接上文:kubernetes集群监控之 一.Prometheus
随着 Prometheus Operator 项目的成功,CoreOS 公司开源了一个比较厉害的工具:Operator Framework ,该工具可以让开发人员更加容易的开发 Operator 应用。
在本篇文章中我们会为大家介绍一个简单示例来演示如何使用 Operator Framework 框架来开发一个 Operator 应用。
Operator Operator是由CoreOS 公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。Operator基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识,比如创建一个数据库的Operator,则必须对创建的数据库的各种运维方式非常了解,创建Operator的关键是CRD(自定义资源)的设计。
CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在YAML文件里定义的那些spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前CoreOS官方提供了几种Operator的实现,其中就包括我们今天的主角:Prometheus Operator,Operator的核心实现就是基于 Kubernetes 的以下两个概念:
资源:对象的状态定义
控制器:观测、分析和行动,以调节资源的分布
当然我们如果有对应的需求也完全可以自己去实现一个Operator,接下来我们就来给大家详细介绍下Prometheus-Operator的使用方法。
介绍 首先我们先来了解下Prometheus-Operator的架构图:
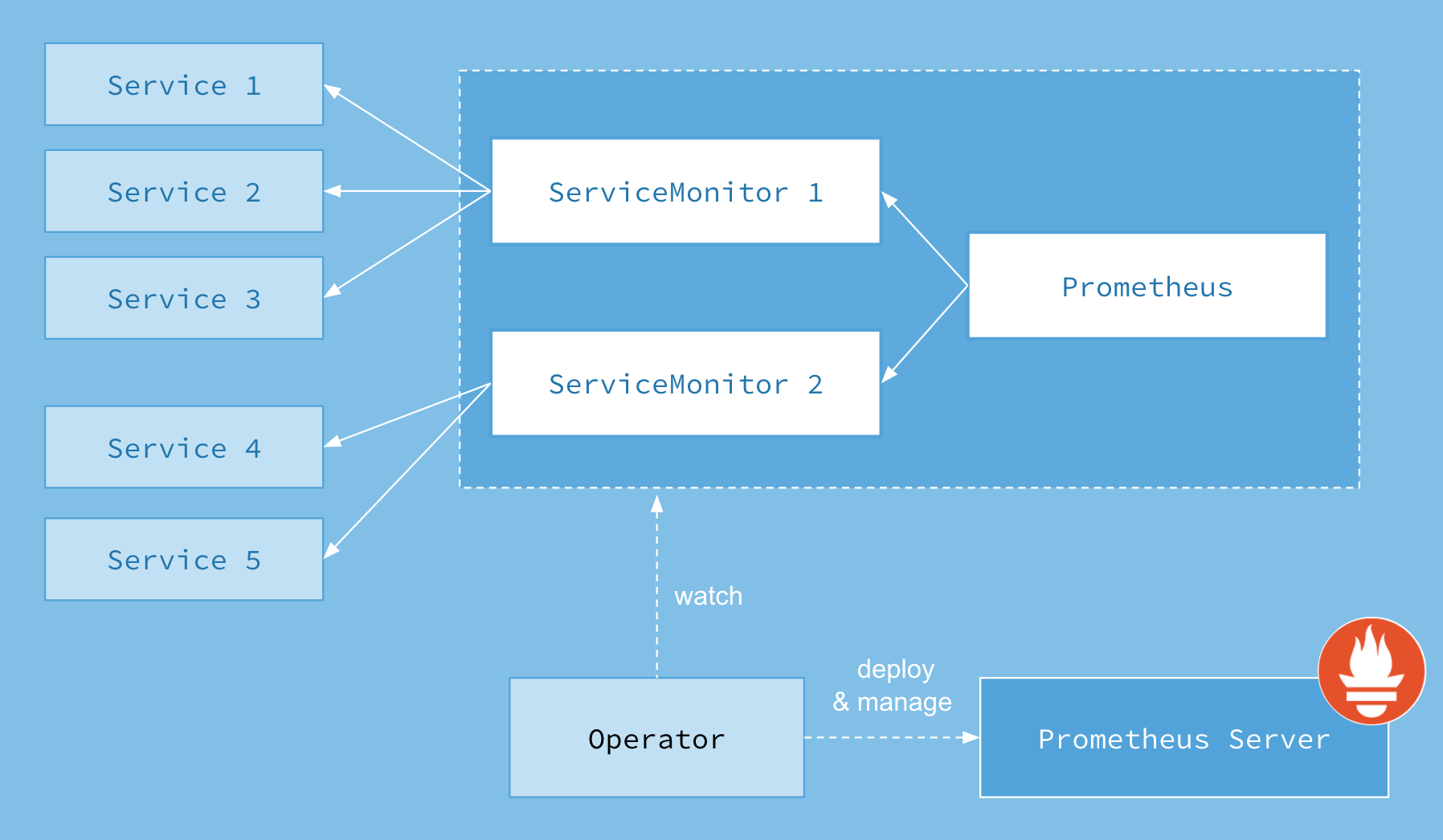
promtheus opeator
上图是Prometheus-Operator官方提供的架构图,其中Operator是最核心的部分,作为一个控制器,他会去创建Prometheus、ServiceMonitor、AlertManager以及PrometheusRule4个CRD资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的prometheus这种资源对象就是作为Prometheus Server存在,而ServiceMonitor就是exporter的各种抽象,exporter前面我们已经学习了,是用来提供专门提供metrics数据接口的工具,Prometheus就是通过ServiceMonitor提供的metrics数据接口去 pull 数据的,当然alertmanager这种资源对象就是对应的AlertManager的抽象,而PrometheusRule是用来被Prometheus实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
安装 我们这里直接通过 Prometheus-Operator 的源码来进行安装,当然也可以用 Helm 来进行一键安装,我们采用源码安装可以去了解更多的实现细节。首页将源码 Clone 下来:
1 2 3 4 5 6 $ git clone https ://github.com/coreos/kube-prometheus.git $ cd manifests $ ls 00 namespace-namespace.yaml node -exporter-clusterRole .yaml0 prometheus-operator-0 alertmanagerCustomResourceDefinition.yaml node -exporter-daemonset .yaml......
