Flink SQL编程
本文于2398天之前发表,文中内容可能已经过时。
SQL是数据处理中使用最广泛的语言。它允许用户简明扼要地声明他们的业务逻辑。大数据批计算使用SQL很常见,但是支持SQL的实时计算并不多。Apache Flink是一款同时支持批和流计算的引擎,Flink SQL的实现完全遵循ANSI SQL标准,这是它和其他流处理框架(例如Kafka和Spark)在DSL上的一个重要的不同。
Flink SQL是什么?
声明式API
Flink最高层的API,易于使用
自动优化
屏蔽State的复杂性, 自动做到最优处理
- 流批统一
—样的SQL,—样的结果
- 应用广泛
ETL,统计分析, 实时报表,实时风控
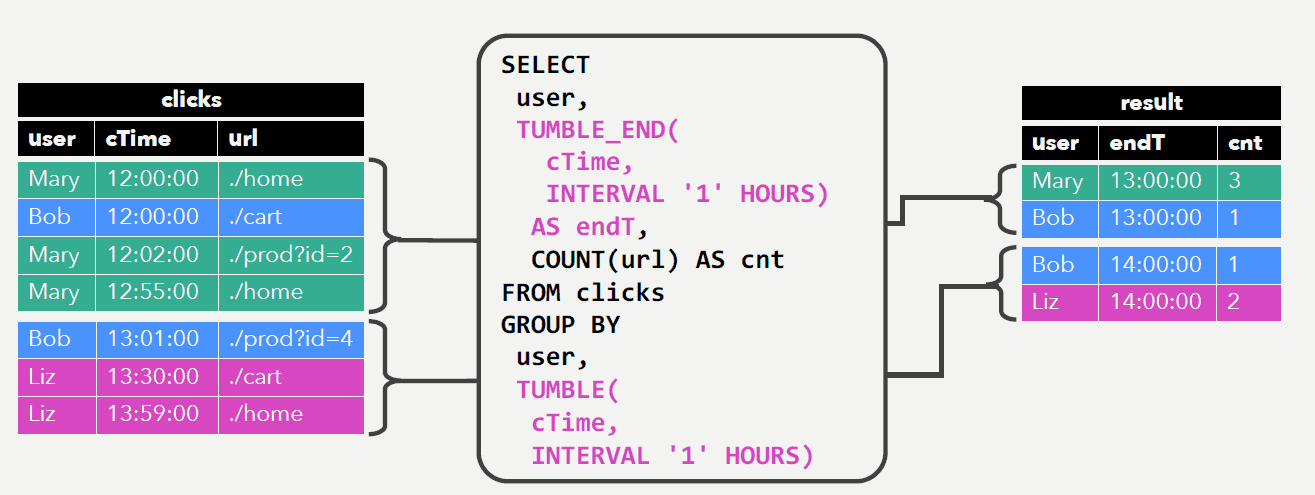
Window Aggregation
Window Aggregation
每小时每个用户点击的次数
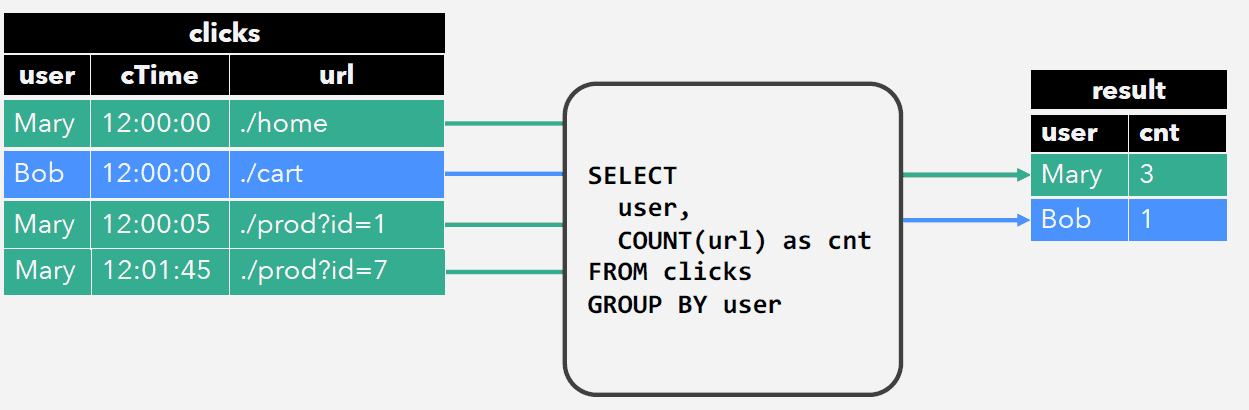
Group Aggregation
从历史到现在每个用户点击的次数
| Window Aggregation | Group Aggregation | |
|---|---|---|
| 输出模式 | 按时输出 | 提前输出 |
| 输出量 | 只输出次结果 | Per key输出N个结果(Sink压力) |
| 输出流 | Append Stream | Update Stream |
| 状态清理 | 及时清理过期数据 | 状态无限增长 |
| Sink | 均可 | 可更新的结果表(Hbase, MySQL) |
状态无限增长,解决方法:
精确性<–>状态大小
State TTL Config
1 | streamQueryConfig |
Demo Time https://github.com/ververica/sql-training/
支持的语法
Flink使用Apache Calcite解析SQL ,它支持标准的ANSI SQL。Flink不支持DDL语句。
以下BNF语法描述了批处理和流式查询中支持的SQL函数的超集。“ 算子”部分显示支持的函数的示例,并指示仅批处理或流式查询支持哪些函数。
1 | insert: |
Flink SQL对类似于Java标识符(表,属性,函数名)使用词法策略:
- 无论是否引用标识符,都会保存标识符的大小写。
- 之后,标识符区分大小写。
- 与Java不同,反向标记允许标识符包含非字母数字字符(例如
"SELECT a ASmy fieldFROM t")。
算子
Scan,Projection和过滤
| Operation | 描述 |
|---|---|
| Scan/Select/As 批量 流 | SELECT * FROM Orders SELECT a, c AS d FROM Orders |
| Where / Filter Batch Streaming | SELECT * FROM Orders WHERE b = 'red' SELECT * FROM Orders WHERE a % 2 = 0 |
| User-defined Scalar Functions (Scalar UDF) 批量 流 | UDF必须在TableEnvironment中注册。SELECT PRETTY_PRINT(user) FROM Orders |
聚合
| Operation | 描述 |
|---|---|
| GroupBy聚合 批处理 流 结果更新 | **注意:**流表上的GroupBy会生成更新结果。SELECT a, SUM(b) as d FROM Orders GROUP BY a |
