从零开始学习知识图谱 之 六.电影知识图谱构建 6.将关系型数据存入图数据库Neo4j
本文于2312天之前发表,文中内容可能已经过时。
一. 简介
图数据库是基于图论实现的一种新型NoSQL数据库。它的数据数据存储结构和数据的查询方式都是以图论为基础的。图论中图的节本元素为节点和边,对应于图数据库中的节点和关系。
Neo4j 是由 Java 实现的开源 NoSQL 图数据库,它提供了完整的数据库特性,包括ADID事务的支持、集群的支持、备份与故障转移等。
Cypher 是一种声明式的图数据库查询语言,能高效地查询和更新图数据。Cypher 语句可分为三类,包括读语句、写语句和通用语句:
- 读语句: MATCH、OPTIONAL MATCH、WHERE、START、AGGREGATION、LOAD CSV。
- 写语句: CREATE、MERGE、SET、DELETE、REMOVE、FOREACH、CREATE UNIQUE。
- 通用语句: RETURN、ORDER BY、LIMIT、SKIP、WITH、UNWIND、UNION、CALL。
熟悉SQL语句的应该能根据上面这些猜出大概用途了。
本教程的项目代码放在github上,下载地址为《从零开始学习知识图谱》项目源代码 。
二. 环境准备
1. 操作系统
支持操作系统:windows、macOS、Linux。为了方便大家搭建开发环境,笔者尽可能在windows下构建,系列篇未特意说明时操作系统都是windows。Linux安装可以参考VirtualBox虚拟机安装Ubuntu或VirtualBox虚拟机安装CentOS8进行安装。
2. jdk
安装参见windows系统安装JDK
3. 安装Neo4j
1) 下载
下载页面:https://neo4j.com/download-center/ ,下载Neo4j Community Edition Windows版 。通过下载页点击下载反应极慢而且下载也极慢。建议在Neo4j国内的下载地址Neo4j 产品下载上下载。
2)安装
需要jdk环境支持。
a. 先解压放在自己想放的位置,C:\my\neo4j
Neo4j应用程序有如下主要的目录结构:
- bin目录:用于存储Neo4j的可执行程序;
- conf目录:用于控制Neo4j启动的配置文件;
- data目录:用于存储核心数据库文件;
- plugins目录:用于存储Neo4j的插件;
b. 创建系统环境变量
创建主目录环境变量NEO4J_HOME,并把主目录设置为变量值。win10系统环境变量设置步骤
NEO4J_HOME = C:\my\neo4j
Path = %NEO4J_HOME%\bin
c. 启动并验证是否成功
CMD管理员身份运行neo4j.bat console
一定要以管理员身份进入CMD,否则会出现警告。警告: This command does not appear to be running with administrative rights. Some commands may fail e.g. Start/Stop
1 | C:\Users\mmm>neo4j console |
3)配置成Windows服务
可以跳过此步。
也可以把Neo4j配置成Windows服务,不推荐。
Neo4j也可以作为Windows服务运行。使用安装服务bin\neo4j install-service,然后使用进行启动bin\neo4j start。
对于可用的命令bin\neo4j是:help,start,stop,restart,status,install-service,uninstall-service,和update-service。
4)打开Neo4j集成的浏览器
可以跳过此步。
a. Neo4j浏览器
Neo4j服务器具有一个集成的浏览器,在一个运行的服务器实例上访问 “http://localhost:7474/”,打开浏览器,显示启动页面 。
默认的host是bolt://localhost:7687,默认的用户是neo4j,其默认的密码是:neo4j,第一次成功登陆到Neo4j服务器之后,需要重置密码。
访问Graph Database需要输入身份验证,Host是Bolt协议标识的主机。
b. 在Neo4j浏览器中创建节点和关系
示例,编写Cypher命令,创建两个节点和两个关系:
1 | CREATE (n:Person { name: 'Andres', title: 'Developer' }) return n; |
在$ 命令行中,编写Cypher脚本代码,点击Play按钮,点击创建第一个节点,
在第一个节点创建之后,在Graph模式下,能够看到创建的图形,继续编写Cypher脚本,创建其他节点和关系
5)快速清除Neo4j数据库数据
a. 关闭Neo4j服务器进程
检查服务器进程是否启动,如启动,可通过kill -9或其它方式杀掉服务器进程。
b. 删除graph.db数据库文件
找到
c. 重新启动Neo4j服务器
通过bin目录下执行neo4j.bat console命令启动Neo4j
Neo4j在启动过程中,会发现graph.db文件夹丢失,重新建立新数据,从而完成清空任务。
d. 连接Neo4j Browser重设密码