最新的版本官方将资源https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus 迁移到了独立的 git 仓库中:https://github.com/coreos/kube-prometheus.git
进入到 manifests 目录下面,这个目录下面包含我们所有的资源清单文件,我们需要对其中的文件 prometheus-serviceMonitorKubelet.yaml 进行简单的修改,因为默认情况下,这个 ServiceMonitor 是关联的 kubelet 的10250端口去采集的节点数据,而我们前面说过为了安全,这个 metrics 数据已经迁移到10255这个只读端口上面去了,我们只需要将文件中的https-metrics更改成http-metrics即可,这个在 Prometheus-Operator 对节点端点同步的代码中有相关定义,感兴趣的可以点此查看完整代码 :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 Subsets: []v1.EndpointSubset{ { Ports: []v1.EndpointPort{ { Name: "https-metrics" , Port: 10250 , } , { Name: "http-metrics" , Port: 10255 , } , { Name: "cadvisor" , Port: 4194 , } , } , } , } ,
修改完成后,直接在该文件夹下面执行创建资源命令即可:
部署完成后,会创建一个名为monitoring的 namespace,所以资源对象对将部署在改命名空间下面,此外 Operator 会自动创建4个 CRD 资源对象:
1 2 3 4 5 $ kubectl get crd |grep coreos alertmanagers.monitoring.coreos.com 5 d prometheuses.monitoring.coreos.com 5 d prometheusrules.monitoring.coreos.com 5 d servicemonitors.monitoring.coreos.com 5 d
可以在 monitoring 命名空间下面查看所有的 Pod,其中 alertmanager 和 prometheus 是用 StatefulSet 控制器管理的,其中还有一个比较核心的 prometheus-operator 的 Pod,用来控制其他资源对象和监听对象变化的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ kubectl get pods - n monitoring NAME READY STATUS RESTARTS AGE alertmanager-main-0 2 /2 Running 0 21 h alertmanager-main-1 2 /2 Running 0 21 h alertmanager-main-2 2 /2 Running 0 21 h grafana-df9bfd765-f4dvw 1 /1 Running 0 22 h kube-state-metrics-77 c9658489-ntj66 4 /4 Running 0 20 h node-exporter-4 sr7f 2 /2 Running 0 21 h node-exporter-9 mh2r 2 /2 Running 0 21 h node-exporter-m2gkp 2 /2 Running 0 21 h prometheus-adapter-dc548cc6-r6lhb 1 /1 Running 0 22 h prometheus-k8s-0 3 /3 Running 1 21 h prometheus-k8s-1 3 /3 Running 1 21 h prometheus-operator-bdf79ff67-9 dc48 1 /1 Running 0 21 h
查看创建的 Service:
1 2 3 4 5 6 7 8 9 10 11 kubectl get svc -n monitoringNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEalertmanager -main ClusterIP 10.110.204.224 <none> 9093 /TCP 23 halertmanager -operated ClusterIP None <none> 9093 /TCP,6783 /TCP 23 hgrafana ClusterIP 10.98.191.31 <none> 3000 /TCP 23 hkube -state-metrics ClusterIP None <none> 8443 /TCP,9443 /TCP 23 hnode -exporter ClusterIP None <none> 9100 /TCP 23 hprometheus -adapter ClusterIP 10.107.201.172 <none> 443 /TCP 23 hprometheus -k8s ClusterIP 10.107.105.53 <none> 9090 /TCP 23 hprometheus -operated ClusterIP None <none> 9090 /TCP 23 hprometheus -operator ClusterIP None <none> 8080 /TCP 23 h
可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service,我们这里为了简单,直接使用 NodePort 类型的服务即可,编辑 grafana 和 prometheus-k8s 这两个 Service,将服务类型更改为 NodePort:
1 2 3 4 5 6 7 $ kubectl edit svc grafana -n monitoring $ kubectl edit svc prometheus-k8s -n monitoring $ kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE grafana NodePort 10.98.191.31 <none> 3000:32333/TCP 23h prometheus-k8s NodePort 10.107.105.53 <none> 9090:30166/TCP 23h .. .. ..
更改完成后,我们就可以通过去访问上面的两个服务了,比如查看 prometheus � targets 页面:
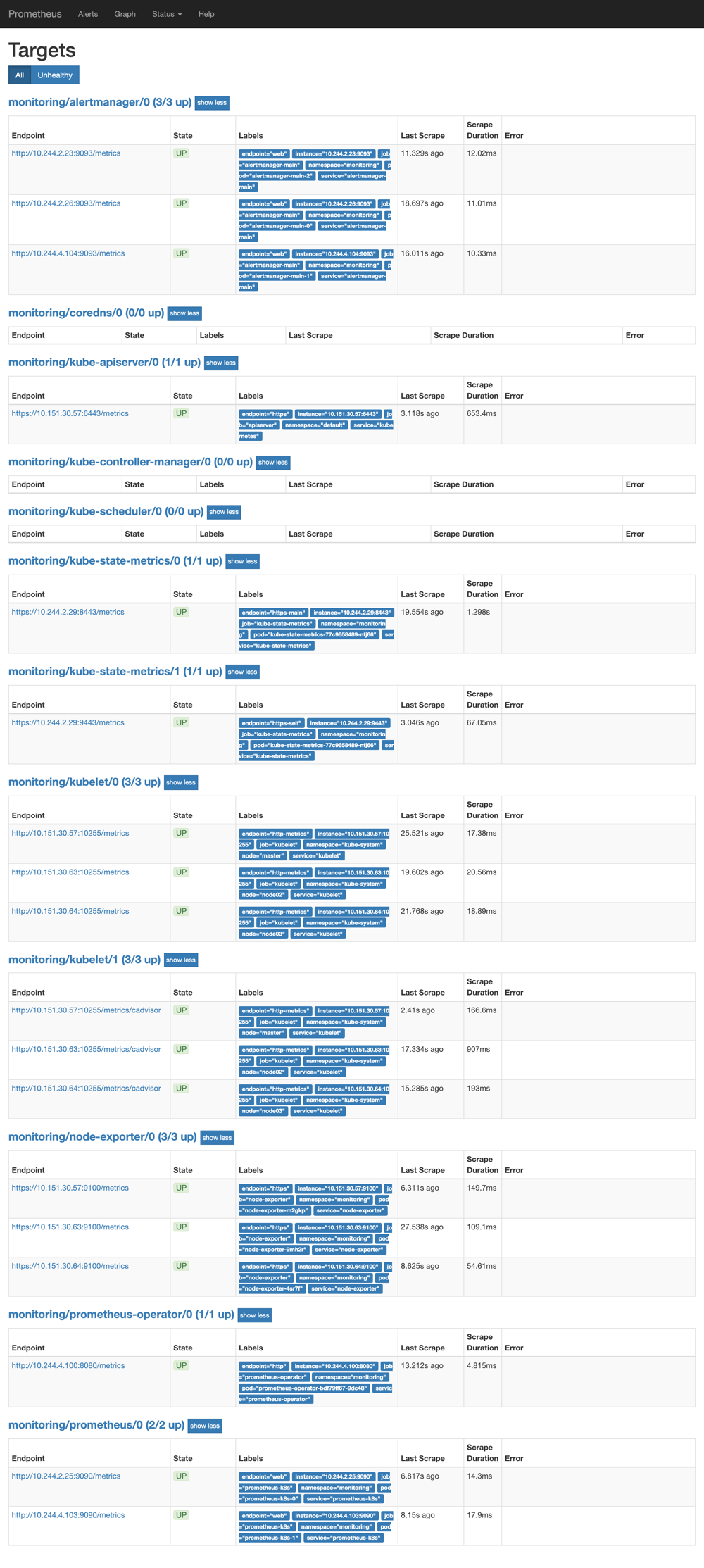
promtheus operator targets
配置 我们可以看到大部分的配置都是正常的,只有两三个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitormetadata: labels: k8s-app: kube-scheduler name: kube-scheduler namespace: monitoring spec: endpoints: - interval: 30 s port: http-metrics jobLabel: k8s-app namespaceSelector: matchNames: - kube-system selector: matchLabels: k8s-app: kube-scheduler
上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过selector.matchLabels在 kube-system 这个命名空间下面匹配具有k8s-app=kube-scheduler这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service:(prometheus-kubeSchedulerService.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion : v1 kind : Service metadata : namespace : kube-system name : kube-scheduler labels : k8s-app : kube-scheduler spec : selector : component : kube-scheduler ports : - name: http-metrics port : 10251 targetPort : 10251 protocol : TCP
10251是kube-scheduler组件 metrics 数据所在的端口,10252是kube-controller-manager组件的监控数据所在端口。
其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,selector下面配置的是component=kube-scheduler,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduelr 这个 Pod:
1 2 3 4 5 6 7 8 $ kubectl describe pod kube-scheduler-master -n kube-system Name: kube-scheduler-master Namespace : kube-systemNode : master /10.151 .30.57 Start Time: Sun, 05 Aug 2018 18 :13 :32 +0800 Labels: component= kube-scheduler tier= control-plane ......