| GroupBy窗口聚合 批量 流 | 使用组窗口计算每个组的单个结果行。SELECT user, SUM(amount) FROM Orders GROUP BY TUMBLE(rowtime, INTERVAL '1' DAY), user |
| Over Window聚合 流 | **注意:**必须在同一窗口中定义所有聚合,即相同的分区,排序和范围。目前,仅支持具有PRREDING(UNBOUNDED和有界)到CURRENT ROW范围的窗口。尚不支持使用FOLLOWING的范围。必须在单个时间属性上指定ORDER BYSELECT COUNT(amount) OVER ( PARTITION BY user ORDER BY proctime ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) FROM Orders SELECT COUNT(amount) OVER w, SUM(amount) OVER w FROM Orders WINDOW w AS ( PARTITION BY user ORDER BY proctime ROWS BETWEEN 2 PRECEDING AND CURRENT ROW) |
| Distinct 批量 流 结果更新 | SELECT DISTINCT users FROM Orders**注意:**对于流式查询,计算查询结果所需的状态可能会无限增长,具体取决于不同字段的数量。请提供具有有效保存间隔的查询配置,以防止过大的状态。 |
| 分组集,汇总,多维数据集 批量 | SELECT SUM(amount) FROM Orders GROUP BY GROUPING SETS ((user), (product)) |
| Having 批量 流 | SELECT SUM(amount) FROM Orders GROUP BY users HAVING SUM(amount) > 50 |
| 用户定义的聚合函数(UDAGG) 批量 流 | UDAGG必须在TableEnvironment中注册。SELECT MyAggregate(amount) FROM Orders GROUP BY users |
Join
| Operation | 描述 |
|---|---|
| 内部Equi-join 批量 流 | 目前,仅支持等连接,即具有至少一个带有等式谓词的连接条件的连接。不支持任意交叉或theta连接。**注意:**连接顺序未优化。表按照FROM子句中指定的顺序连接。确保以不产生交叉连接(笛卡尔积)的顺序指定表,这些表不受支持并且会导致查询失败。SELECT * FROM Orders INNER JOIN Product ON Orders.productId = Product.id**注意:**对于流式查询,计算查询结果所需的状态可能会无限增长,具体取决于不同输入行的数量。请提供具有有效保存间隔的查询配置,以防止过大的状态。 |