由于数据库重新建立,需要重新设置数据库用户名和密码。可通过连接启动后的Neo4j Browser重新设置,也可通过命令行等进行设置。
通过以上四个步骤,即完成了Neo4j数据的清空。
三. MYSQL 数据的导出
1. 说明
MYSQl 支持将查询结果直接导出为 CSV 文本格式,在使用 SELECT 语句查询数据时,在语句后面加上导出指令即可,格式如下:
- into outfile < 导出的目录和文件名>: 指定导出的目录和文件名。
- fields terminated by <字段间分隔符>:定义字段间的分隔符。
- optionally enclosed by <字段包围符>:定义包围字段的字符(数值型字段无效)。
- lines terminated by <行间分隔符>:定义每行的分隔符。
下面我们基于从零开始学习知识图谱(一)中建立的互动百科数据库,导出 actor 表中所有数据
其中 actor 表的属性为:
1 |
2. 导出表
我们导出获得 actor 表、movie 表、电影类型 genre 表、actor-movie表、 movie-genre 表中的数据:
建议使用MySQL Workbench执行下面脚本,mysql 中导出表的代码为:
1 | SELECT * FROM actor into outfile 'C:/ProgramData/MySQL/MySQL Server 8.0/Uploads/hudong_actor.csv' fields terminated by ',' optionally enclosed by '"' lines terminated by '\r\n'; |
3. 导出可能出现的问题及解决
问题:MySQL导出文件时,遇到报错“The MySQL server is running with the –secure-file-priv option so it cannot execute this statement” 。
解决:MySQL Workbench执行show variables like '%secure%'; 返回结果 secure_file_priv=C:\ProgramData\MySQL\MySQL Server 8.0\Uploads\,把outfile中路径改成secure_file_priv值,注意\要换成/。
4. 导出数据校验
hudong_actor.csv 的第一行数据为:
1 | 1,"周星驰(Stephen Chow),1962年6月22日生于香港,华语喜剧演员、导演、编剧、监制、制片人、出品人。1980年成为丽的电视特约演员,开始出道。1988年初涉影坛,后相继主演《唐伯虎点秋香》、《大话西游》等,自编自导自演《国产凌凌漆》、《食神》、《功夫》等多部影片,6度打破香港电影票房纪录,并获得8个香港电影年度票房冠军,创下打破票房纪录次数及获得年度票房冠军次数的纪录。2003年当选《时代周刊》“年度风云人物”,并成为“亚洲英雄”的封面人物。2004年《功夫》创下数十个国家和地区的华语电影票房纪录,并被《时代周刊》评为“2005年十大佳片”之一。2013年导演的《西游·降魔篇》破23项华语电影票房纪录,全球票房达2.18亿美元,刷新华语电影全球票房纪录。2014年执导的科幻电影《美人鱼》开拍,该片已于2016年2月8日上映,上映19天累计票房超过30亿,刷新了华语电影票房记录。2017年1月28日,担任监制、编剧的古装喜剧片《西游伏妖篇》上映。编辑摘要","周星驰","Stephen Chow","中国","巨蟹座","香港","None","唐伯虎点秋香、功夫","获得两届香港电影金像奖最佳影片 第21届香港电影金像奖最佳导演 第42届台湾电影金马奖最佳导演","创办星辉电影公司和上市比高集团" |
四. 将数据导入到Neo4j
1. 准备工作
- neo4j load csv 的使用
文件URL将相对于dbms.directories.import目录解析。例如,一个文件的URL通常会看起来像file:///myfile.csv或file:///myproject/myfile.csv。
打开dbms.directories.import
1 | dbms.directories.import=import |
从而得知file:///根路径。我的是C:\my\neo4j\import
- 移动文件
把mysql导出的csv文件全部移动到C:\my\neo4j\import
2. 导入实体
我们首先将 actor 实体导入到 Neo4j 中,对应文件为 hudong_actor.csv:
打开Neo4j浏览器: http://localhost:7474/ ,在它页面命令行(位置在首页右边上面)里,执行下面命令:
1 | LOAD CSV FROM 'file:///hudong_actor.csv' AS line CREATE (:Actor { actor_id: line[0], actor_bio: line[1], actor_chName: line[2], actor_foreName: line[3],actor_nationality: line[4], actor_constellation: line[5], actor_birthPlace: line[6], actor_birthDay: line[7], actor_repWorks: line[8], actor_achiem: line[9], actor_brokerage: line[10] }) |
