从零开始学习知识图谱 之 十二.百科知识图谱构建 6.基于Silk知识融合
本文于2301天之前发表,文中内容可能已经过时。
一. 简介
silk 是一个集成异构数据源的开源框架。编程语言为Python。其特点为:
- 提供了专门的 Silk-LSL 语言来进行具体处理。
- 提供图形化用户界面- Silk Workbench,用户可以很方便的进行记录链接。
Silk 的整体框架如下:
知识库-》预匹配-》链接-》过滤-》输出
包含以下几大块:
- 预处理:会将索引的结果排名前N的记录下来进行作为候选对,进行下一步更精准的匹配(损失精度)。
- 相似度计算:里面包含了很多相似度计算的方法。
- 过滤: 过滤掉相似度小于给定阈值的记录对。
本教程的项目代码放在github上,下载地址为《从零开始学习知识图谱》项目源代码 。
二. 环境准备
1. 操作系统
支持操作系统:windows、macOS、Linux。为了方便大家搭建开发环境,笔者尽可能在windows下构建,系列篇未特意说明时操作系统都是windows。Linux安装可以参考VirtualBox虚拟机安装Ubuntu或VirtualBox虚拟机安装CentOS8进行安装。
笔者建议在docker下安装silk,参考VirtualBox虚拟机安装Ubuntu,其中有安装docker。
在docker下,只须一条命令: docker run -d --name silk-workbench -p 80:80 silkframework/silk-workbench:latest ,就能完成silk镜像拉取及运行,不需要进行下面的软件安装。
1 | root@ubuntu-mmm:/usr/local/silk# docker run -d --name silk-workbench -p 80:80 silkframework/silk-workbench:latest |
2. jdk
安装参见windows系统安装JDK
3. Simple Build Tool(sbt)
**silk无需下载和安装sbt,因为silk自带有sbt。可以跳过此步。 **
SBT是SCALA 平台上标准的项目构建工具,当然你要用它来构建其他语言的项目也是可以的。SBT 没有Maven那么多概念和条条框框,但又比IVY要更加灵活,可以认为是一个精简版的Maven吧。
1)下载
下载页面 https://www.scala-sbt.org/download.html,下载Windows版的 sbt-x.x.x.msi安装包。
2)安装
直接下一步下一步,安装,然后默认会添加到系统的环境变量中,如果没有自己可以添加。
- 修改配置文件
a. 在sbt的安装目录中有一个conf目录,然后打开sbtconfig.txt,在文件末尾添加:
1 | -Dsbt.boot.directory=C:/my/sbt/data/.sbt/boot |
b. 然后在conf目录新建一个repo.properties文件,文件内容如下:
1 | [repositories] |
- 验证sbt