| 外部Equi-join 批量 流 结果更新 | 目前,仅支持等连接,即具有至少一个带有等式谓词的连接条件的连接。不支持任意交叉或theta连接。**注意:**连接顺序未优化。表按照FROM子句中指定的顺序连接。确保以不产生交叉连接(笛卡尔积)的顺序指定表,这些表不受支持并且会导致查询失败。SELECT * FROM Orders LEFT JOIN Product ON Orders.productId = Product.id SELECT * FROM Orders RIGHT JOIN Product ON Orders.productId = Product.id SELECT * FROM Orders FULL OUTER JOIN Product ON Orders.productId = Product.id**注意:**对于流式查询,计算查询结果所需的状态可能会无限增长,具体取决于不同输入行的数量。请提供具有有效保存间隔的查询配置,以防止过大的状态。 |
| Time-windowed Join 批量 流 | **注意:**时间窗口连接是可以以流方式处理的常规连接的子集。时间窗口连接需要至少一个等连接谓词和一个限制双方时间的连接条件。这样的条件可以由两个适当的范围谓词(<, <=, >=, >),BETWEEN谓词或单个等式谓词来定义,其比较两个输入表的相同类型的时间属性(即,处理时间或事件时间)。例如,以下谓词是有效的窗口连接条件:ltime = rtime``ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE``ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND``SELECT * FROM Orders o, Shipments s WHERE o.id = s.orderId AND o.ordertime BETWEEN s.shiptime - INTERVAL '4' HOUR AND s.shiptime如果订单在收到订单后四小时发货,上面的示例将关联所有订单及其相应的货件。 |
| 将数组扩展为关系 Batch Streaming | 尚未支持UnANDing WITH ORDINALITY。SELECT users, tag FROM Orders CROSS JOIN UNNEST(tags) AS t (tag) |
| 关联用户定义的表函数(UDTF) 批量 流 | UDTF必须在TableEnvironment中注册。内部联接SELECT users, tag FROM Orders, LATERAL TABLE(unnest_udtf(tags)) t AS tag左外连接SELECT users, tag FROM Orders LEFT JOIN LATERAL TABLE(unnest_udtf(tags)) t AS tag ON TRUE**注意:**目前,TRUE对于横向表,只支持左外连接的谓词作为谓词。 |
设置 算子操作
| Operation | 描述 |
|---|---|
| Union 批次 | SELECT * FROM ( (SELECT user FROM Orders WHERE a % 2 = 0) UNION (SELECT user FROM Orders WHERE b = 0) ) |
| UnionAll Batch Streaming | SELECT * FROM ( (SELECT user FROM Orders WHERE a % 2 = 0) UNION ALL (SELECT user FROM Orders WHERE b = 0) ) |
| Intersect/ Except****批量 | SELECT * FROM ( (SELECT user FROM Orders WHERE a % 2 = 0) INTERSECT (SELECT user FROM Orders WHERE b = 0) )``SELECT * FROM ( (SELECT user FROM Orders WHERE a % 2 = 0) EXCEPT (SELECT user FROM Orders WHERE b = 0) ) |