其中 LOAD CSV FROM “file-url” AS line 是将指定路径下的 CSV 文件读取出来,”file-url” 就是文件的地址,它可以是本地文件路径也可以是网址。需要注意的是,对于本地文件,该路径默认为 import 文件夹,要想读取其他文件夹下的文件,需要修改配置文件才可以。
上面命令在读取 CSV 文件后,调用 CREATE 命令创建了对应的节点,也就是用圆括号 (:Actor {… line[10]}) 包起来的部分。节点的标签为 :Actor,节点的属性为 花括号{} 包起来的部分。包含 actor_id、actor_bio 等。属性的值从 line 中读取,line[0] 表示 CSV 文件中的第一列,其他列以此类推。
命令行输入下面命令,查看导入结果:
1 | MATCH (n:Actor) RETURN n LIMIT 25; |
通过上面的命令我们就创建了 actor 实体的节点,下面我们按照类似的命令分别创建 movie 的节点和 genre 节点:
1 | LOAD CSV FROM 'file:///hudong_movie.csv' AS line CREATE (:Movie { movie_id: line[0], movie_bio: line[1], movie_chName: line[2], movie_foreName: line[3],movie_prodTime: line[4], movie_prodCompany: line[5], movie_director: line[6], movie_screenwriter: line[7], movie_genre: line[8], movie_star: line[9], movie_length: line[10], movie_rekeaseTime: line[11], movie_language: line[12], movie_achiem: line[13] }); |
1 | LOAD CSV FROM 'file:///hudong_genre.csv' AS line CREATE (:Genre { genre_id: line[0], genre_name: line[1] }); |
最终我们有 actor 节点 5392 个,属性 65252。movie 节点 13865 个,属性194110. genre 节点11,属性 11。
2. 导入关系
前面我们只是建立的演员和电影的节点,并没有关系链接它们。关系在 MYSQL中 对应于 actor_to_movie 表 和 movie_to_genre 表,分别对应 演员 :ACTED_IN 电影 的关系 和 电影 :Belong_to 类别 关系。
导入演员 :ACTED_IN 电影关系对应的语句为:
1 | LOAD CSV FROM 'file:///hudong_actor_to_movie.csv' AS line MATCH (a:Actor), (m:Movie) WHERE a.actor_id = line[1] AND m.movie_id = line[2] CREATE (a) - [r:ACTED_IN] -> (m) RETURN r; |
其中采用 LOAD CSV FROM 语句读取 CSV 文件,而后采用 CREATE 语句创建关系。第一对括号 (a:Actor {actor_id: line[1]}) 表示对于 line[1] 中给出的 actor_id 对应的节点 :Actor 节点a。第二对括号 (m:Movie {movie_id: line[2]}) 表示 line[2] 给出的 movie_id 对应的 :Movie 节点 m。它们之间的 - [r:ACTED_IN] -> 表示一个有向的关系r,它的标签为:ACTED_IN。因此上述语句就是先找到节点a 和 m,而后创建它们之间的关系 r。
运行语句后,我们得到 actor :ACTED_IN movie 关系 800个。
查看导入结果:
1 | MATCH p=()-[r:ACTED_IN]->() RETURN p LIMIT 25; |
与此类似,我们可以建立 电影 :Belong_to 类别关系。
1 | LOAD CSV FROM 'file:///hudong_movie_to_genre.csv' AS line CREATE (a:Movie {movie_id: line[1]}) - [r:Belong_to] ->(m:Genre {genre_id: line[2]}); |
获得 movie :Belong_to genre 关系 14558 个。
查看导入结果:
1 | MATCH p=()-[r:Belong_to]->() RETURN p LIMIT 25; |
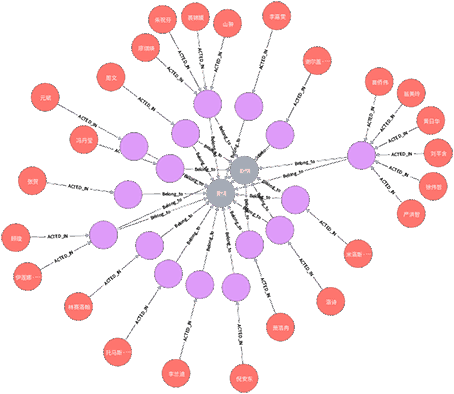
最终我们来一个总的结果:
1 | MATCH p=() -[] -> () - [r:Belong_to]->() RETURN p LIMIT 25 |