深入理解kubernetes Pod之 六.Pod工作流
本文于2620天之前发表,文中内容可能已经过时。
接上文: 深入理解kubernetes Pod之 五.Pod容器初始化
我们知道Pod是Kubernetes中最小的调度单元,平时我们操作Pod的时间也是最多的,那么你知道Pod是怎样被创建出来的吗?知道他的工作流程吗?
组件之间的通信
我们知道在Kubernetes集群中apiserver是整个集群的控制入口,etcd在集群中充当数据库的作用,只有apiserver才可以直接去操作etcd集群,而我们的apiserver无论是对内还是对外都提供了统一的REST API服务,包括一个8080端口的非安全服务和6443端口的安全服务。组件之间当然也是通过apiserver进行通信的,其中kube-controller-manager、kube-scheduler、kubelet是通过apiserver watch API来监控我们的资源变化,并且对资源的相关状态更新操作也都是通过apiserver进行的,所以说白了组件之间的通信就是通过apiserver REST API和apiserver watch API进行的。
Pod 工作流
那么我们创建Pod的时候到底发生了什么呢?是怎样创建成功Pod的呢?
下面图示就是一个非常典型的Pod工作流程图:
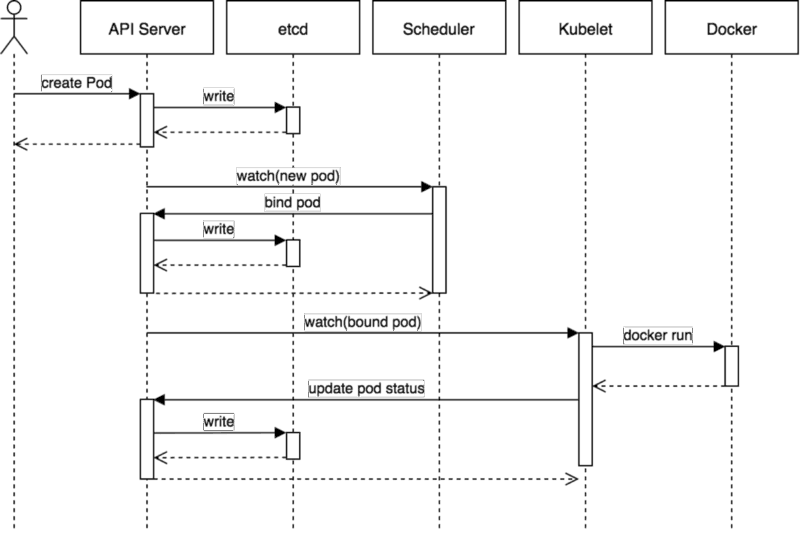
和上面的组件通信一致:
- 第一步通过
apiserver REST API创建一个Pod - 然后
apiserver接收到数据后将数据写入到etcd中 - 由于
kube-scheduler通过apiserver watch API一直在监听资源的变化,这个时候发现有一个新的Pod,但是这个时候该Pod还没和任何Node节点进行绑定,所以kube-scheduler就经过一系列复杂的调度策略,选择出一个合适的Node节点,将该Pod和该目标Node进行绑定,当然也会更新到etcd中去的 - 这个时候一样的目标
Node节点上的kubelet通过apiserver watch API检测到有一个新的Pod被调度过来了,他就将该Pod的相关数据传递给后面的容器运行时(container runtime),比如Docker,让他们去运行该Pod - 而且
kubelet还会通过container runtime获取Pod的状态,然后更新到apiserver中,当然最后也是写入到etcd中去的。
这样一个典型的Pod工作流就完成了,通过这个流程我们可以看出整个过程中最重要的就是apiserver watch API和kube-scheduler的调度策略。