| IN 批量 流中 | 如果表达式存在于给定的表子查询中,则返回true。子查询表必须包含一列。此列必须与表达式具有相同的数据类型。SELECT user, amount FROM Orders WHERE product IN ( SELECT product FROM NewProducts )**注意:**对于流式查询, 算子操作将在连接和组 算子操作中重写。计算查询结果所需的状态可能会无限增长,具体取决于不同输入行的数量。请提供具有有效保存间隔的查询配置,以防止过大的状态。 |
| Exists 批量 流 | 如果子查询至少返回一行,则返回true。仅在可以在连接和组 算子操作中重写 算子操作时才支持。SELECT user, amount FROM Orders WHERE product EXISTS ( SELECT product FROM NewProducts )**注意:**对于流式查询, 算子操作将在连接和组 算子操作中重写。计算查询结果所需的状态可能会无限增长,具体取决于不同输入行的数量。请提供具有有效保存间隔的查询配置,以防止过大的状态。 |
OrderBy&Limit
| Operation | 描述 |
|---|---|
| Order By 批量 流 | **注意:**流式查询的结果必须主要按升序时间属性排序。支持其他排序属性。SELECT * FROM Orders ORDER BY orderTime |
| Limit 批次 | SELECT * FROM Orders LIMIT 3 |
Insert
| Operation | 描述 |
|---|---|
| Insert 批量 流处理 | 输出表必须在TableEnvironment中注册。此外,已注册表的模式必须与查询的模式匹配。INSERT INTO OutputTable SELECT users, tag FROM Orders |
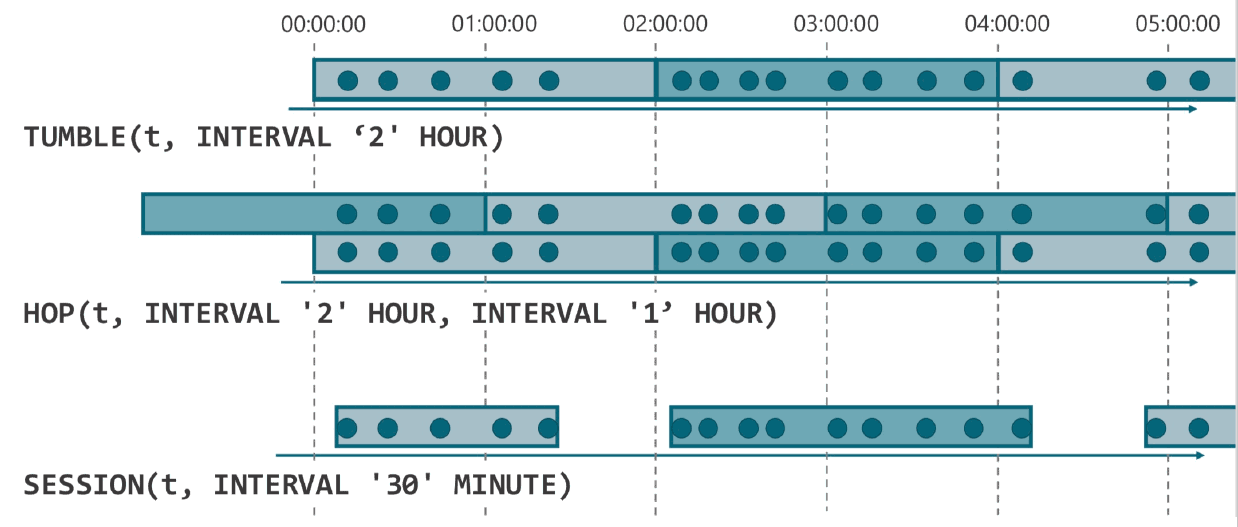
GroupWindows
组窗口在GROUP BYSQL查询的子句中定义。就像具有常规GROUP BY子句的查询一样,带有GROUP BY包含组窗口函数的子句的查询会为每个组计算单个结果行。批处理和流表上的SQL支持以下组窗口函数。
| 组窗口函数 | 描述 |
|---|---|
TUMBLE(time_attr, interval) |
定义翻滚时间窗口。翻滚时间窗口将行分配给具有固定持续时间(interval)的非重叠连续窗口。例如,5分钟的翻滚窗口以5分钟为间隔对行进行分组。可以在事件时间(流+批处理)或处理时间(流)上定义翻滚窗口。 |
HOP(time_attr, interval, interval) |
定义跳跃时间窗口(在 Table API中称为滑动窗口)。跳跃时间窗口具有固定的持续时间(第二interval参数)并且按指定的跳跃间隔(第一interval参数)跳跃。如果跳跃间隔小于窗口大小,则跳跃窗口重叠。因此,可以将行分配给多个窗口。例如,15分钟大小和5分钟跳跃间隔的跳跃窗口将每行分配给3个不同的15分钟大小的窗口,这些窗口以5分钟的间隔进行评估。可以在事件时间(流+批处理)或处理时间(流)上定义跳跃窗口。 |
SESSION(time_attr, interval) |