我们可以看到这个 Pod 具有component=kube-scheduler和tier=control-plane这两个标签,而前面这个标签具有更唯一的特性,所以使用前面这个标签较好,这样上面创建的 Service 就可以和我们的 Pod 进行关联了,直接创建即可:
1 2 3 4 $ kubectl create -f prometheus-kubeSchedulerService.yaml $ kubectl get svc -n kube-system -l k8s-app=kube-scheduler NAME TYPE CLUSTER -IP EXTERNAL -IP PORT(S) AGEkube-scheduler ClusterIP 10.102 .119 .231 <none > 10251 /TCP 18 m
创建完成后,隔一小会儿后去 prometheus 查看 targets 下面 kube-scheduler 的状态:

promethus kube-scheduler error
我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在127.0.0.1上面的,而上面我们这个地方是想通过节点的 IP 去访问,所以访问被拒绝了,我们只要把 kube-scheduler 绑定的地址更改成0.0.0.0即可满足要求,由于 kube-scheduler 是以静态 Pod 的形式运行在集群中的,所以我们只需要更改静态 Pod 目录下面对应的 YAML 文件即可:
1 2 $ ls /etc/kubernetes/manifests/etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
将 kube-scheduler.yaml 文件中-command的--address地址更改成0.0.0.0:
1 2 3 4 5 6 containers :- command:- kube-scheduler- --leader-elect=true- --kubeconfig=/etc/kubernetes/scheduler.conf- --address=0.0.0.0
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-scheduler 这个 target 是否已经正常了:

promethues-operator-kube-scheduler
大家可以按照上面的方法尝试去修复下 kube-controller-manager 组件的监控。
上面的监控数据配置完成后,现在我们可以去查看下 grafana 下面的 dashboard,同样使用上面的 NodePort 访问即可,第一次登录使用 admin:admin 登录即可,进入首页后,可以发现已经和我们的 Prometheus 数据源关联上了,正常来说可以看到一些监控图表了:
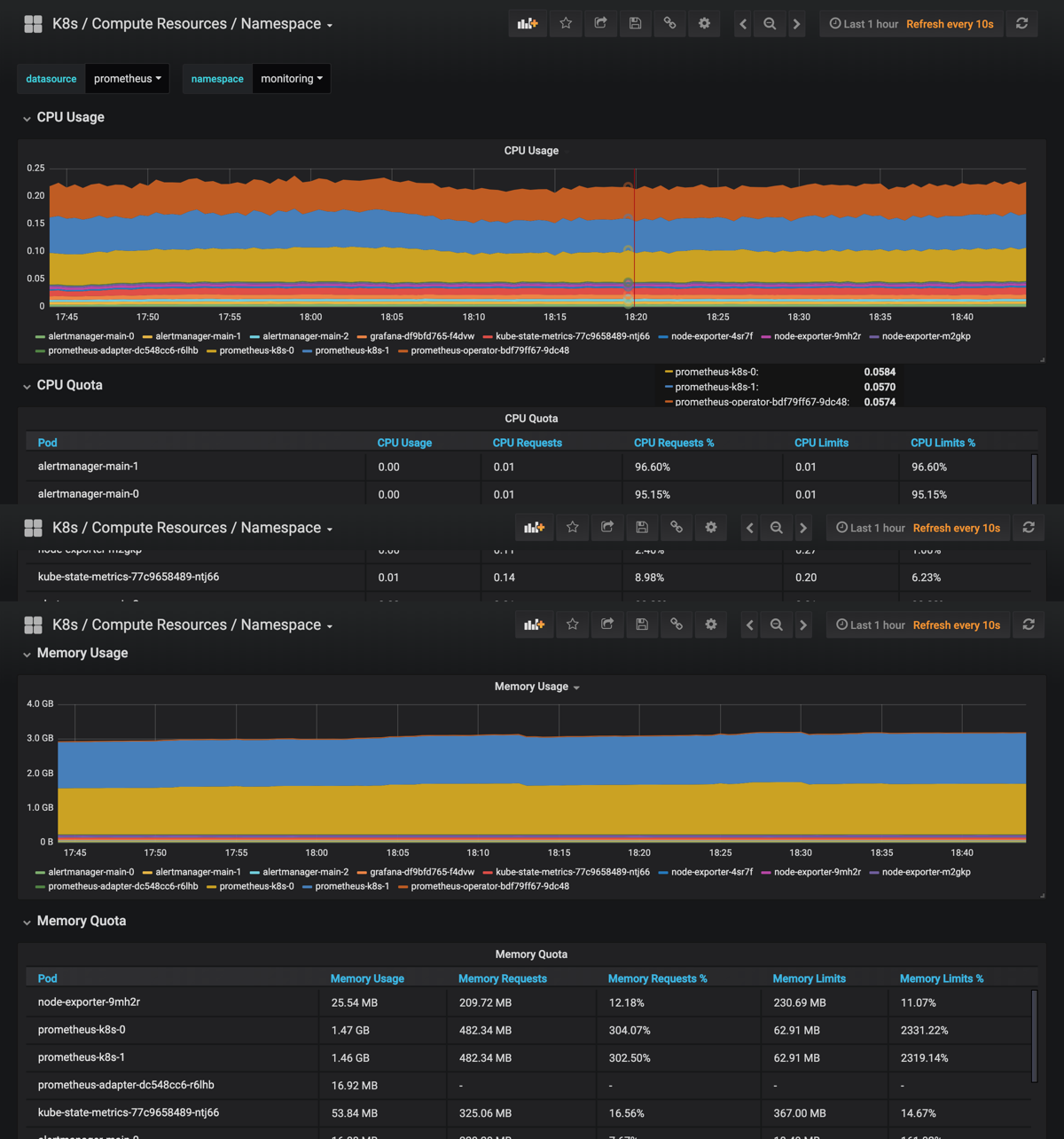
promethues-operator-grafana
自定义监控项 除了 Kubernetes 集群中的一些资源对象、节点以及组件需要监控,有的时候我们可能还需要根据实际的业务需求去添加自定义的监控项,添加一个自定义监控的步骤也是非常简单的。
第一步建立一个 ServiceMonitor 对象,用于 Prometheus 添加监控项
第二步为 ServiceMonitor 对象关联 metrics 数据接口的一个 Service 对象
第三步确保 Service 对象可以正确获取到 metrics 数据
接下来我们就来为大家演示如何添加 etcd 集群的监控。
无论是 Kubernetes 集群外的还是使用 Kubeadm 安装在集群内部的 etcd 集群,我们这里都将其视作集群外的独立集群,因为对于二者的使用方法没什么特殊之处。
etcd 证书 对于 etcd 集群一般情况下,为了安全都会开启 https 证书认证的方式,所以要想让 Prometheus 访问到 etcd 集群的监控数据,就需要提供相应的证书校验。
由于我们这里演示环境使用的是 Kubeadm 搭建的集群,我们可以使用 kubectl 工具去获取 etcd 启动的时候使用的证书路径:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 $ kubectl get pods -n kube-system NAME READY STATUS RESTARTS AGE etcd-master 1 /1 Running 0 2 h $ kubectl get pod etcd-master -n kube-system -o yaml ...... spec: containers: - command: - etcd - --peer-cert-file = /etc/ kubernetes/pki/ etcd/peer.crt - --listen-client-urls = https: - --advertise-client-urls = https: - --client-cert-auth = true - --peer-client-cert-auth = true - --data-dir = /var/ lib/etcd - --cert-file = /etc/ kubernetes/pki/ etcd/server.crt - --key-file = /etc/ kubernetes/pki/ etcd/server.key - --trusted-ca-file = /etc/ kubernetes/pki/ etcd/ca.crt - --peer-key-file = /etc/ kubernetes/pki/ etcd/peer.key - --peer-trusted-ca-file = /etc/ kubernetes/pki/ etcd/ca.crt image: k8s.gcr.io/etcd-amd64:3.1 .12 imagePullPolicy: IfNotPresent livenessProbe: exec: command: - /bin/ sh - -ec - ETCDCTL_API=3 etcdctl --endpoints = 127.0 .0 .1 :2379 --cacert = /etc/ kubernetes/pki/ etcd/ca.crt --cert = /etc/ kubernetes/pki/ etcd/healthcheck-client.crt --key = /etc/ kubernetes/pki/ etcd/healthcheck-client.key get foo failureThreshold: 8 initialDelaySeconds: 15 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 15 name: etcd resources: { } terminationMessagePath: /dev/ termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /var/ lib/etcd name: etcd-data - mountPath: /etc/ kubernetes/pki/ etcd name: etcd-certs...... tolerations: - effect: NoExecute operator: Exists volumes: - hostPath: path: /var/ lib/etcd type: DirectoryOrCreate name: etcd-data - hostPath: path: /etc/ kubernetes/pki/ etcd type: DirectoryOrCreate name: etcd-certs......