在dos窗口直接执行sbt即可, 如果在项目中可以执行:sbt run -Dsbt.override.build.repos=true命令使sbt运行的快一点 。
1 | C:\Users\mmm>sbt |
4. Node.js
Node.js® 是一个基于 Chrome V8 引擎的 JavaScript 运行时。 Node.js 使用高效、轻量级的事件驱动、非阻塞 I/O 模型。它的包生态系统,npm,是目前世界上最大的开源库生态系统。
1)下载
官方地址:https://nodejs.org/en/ 或 https://nodejs.org/zh-cn/ ,下载Windows版本。
2)安装
直接下一步下一步,安装。
3)安装完成查看
a、node -v 查看 node 版本
b、npm -v 查看 npm 版本
5. Yarn
yarn是由Facebook、Google、Exponent 和 Tilde 联合推出了一个新的 JS 包管理工具 ,正如官方文档中写的,Yarn 是为了弥补 npm 的一些缺陷而出现的。
1)安装
使用npm安装 ,命令npm i yarn -g
1 | C:\Users\mmm>npm i yarn -g |
yarn –version命令查看是否安装成功。
2) 卸载yarn
通过命令npm uninstall yarn -g卸载
3) 常用命令
yarn / yarn install 等同于npm install 批量安装依赖
yarn add xxx 等同于 npm install xxx —save 安装指定包到指定位置
yarn remove xxx 等同于 npm uninstall xxx —save 卸载指定包
yarn add xxx —dev 等同于 npm install xxx —save-dev
yarn upgrade 等同于 npm update 升级全部包
yarn global add xxx 等同于 npm install xxx -g 全局安装指定包
6. Silk
Silk是一个用于集成异构数据源的开源框架。
安装首页条件:JDK 8、 Simple Build Tool (sbt)、Yarn for React/JavaScript build pipeline (>= 1.3)
1)下载
下载页面: https://github.com/silk-framework/silk ,下载 https://codeload.github.com/silk-framework/silk/zip/develop 文件。
2)解压
解压后,放在合适的位置,笔者放在C:\my\silk。
3)运行 Silk Workbench
在silk目录下运行 sbt "project workbench" run命令,然后程序会开始编译,这一步会比较慢,等提示Server started 后,就可以在浏览器端打开 http://localhost:9000 进行访问了。
1 | C:\my\silk>sbt "project workbench" run |
三. Silk 的使用说明
关于 Silk 的详细介绍都在官方文档中,感兴趣的可以进行查看。我这里对 Workbench 给出个简短的介绍。