定义会话时间窗口。会话时间窗口没有固定的持续时间,但它们的界限由interval不活动时间定义,即如果在定义的间隙期间没有出现事件,则会话窗口关闭。例如,如果在30分钟不活动后观察到一行,则会开始一个30分钟间隙的会话窗口(否则该行将被添加到现有窗口中),如果在30分钟内未添加任何行,则会关闭。会话窗口可以在事件时间(流+批处理)或处理时间(流)上工作。 |
时间属性
对于流表的SQL查询,time_attr组窗口函数的参数必须引用指定行的处理时间或事件时间的有效时间属性。
对于批处理表上的SQL,time_attr组窗口函数的参数必须是类型的属性TIMESTAMP。
选择组窗口开始和结束时间戳
可以使用以下辅助函数选择组窗口的开始和结束时间戳以及时间属性:
| 辅助函数 | 描述 |
|---|---|
TUMBLE_START(time_attr, interval) HOP_START(time_attr, interval, interval) SESSION_START(time_attr, interval) |
返回相应的翻滚,跳跃或会话窗口的包含下限的时间戳。 |
TUMBLE_END(time_attr, interval) HOP_END(time_attr, interval, interval) SESSION_END(time_attr, interval) |
返回相应的翻滚,跳跃或会话窗口的独占上限的时间戳。**注意:*独占上限时间戳不能*在后续基于时间的 算子操作中用作行时属性,例如时间窗口连接和组窗口或窗口聚合。 |
TUMBLE_ROWTIME(time_attr, interval) HOP_ROWTIME(time_attr, interval, interval) SESSION_ROWTIME(time_attr, interval) |
返回相应的翻滚,跳跃或会话窗口的包含上限的时间戳。结果属性是rowtime属性,可用于后续基于时间的 算子操作,例如时间窗口连接和组窗口或窗口聚合。 |
TUMBLE_PROCTIME(time_attr, interval) HOP_PROCTIME(time_attr, interval, interval) SESSION_PROCTIME(time_attr, interval) |
返回proctime属性,该属性可用于后续基于时间的 算子操作,例如时间窗口连接和组窗口或窗口聚合。 |
*注意:*必须使用与GROUP BY子句中的组窗口函数完全相同的参数调用辅助函数。
SQL编程实例
Ride:表
1 | rideld: BIGINT //行为ID (包含两条记录,一条入一条出) |
需求1 (filter)
出现在纽约的行车记录。
1 | CREATE VIEW nyc_view AS |
需求2 (Group Agg)
计算搭载每种乘客数量的行车事件数。
也就是搭载1个乘客的行车数、搭载2个乘客的行车数…
1 | SELECT psgCnt, COUNT(*) AS ent |
需求3 (Window Agg)
为了持续地监测城市的交通流量,计算每个区域每5分钟的进入的车辆数。
我们只关心纽约的区域交通情况,并且只关心至少有5辆车子进入的区域。
1 | SELECT |
需求4 (write to Kafka)
将每10分钟的搭乘的乘客数写入Kafka
结果表:Sink_TenMinPsgCnts
1 | INSERT INTO Sink_TenMinPsgCnts |
需求5 (write to ES)
从每个区域出发的行车数,写入到ES。
结果表:Si nk_AreaCnts
1 | INSERT INTO Sink_AreaCnts |