我们可以看到 etcd 使用的证书都对应在节点的 /etc/kubernetes/pki/etcd 这个路径下面,所以首先我们将需要使用到的证书通过 secret 对象保存到集群中去:(在 etcd 运行的节点)
1 2 $ kubectl -n monitoring create secret generic etcd-certs --from -file =/etc/ kubernetes/pki/ etcd/healthcheck-client.crt --from-file=/ etc/kubernetes/ pki/etcd/ healthcheck-client.key --from -file =/etc/ kubernetes/pki/ etcd/ca.crt secret "etcd-certs" created
如果你是独立的二进制方式启动的 etcd 集群,同样将对应的证书保存到集群中的一个 secret 对象中去即可。
然后将上面创建的 etcd-certs 对象配置到 prometheus 资源对象中,直接更新 prometheus 资源对象即可:
1 $ kubectl edit prometheus k8s -n monitoring
添加如下的 secrets 属性:
1 2 3 4 5 nodeSelector : beta.kubernetes.io/os : linux replicas : 2 secrets : - etcd-certs
更新完成后,我们就可以在 Prometheus 的 Pod 中获取到上面创建的 etcd 证书文件了,具体的路径我们可以进入 Pod 中查看:
1 2 3 4 5 $ kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring Defaulting container name to prometheus. Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod. / $ ls /etc/prometheus/secrets/etcd-certs/ ca .crt healthcheck-client.crt healthcheck-client.key
创建 ServiceMonitor 现在 Prometheus 访问 etcd 集群的证书已经准备好了,接下来创建 ServiceMonitor 对象即可(prometheus-serviceMonitorEtcd.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: monitoring.coreos.com/v1 kind: ServiceMonitormetadata: name: etcd-k8s namespace: monitoring labels: k8s-app: etcd-k8s spec: jobLabel: k8s-app endpoints: - port: port interval: 30 s scheme: https tlsConfig: caFile: /etc/prometheus/secrets/etcd-certs/ca.crt certFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.crt keyFile: /etc/prometheus/secrets/etcd-certs/healthcheck-client.key insecureSkipVerify: true selector: matchLabels: k8s-app: etcd namespaceSelector: matchNames: - kube-system
上面我们在 monitoring 命名空间下面创建了名为 etcd-k8s 的 ServiceMonitor 对象,基本属性和前面章节中的一致,匹配 kube-system 这个命名空间下面的具有 k8s-app=etcd 这个 label 标签的 Service,jobLabel 表示用于检索 job 任务名称的标签,和前面不太一样的地方是 endpoints 属性的写法,配置上访问 etcd 的相关证书,endpoints 属性下面可以配置很多抓取的参数,比如 relabel、proxyUrl,tlsConfig 表示用于配置抓取监控数据端点的 tls 认证,由于证书 serverName 和 etcd 中签发的可能不匹配,所以加上了 insecureSkipVerify=true

tlsConfig
关于 ServiceMonitor 属性的更多用法可以查看文档:https://github.com/coreos/prometheus-operator/blob/master/Documentation/api.md 了解更多
直接创建这个 ServiceMonitor 对象:
1 2 $ kubectl create -f prometheus-serviceMonitorEtcd.yaml servicemonitor.monitoring .coreos .com "etcd-k8s" created
创建 Service ServiceMonitor 创建完成了,但是现在还没有关联的对应的 Service 对象,所以需要我们去手动创建一个 Service 对象(prometheus-etcdService.yaml):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: v1 kind: Service metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd spec: type: ClusterIP clusterIP: None ports: - name: port port: 2379 protocol: TCP --- apiVersion: v1 kind: Endpoints metadata: name: etcd-k8s namespace: kube-system labels: k8s-app: etcd subsets: - addresses: - ip: 10.151 .30 .57 nodeName: etc-master ports: - name: port port: 2379 protocol: TCP
我们这里创建的 Service 没有采用前面通过 label 标签的形式去匹配 Pod 的做法,因为前面我们说过很多时候我们创建的 etcd 集群是独立于集群之外的,这种情况下面我们就需要自定义一个 Endpoints,要注意 metadata 区域的内容要和 Service 保持一致,Service 的 clusterIP 设置为 None,对改知识点不太熟悉的,可以去查看我们前面关于 Service 部分的讲解。