1. Workbench 概览
Workbench 引导用户完成创建链接任务的过程,以便链接两个数据源。 它提供以下组件:
- 工作区(workspace) 浏览器:允许用户浏览工作区中的项目。 链接任务可以从项目加载并稍后返回。
- 链接规则编辑器(Linkage Rule Editor):一种图形编辑器,使用户可以轻松创建和编辑链接规则。 窗口小部件将在树视图中显示当前链接规范,同时允许使用拖放进行编辑。
- 评估(Evaluation):允许用户执行当前的链接规则。 在即时生成链接时会显示这些链接。 生成的链接参考链接集未指定其正确性,用户可以确认或拒绝其正确性。 用户可以请求关于如何组成特定链接的相似性得分的详细摘要。
创建新链接任务的典型工作流程包括:
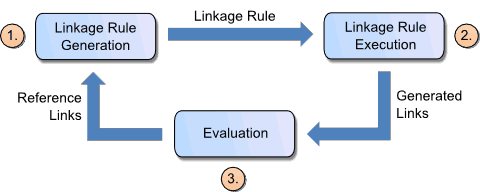
- 在执行实际匹配之前,需要构建一个链接规则,该规则指定如何比较两个实体的等价性。 链接规则可以由人类专家根据要匹配的数据源创建。
- 执行链接规则,产生一组链接。
- 评估步骤的目的是测量实体匹配任务的成功率并在生成的链接中查找潜在的错误。 实体匹配任务的成功可以通过将生成的链接与由一组参考链接组成的金标准进行比较来确定。 一组参考链接包含正参考链接,其标识已知匹配的实体对和负参考链接,其标识已知不匹配的对。 如果没有参考链接,则可以由确认或拒绝许多链接的人类专家生成 gold 标准。
2. 链接规则编辑器
链接规则编辑器允许用户以图形方式编辑链接规则。 通过拖放规则元素将链接规则创建为运算符树。编辑分为两部分:
- 左窗格包含给定数据集和限制的最常用属性路径。 它还包含所有可用运算符转换,比较器和聚合器的列表作为可拖动元素。
- 右侧部分(编辑器窗格)允许通过组合所选元素来绘制流程图。
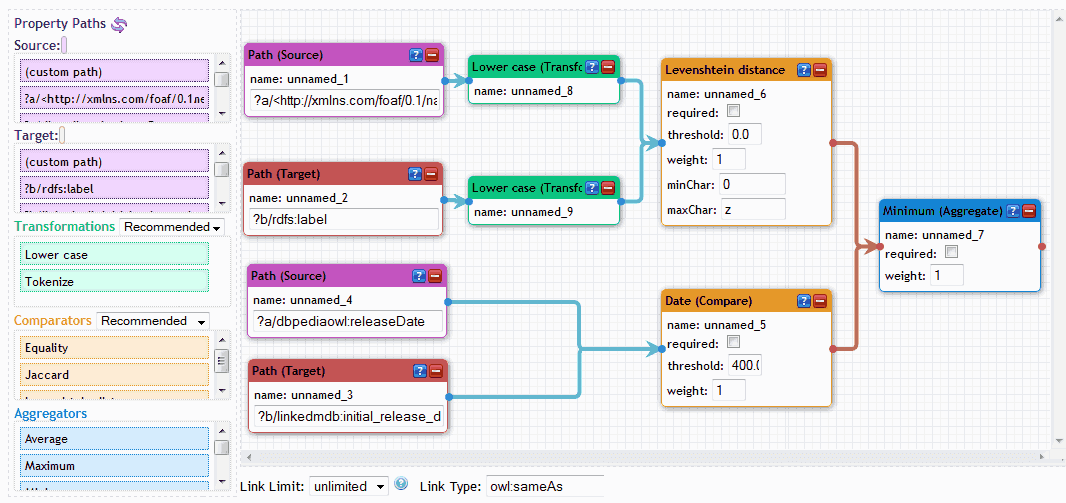
3. 编辑
- 将元素从左窗格拖到编辑器窗格。
- 通过从元素端点和元素端点(元素框左侧和右侧的点)绘制连接来连接元素。
- 通过连接元素来构建流程图,以单个元素(比较或聚合)结束。
编辑器将在绘制新连接线时通过突出显示可连接元素来指导用户构建流程图。
4. 属性路径
要链接的两个数据源的属性路径将加载到左窗格中,并按其频率在数据源中的顺序添加。 用户还可以通过将(自定义路径)元素拖到编辑器窗格并编辑路径来添加自定义路径。
5. 操作符
以下运算符窗格显示在属性路径下方:
- Transformations
- Comparisons
- Aggregations
将鼠标悬停在操作元素上将显示有关它们的更多信息。
6. 参考链接
参考链接(在记录链接中通常称为 gold 集)是一组链接,其正确性已被用户确认或拒绝。 参考链接可用于评估链接规则的完整性和正确性。
我们区分正面和负面的参考链接:
- 正参考链接代表最终匹配
- 负参考链接代表确定的不匹配。
四. Silk 实战
这里我采用两种格式数据分别进行融合:
- N-triples 文件
- SPARQL 端口
1. 基于 N-triples 文件
