恢复行为
Flink的YARN客户端具有以下配置参数来控制容器故障时的行为方式。可以conf/flink-conf.yaml使用-D参数从启动YARN会话时或在启动YARN会话时设置这些参数。
yarn.reallocate-failed:此参数控制Flink是否应重新分配失败的TaskManager容器。默认值:trueyarn.maximum-failed-containers:ApplicationMaster在YARN会话失败之前接受的最大失败容器数。默认值:最初请求的TaskManagers(-n)的数量。yarn.application-attempts:ApplicationMaster(+其TaskManager容器)尝试的数量。如果此值设置为1(默认值),则当Application master失败时,整个YARN会话将失败。较高的值指定YARN重新启动ApplicationMaster的次数。
调试失败的YARN会话
Flink YARN会话部署失败的原因有很多。配置错误的Hadoop设置(HDFS权限,YARN配置),版本不兼容(在Cloudera Hadoop上运行Flink与vanilla Hadoop依赖关系)或其他错误。
日志文件
如果Flink YARN会话在部署期间失败,则用户必须依赖Hadoop YARN的日志记录函数。最有用的函数是YARN日志聚合。要启用它,用户必须将yarn.log-aggregation-enable属性设置true为yarn-site.xml文件。启用后,用户可以使用以下命令检索(失败的)YARN会话的所有日志文件。
1 | yarn logs -applicationId <application ID> |
请注意,会话结束后需要几秒钟才会显示日志。
YARN客户端控制台和Web界面
如果在运行期间发生错误,Flink YARN客户端还会在终端中打印错误消息(例如,如果TaskManager在一段时间后停止工作)。
除此之外,还有YARN Resource Manager Web界面(默认情况下在端口8088上)。资源管理器Web界面的端口由yarn.resourcemanager.webapp.address配置值确定。
它允许访问日志文件以运行YARN应用程序,并显示失败应用程序的诊断信息。
为特定的Hadoop版本构建YARN客户端
使用Hortonworks,Cloudera或MapR等公司的Hadoop发行版的用户可能必须针对其特定版本的Hadoop(HDFS)和YARN构建Flink。
在防火墙后面的YARN上运行Flink
某些YARN群集使用防火墙来控制群集与网络其余部分之间的网络流量。在这些设置中,Flink作业只能从群集网络内(防火墙后面)提交到YARN会话。如果这对生产使用不可行,Flink允许为所有相关服务配置端口范围。通过配置这些范围,用户还可以通过防火墙向Flink提交作业。
目前,提交工作需要两项服务:
- JobManager(YARN中的ApplicationMaster)
- 在JobManager中运行的BlobServer。
向Flink提交作业时,BlobServer会将带有用户代码的jar分发给所有工作节点(TaskManagers)。JobManager自己接收作业并触发执行。
用于指定端口的两个配置参数如下:
yarn.application-master.portblob.server.port
这两个配置选项接受单个端口(例如:“50010”),范围(“50000-50025”)或两者的组合(“50010,50011,50020-50025,50050-50075”)。
(Hadoop使用类似的机制,在那里调用配置参数yarn.app.mapreduce.am.job.client.port-range。)
背景/内部
本节简要介绍Flink和YARN如何交互。

YARN客户端需要访问Hadoop配置以连接到YARN资源管理器和HDFS。它使用以下策略确定Hadoop配置:
- 测试是否
YARN_CONF_DIR,HADOOP_CONF_DIR或HADOOP_CONF_PATH设置(按顺序)。如果设置了其中一个变量,则使用它们来读取配置。 - 如果上述策略失败(在正确的YARN设置中不应该这样),则客户端正在使用
HADOOP_HOME环境变量。如果已设置,则客户端尝试访问$HADOOP_HOME/etc/hadoop(Hadoop 2)和$HADOOP_HOME/conf(Hadoop 1)。
启动新的Flink YARN会话时,客户端首先检查所请求的资源(容器和内存)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。
该JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
之后,AM开始为Flink的TaskManagers分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,即可建立Flink并准备接受作业。