Endpoints 的 subsets 中填写 etcd 集群的地址即可,我们这里是单节点的,填写一个即可,直接创建该 Service 资源:
1 $ kubectl create -f prometheus-etcdService .yaml
创建完成后,隔一会儿去 Prometheus 的 Dashboard 中查看 targets,便会有 etcd 的监控项了:

prometheus etcd
可以看到还是有一个明显的错误,和我们上节课监控 kube-scheduler 的错误比较类似于,因为我们这里的 etcd 的是监听在 127.0.0.1 这个 IP 上面的,所以访问会拒绝:
1 --listen-client-urls=https:
同样我们只需要在 /etc/kubernetes/manifest/ 目录下面(static pod 默认的目录)的 etcd.yaml 文件中将上面的listen-client-urls更改成 0.0.0.0 即可:
1 --listen-client-urls=https:
重启 etcd,生效后,查看 etcd 这个监控任务就正常了:

prometheus etcd
数据采集到后,可以在 grafana 中导入编号为3070的 dashboard,获取到 etcd 的监控图表。
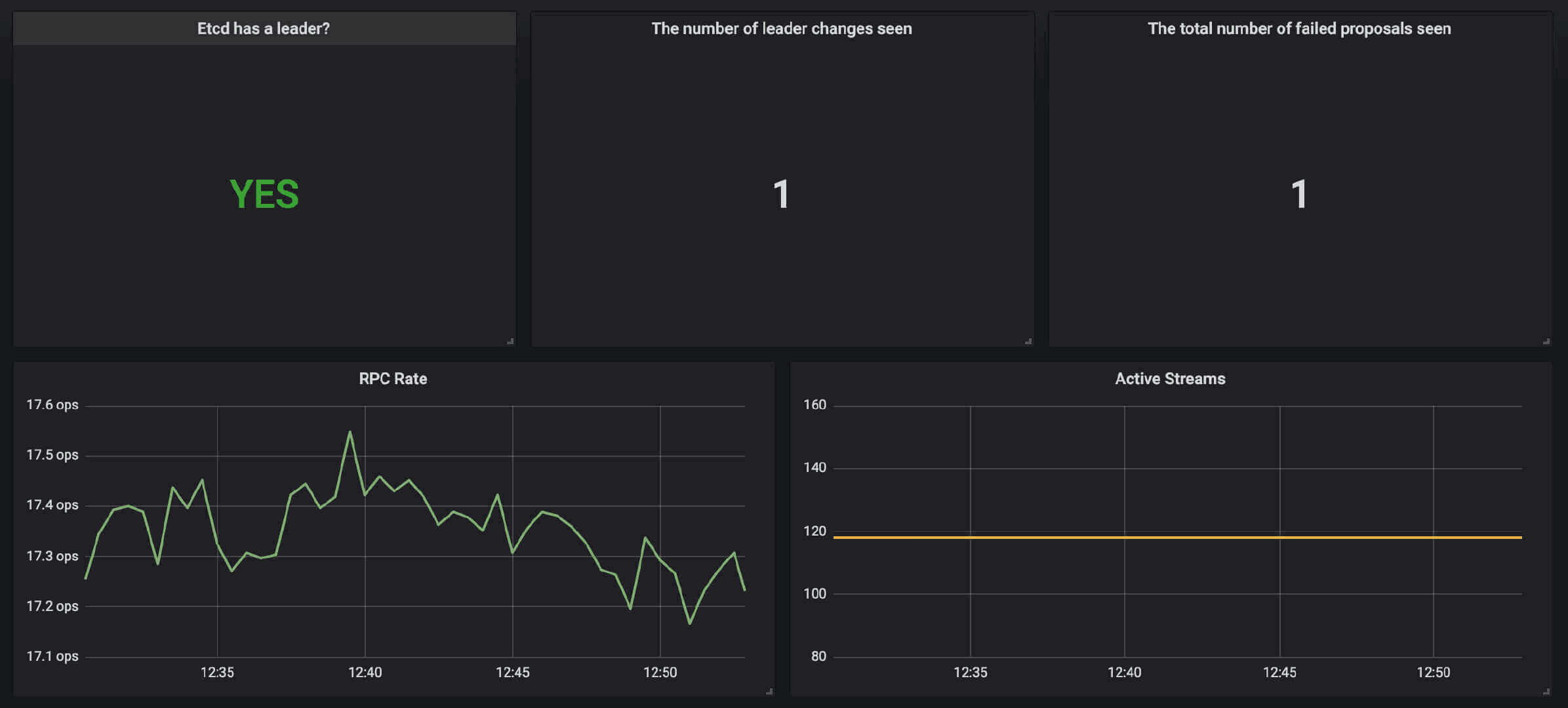
grafana etcd dashboard
配置 PrometheusRule 现在我们知道怎么自定义一个 ServiceMonitor 对象了,但是如果需要自定义一个报警规则的话呢?比如现在我们去查看 Prometheus Dashboard 的 Alert 页面下面就已经有一些报警规则了,还有一些是已经触发规则的了:
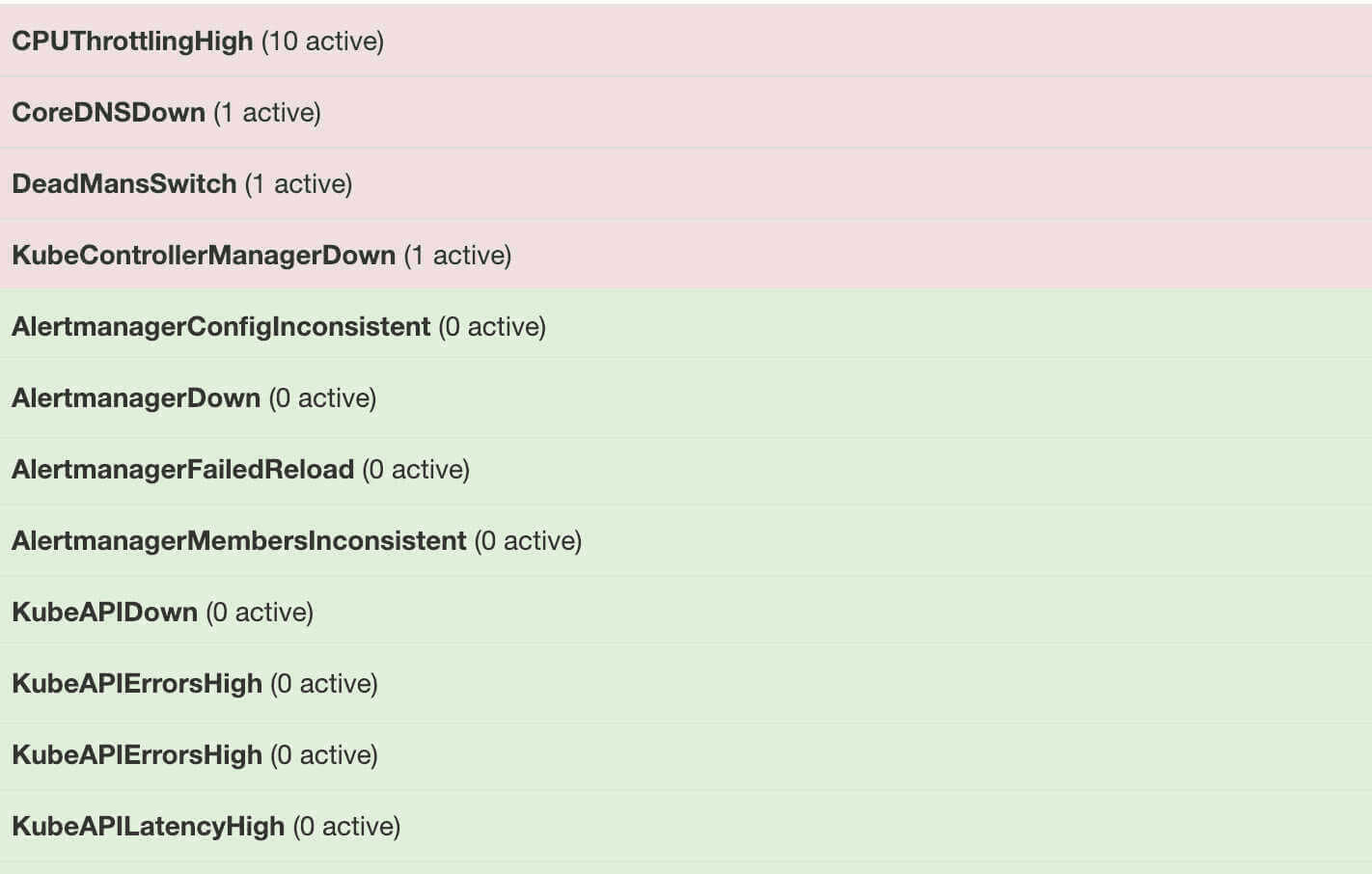
alerts
但是这些报警信息是哪里来的呢?他们应该用怎样的方式通知我们呢?我们知道之前我们使用自定义的方式可以在 Prometheus 的配置文件之中指定 AlertManager 实例和 报警的 rules 文件,现在我们通过 Operator 部署的呢?我们可以在 Prometheus Dashboard 的 Config 页面下面查看关于 AlertManager 的配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 alerting : alert_relabel_configs : - separator: ; regex : prometheus_replica replacement : $1 action : labeldrop alertmanagers : - kubernetes_sd_configs: - role: endpoints namespaces : names : - monitoring scheme : http path_prefix : / timeout : 10s relabel_configs : - source_labels: [__meta_kubernetes_service_name] separator : ; regex : alertmanager-main replacement : $1 action : keep - source_labels: [__meta_kubernetes_endpoint_port_name] separator : ; regex : web replacement : $1 action : keep rule_files : - /etc/prometheus/rules/prometheus-k8s-rulefiles-0/*.yaml
上面 alertmanagers 实例的配置我们可以看到是通过角色为 endpoints 的 kubernetes 的服务发现机制获取的,匹配的是服务名为 alertmanager-main,端口名未 web 的 Service 服务,我们查看下 alertmanager-main 这个 Service:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 kubectl describe svc alertmanager-main - n monitoring Name: alertmanager-mainNamespace: monitoringLabels: alertmanager= mainAnnotations: kubectl.kubernetes.io/ last-applied-configuration= {"apiVersion" :"v1" ,"kind" :"Service" ,"metadata" :{"annotations" :{},"labels" :{"alertmanager" :"main" },"name" :"alertmanager-main" ,"namespace" :"monitoring" },...Selector: alertmanager= main,app= alertmanagerType: NodePortIP: 10.104 .156.29 Port: web 9093 /TCP TargetPort: web/TCP NodePort: web 31918 /TCP Endpoints: 10.244 .2.34 :9093 ,10.244 .2.37 :9093 ,10.244 .4.109 :9093 Session Affinity: None External Traffic Policy: Cluster Events: <none>