N-triples 文件就是我们在 d2rq 那步得到的 .nt 文件。不支持上传大的 N-triples 文件,否则会报错(Request Entity Too Large),因此这里实验只用几兆的 nt 文件,包含 1000 个三元组。 三元组文件下载
1) 项目的建立
在开启 silk 服务后,在浏览器端打开 http://localhost:9000 ,进入workspace 页面。点击 NEW project 按钮创建新项目,输入项目名字,如baike_merge。可以看到新项目包含 Datasets、Transform Tasks、Linking Tasks、Workflows、Others几项。
2) 添加Prefixes
点击项目名称后面的 Prefixes 按钮,设置 Prefixe:
- 点击加号按钮,分别添加下面两项
- hudong: http://www.kghudong.com#
- baidu: http://www.kgbaidu.com#
3) 创建Resource
点击项目名称后的 Resource 按钮,在这里我们可以添加或删除项目所使用的数据源。先上传输入资源(UPLOAD LOCAL),将两个 .nt 文件都传上去,然后创建新输出资源(DEFINE OUTPUT),在Name栏中填写想输出数据文件的名字,如baike_merge.nt,点击CREATE 完成文件的创建。
4) 创建数据集(Datasets)
点击项目名称会展开树,然后点击 Datasets 后的 +Add 按钮,在弹出的框中填写如下信息:
- 选择Resource Type数据类型 ,这里用的是三元组,因此选择 RDF file。
依次创建3次:
填写Name,如果file是baidu_test.nt 填写 baidu_test,hudong_test.nt 填写 hudong_test,baike_merge.nt填写output。
file ,选择对应的 nt 文件。
format 这里填写 N-Triples
点击 SAVE 。
然后进行下一个创建
现在应该有三个数据集baidu_test、hudong_test、output。
5) 建立 Linking Tasks
点击 Linking Tasks 后的Add按钮,建立链接任务。在弹出的框中,填写如下信息:
- 在 Name 那里填入任务名称,如 baike_test
- Source Dataset 那里选择 baidu_test
- Target Dataset 那里选择 hudong_test
- output 那里填入 output
- 点击 OK 完成创建
6) 编辑链接规则
点击Linking Tasks会展开子树,点击 baike_test 后的 Open 按钮进入 链接编辑界面。可以看到整个界面被分成两部分,左侧包含一系列的属性路径,右侧是编辑器窗格,允许我们来对属性路径进行组合。
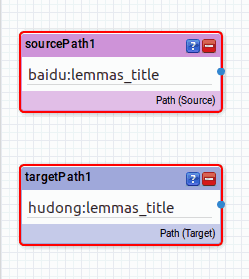
首先在Source Path 里找到 baidu:lemmas_title 这行(由于列表框太小,建议通过搜索框查找,下同),将它拖拽到右侧窗格中,在Target path 里找到 hudong:lemmas_title 这行,也拖拽到右侧窗格中。将两个上下放置,像这样