可以看到服务名正是 alertmanager-main,Port 定义的名称也是 web,符合上面的规则,所以 Prometheus 和 AlertManager 组件就正确关联上了。而对应的报警规则文件位于:/etc/prometheus/rules/prometheus-k8s-rulefiles-0/目录下面所有的 YAML 文件。我们可以进入 Prometheus 的 Pod 中验证下该目录下面是否有 YAML 文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring Defaulting container name to prometheus. Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod. /prometheus $ ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/ monitoring-prometheus-k8s-rules.yaml /prometheus $ cat /etc/prometheus/rules/prometheus-k8s-rulefiles-0/monitoring-pr ometheus-k8s-rules.yaml groups :- name: k8s.rules rules: - expr : | sum (rate(container_cpu_usage_seconds_total{job="kubelet" , image!="" , container_name!="" }[5m])) by (namespace) record: namespace:container_cpu_usage_seconds_total:sum_rate ......
这个 YAML 文件实际上就是我们之前创建的一个 PrometheusRule 文件包含的:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ cat prometheus-rules.yaml apiVersion: monitoring.coreos.com/v1 kind: PrometheusRulemetadata: labels: prometheus: k8s role: alert-rules name: prometheus-k8s-rules namespace: monitoring spec: groups: - name: k8s.rules rules: - expr: | sum(rate(container_cpu_usage_seconds_total{job = "kubelet" , image!= "" , container_name!= "" }[5 m])) by (namespace) record: namespace:container_cpu_usage_seconds_total:sum_rate
我们这里的 PrometheusRule 的 name 为 prometheus-k8s-rules,namespace 为 monitoring,我们可以猜想到我们创建一个 PrometheusRule 资源对象后,会自动在上面的 prometheus-k8s-rulefiles-0 目录下面生成一个对应的<namespace>-<name>.yaml文件,所以如果以后我们需要自定义一个报警选项的话,只需要定义一个 PrometheusRule 资源对象即可。至于为什么 Prometheus 能够识别这个 PrometheusRule 资源对象呢?这就需要查看我们创建的 prometheus 这个资源对象了,里面有非常重要的一个属性 ruleSelector,用来匹配 rule 规则的过滤器,要求匹配具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 资源对象,现在明白了吧?
1 2 3 4 ruleSelector: matchLabels: prometheus: k8s role: alert-rules
所以我们要想自定义一个报警规则,只需要创建一个具有 prometheus=k8s 和 role=alert-rules 标签的 PrometheusRule 对象就行了,比如现在我们添加一个 etcd 是否可用的报警,我们知道 etcd 整个集群有一半以上的节点可用的话集群就是可用的,所以我们判断如果不可用的 etcd 数量超过了一半那么就触发报警,创建文件 prometheus-etcdRules.yaml:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: monitoring.coreos.com/v1 kind: PrometheusRulemetadata: labels: prometheus: k8s role: alert-rules name: etcd-rules namespace: monitoring spec: groups: - name: etcd rules: - alert: EtcdClusterUnavailable annotations: summary: etcd cluster small description: If one more etcd peer goes down the cluster will be unavailable expr: | count(up{job = "etcd" } == 0 ) > (count(up{job = "etcd" }) / 2 - 1 ) for: 3 m labels: severity: critical
注意 label 标签一定至少要有 prometheus=k8s 和 role=alert-rules,创建完成后,隔一会儿再去容器中查看下 rules 文件夹:
1 2 3 4 5 kubectl exec -it prometheus-k8s-0 /bin/sh -n monitoring Defaulting container name to prometheus. Use 'kubectl describe pod/prometheus-k8s-0 -n monitoring' to see all of the containers in this pod. /prometheus $ ls /etc/prometheus/rules/prometheus-k8s-rulefiles-0/ monitoring-etcd-rules.yaml monitoring-prometheus-k8s-rules.yaml
可以看到我们创建的 rule 文件已经被注入到了对应的 rulefiles 文件夹下面了,证明我们上面的设想是正确的。然后再去 Prometheus Dashboard 的 Alert 页面下面就可以查看到上面我们新建的报警规则了:
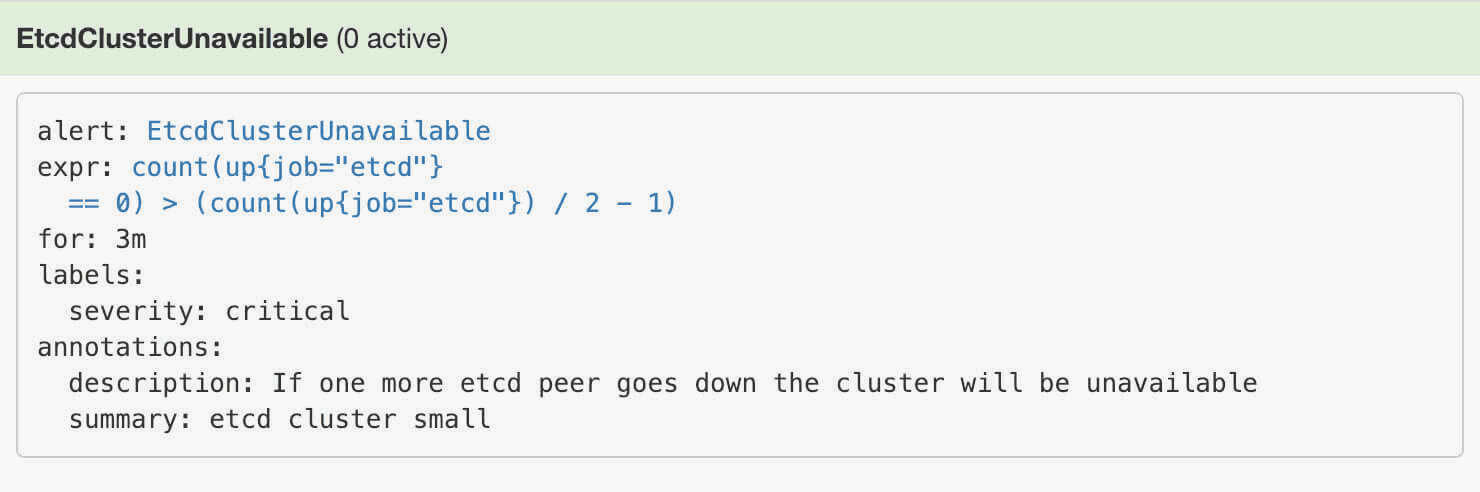
etcd cluster
配置报警 我们知道了如何去添加一个报警规则配置项,但是这些报警信息用怎样的方式去发送呢?前面的课程中我们知道我们可以通过 AlertManager 的配置文件去配置各种报警接收器,现在我们是通过 Operator 提供的 alertmanager 资源对象创建的组件,应该怎样去修改配置呢?
首先我们将 alertmanager-main 这个 Service 改为 NodePort 类型的 Service,修改完成后我们可以在页面上的 status 路径下面查看 AlertManager 的配置信息:

alertmanager config
这些配置信息实际上是来自于我们之前在prometheus-operator/contrib/kube-prometheus/manifests目录下面创建的 alertmanager-secret.yaml 文件:
1 2 3 4 5 6 7 8 apiVersion : v1 data : alertmanager.yaml : Imdsb2JhbCI6IAogICJyZXNvbHZlX3RpbWVvdXQiOiAiNW0iCiJyZWNlaXZlcnMiOiAKLSAibmFtZSI6ICJudWxsIgoicm91dGUiOiAKICAiZ3JvdXBfYnkiOiAKICAtICJqb2IiCiAgImdyb3VwX2ludGVydmFsIjogIjVtIgogICJncm91cF93YWl0IjogIjMwcyIKICAicmVjZWl2ZXIiOiAibnVsbCIKICAicmVwZWF0X2ludGVydmFsIjogIjEyaCIKICAicm91dGVzIjogCiAgLSAibWF0Y2giOiAKICAgICAgImFsZXJ0bmFtZSI6ICJEZWFkTWFuc1N3aXRjaCIKICAgICJyZWNlaXZlciI6ICJudWxsIg== kind : Secret metadata : name : alertmanager-main namespace : monitoring type : Opaque
可以将 alertmanager.yaml 对应的 value 值做一个 base64 解码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 $ echo "Imdsb2JhbCI6IAogICJyZXNvbHZlX3RpbWVvdXQiOiAiNW0iCiJyZWNlaXZlcnMiOiAKLSAibmFtZSI6ICJudWxsIgoicm91dGUiOiAKICAiZ3JvdXBfYnkiOiAKICAtICJqb2IiCiAgImdyb3VwX2ludGVydmFsIjogIjVtIgogICJncm91cF93YWl0IjogIjMwcyIKICAicmVjZWl2ZXIiOiAibnVsbCIKICAicmVwZWF0X2ludGVydmFsIjogIjEyaCIKICAicm91dGVzIjogCiAgLSAibWF0Y2giOiAKICAgICAgImFsZXJ0bmFtZSI6ICJEZWFkTWFuc1N3aXRjaCIKICAgICJyZWNlaXZlciI6ICJudWxsIg==" | base64 -d "global" : "resolve_timeout" : "5m" "receivers" :- "name" : "null" "route" : "group_by" : - "job" "group_interval" : "5m" "group_wait" : "30s" "receiver" : "null" "repeat_interval" : "12h" "routes" : - "match" : "alertname" : "DeadMansSwitch" "receiver" : "null"
我们可以看到内容和上面查看的配置信息是一致的,所以如果我们想要添加自己的接收器,或者模板消息,我们就可以更改这个文件:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 global: resolve_timeout: 5 m smtp_smarthost: 'smtp.163 .com:25 ' smtp_from: 'ych_1024@163 .com' smtp_auth_username: 'ych_1024@163 .com' smtp_auth_password: '< 邮箱密码> ' smtp_hello: '163 .com' smtp_require_tls: false route: group_by: ['job', 'severity'] group_wait: 30 s group_interval: 5 m repeat_interval: 12 h receiver: default routes: - receiver: webhook match: alertname: CoreDNSDown receivers: - name: 'default' email_configs: - to: '517554016 @qq.com' send_resolved: true - name: 'webhook' webhook_configs: - url: 'http:// dingtalk-hook.kube-ops:5000 ' send_resolved: true
将上面文件保存为 alertmanager.yaml,然后使用这个文件创建一个 Secret 对象:
1 2 3 4 5 $ kubectl delete secret alertmanager-main -n monitoring secret "alertmanager-main" deleted$ kubectl create secret generic alertmanager-main --from-file =alertmanager.yaml -n monitoring secret "alertmanager-main" created
我们添加了两个接收器,默认的通过邮箱进行发送,对于 CoreDNSDown 这个报警我们通过 webhook 来进行发送,这个 webhook 就是我们前面课程中定义的一个钉钉接收的 Server,上面的步骤创建完成后,很快我们就会收到一条钉钉消息:

钉钉
同样邮箱中也会收到报警信息:
邮箱
我们再次查看 AlertManager 页面的 status 页面的配置信息可以看到已经变成上面我们的配置信息了:
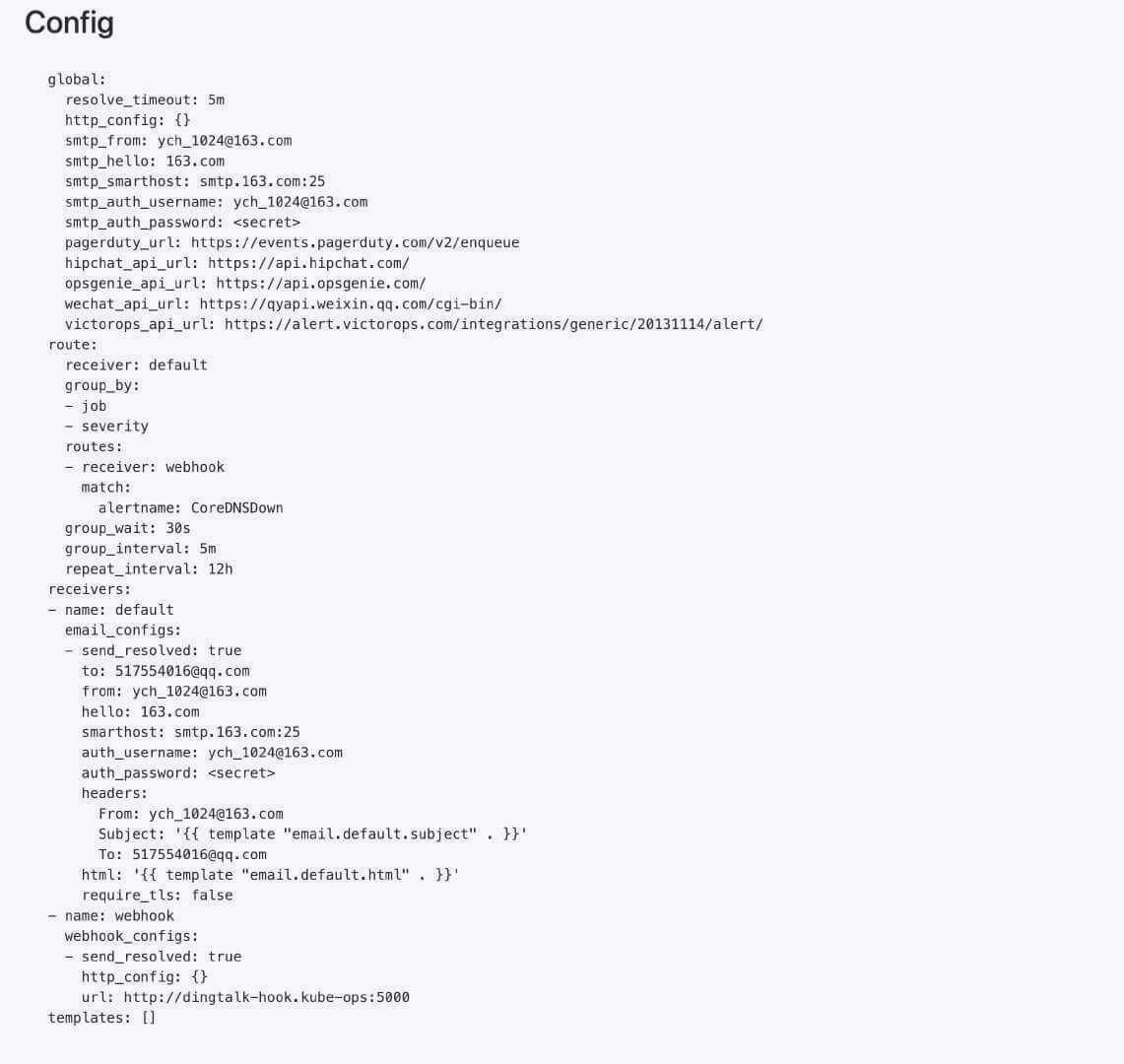
alertmanager config
AlertManager 配置也可以使用模板(.tmpl文件),这些模板可以与 alertmanager.yaml 配置文件一起添加到 Secret 对象中,比如:
1 2 3 4 5 6 7 8 9 apiVersion:v1 kind:secret metadata: name:alertmanager-example data: alertmanager.yaml:{BASE64_CONFIG} BASE64_TEMPLATE_1} BASE64_TEMPLATE_2}
模板会被放置到与配置文件相同的路径,当然要使用这些模板文件,还需要在 alertmanager.yaml 配置文件中指定:
创建成功后,Secret 对象将会挂载到 AlertManager 对象创建的 AlertManager Pod 中去。