我们可以看到,接下来我们将 title 里面的字母全部转换为小写来统一格式。因此我们去左侧窗格的 Transformations 里找到 Lower case 这行,拽出来,放到 baidu:lemmas_title 和 hudong:lemmas_title 后面。现在整体长这样
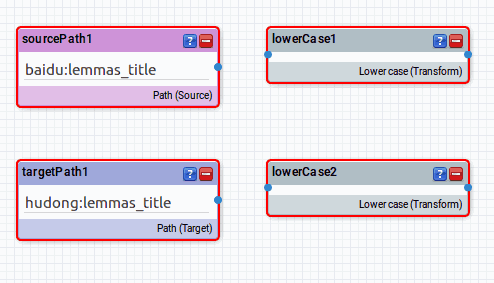
可以看到现在有四个框框,每个后面都有一个蓝色的圆点。点击 baidu:lemmas_title 后的圆点,拖拽鼠标将看到一个箭头,移动鼠标到 lower case 前面的圆点上则建立一个链接。hudong 那个也这么做,现在变成这样
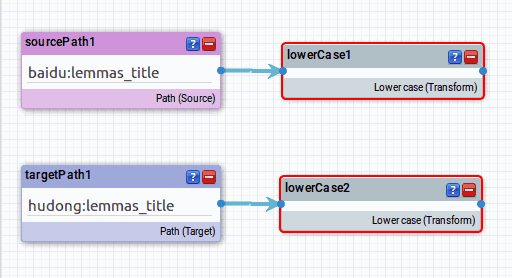
格式统一之后,我们采用 Levenshtein 距离来判断两个title 是不是相似的。因此去左侧窗格中的 Comparators 中找到 Levenshtein distance 这行,拖拽出来到右侧,并建立它与两个 lowerCase 框间的链接。
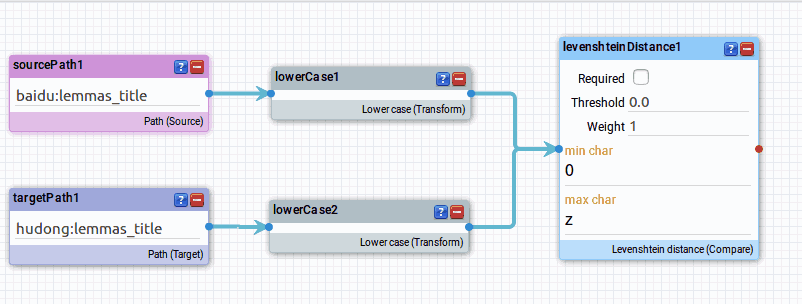
现在一个简单的链接规则就建立完毕了。
7) 生成链接(GENERATE LINKS)
点击最上方的 GENERATE LINKS 按钮,进入生成链接界面,在这里你可以判断链接结果是否正确并标记正负例。正负例可以用来计算准确率等一系列信息。
点击页面上方的运行按钮(三角形),可以看到程序正在运行,等程序运行完毕后,将出现以下界面:
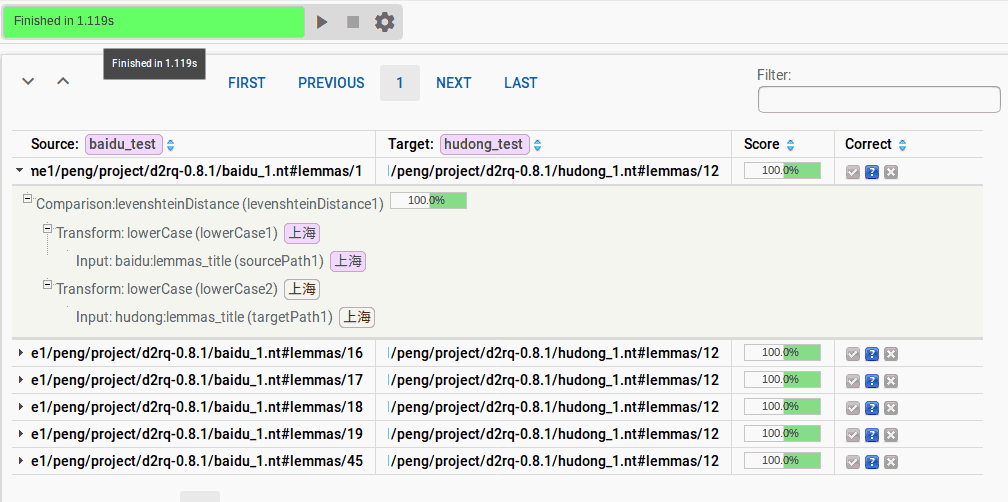
随意点击一行可以看到链接的详细信息。以第一个为例,可以看到 source 的 标题名称是上海,Target 的也是上海,两个确实是一样的。此时我们可以在 Correct 那列将问好改为对号。若标记结果错误那么就选择×,不确定则保持不动。
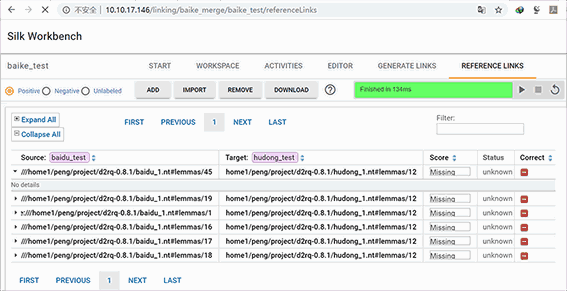
标记结束后,进入 REFERENCE LINKS 按钮,就可以看到我们刚刚标记的正例、负例和未标记部分。
2. 数据格式为 SPARQL 端口
前面说过对于 NT 格式,silk支持的数据很小,所以对于规模大一些的只能采用 SPARQL Endpoint 的形式。
和前面的主要区别是:
- Resource 那里不要添加输入.nt 文件
- 创建dataset 时:
- Resource Type 选择 SPARQL endpoint(remote)
- SPARQL 访问Fuseki作为服务器,endpoint URI 依次填写 http://localhost:3030/kg_demo_hudong/sparql 、 http://localhost:3030/kg_demo_baidu/sparql ,其中 kg_demo_hudong、kg_demo_baidu 是 Fuseki 服务器中数据库的名称。关于 Fuseki 的使用请见上一篇教程Jena使用简单SPARQL查询
创建好数据集后,其他的和之前的都一样。