高级配置 上节课我们一起学习了如何在 Prometheus Operator 下面自定义一个监控选项,以及自定义报警规则的使用。那么我们还能够直接使用前面课程中的自动发现功能吗?如果在我们的 Kubernetes 集群中有了很多的 Service/Pod,那么我们都需要一个一个的去建立一个对应的 ServiceMonitor 对象来进行监控吗?这样岂不是又变得麻烦起来了?
自动发现配置 为解决上面的问题,Prometheus Operator 为我们提供了一个额外的抓取配置的来解决这个问题,我们可以通过添加额外的配置来进行服务发现进行自动监控。和前面自定义的方式一样,我们想要在 Prometheus Operator 当中去自动发现并监控具有prometheus.io/scrape=true这个 annotations 的 Service,之前我们定义的 Prometheus 的配置如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https? ) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+ ) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+ )(? ::\d+ )? ;(\d+ ) replacement: $1 :$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+ ) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name
如果你对上面这个配置还不是很熟悉的话,建议去查看下前面关于 Kubernetes常用资源对象监控章节的介绍 ,要想自动发现集群中的 Service,就需要我们在 Service 的annotation区域添加prometheus.io/scrape=true的声明,将上面文件直接保存为 prometheus-additional.yaml,然后通过这个文件创建一个对应的 Secret 对象:
1 2 $ kubectl create secret generic additional-configs --from-file =prometheus-additional.yaml -n monitoring secret "additional-configs" created
注意我们所有的操作都在 Prometheus Operator 源码contrib/kube-prometheus/manifests/目录下面。
创建完成后,会将上面配置信息进行 base64 编码后作为 prometheus-additional.yaml 这个 key 对应的值存在:
1 2 3 4 5 6 7 8 9 10 11 12 13 $ kubectl get secret additional-configs -n monitoring -o yaml apiVersion: v1data: prometheus-additional.yaml: LSBqb2JfbmFtZTogJ2t1YmVybmV0ZXMtc2VydmljZS1lbmRwb2ludHMnCiAga3ViZXJuZXRlc19zZF9jb25maWdzOgogIC0gcm9sZTogZW5kcG9pbnRzCiAgcmVsYWJlbF9jb25maWdzOgogIC0gc291cmNlX2xhYmVsczogW19fbWV0YV9rdWJlcm5ldGVzX3NlcnZpY2VfYW5ub3RhdGlvbl9wcm9tZXRoZXVzX2lvX3NjcmFwZV0KICAgIGFjdGlvbjoga2VlcAogICAgcmVnZXg6IHRydWUKICAtIHNvdXJjZV9sYWJlbHM6IFtfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19zY2hlbWVdCiAgICBhY3Rpb246IHJlcGxhY2UKICAgIHRhcmdldF9sYWJlbDogX19zY2hlbWVfXwogICAgcmVnZXg6IChodHRwcz8pCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9hbm5vdGF0aW9uX3Byb21ldGhldXNfaW9fcGF0aF0KICAgIGFjdGlvbjogcmVwbGFjZQogICAgdGFyZ2V0X2xhYmVsOiBfX21ldHJpY3NfcGF0aF9fCiAgICByZWdleDogKC4rKQogIC0gc291cmNlX2xhYmVsczogW19fYWRkcmVzc19fLCBfX21ldGFfa3ViZXJuZXRlc19zZXJ2aWNlX2Fubm90YXRpb25fcHJvbWV0aGV1c19pb19wb3J0XQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IF9fYWRkcmVzc19fCiAgICByZWdleDogKFteOl0rKSg/OjpcZCspPzsoXGQrKQogICAgcmVwbGFjZW1lbnQ6ICQxOiQyCiAgLSBhY3Rpb246IGxhYmVsbWFwCiAgICByZWdleDogX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9sYWJlbF8oLispCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfbmFtZXNwYWNlXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZXNwYWNlCiAgLSBzb3VyY2VfbGFiZWxzOiBbX19tZXRhX2t1YmVybmV0ZXNfc2VydmljZV9uYW1lXQogICAgYWN0aW9uOiByZXBsYWNlCiAgICB0YXJnZXRfbGFiZWw6IGt1YmVybmV0ZXNfbmFtZQo= kind: Secretmetadata: creationTimestamp: 2018 -12 -20 T14:50 :35 Z name: additional-configs namespace: monitoring resourceVersion: "41814998" selfLink: /api/ v1/namespaces/ monitoring/secrets/ additional-configs uid: 9 bbe22c5-0466 -11e9 -a777-525400 db4df7type: Opaque
然后我们只需要在声明 prometheus 的资源对象文件中添加上这个额外的配置:(prometheus-prometheus.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 apiVersion: monitoring.coreos.com/v1 kind: Prometheusmetadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - name: alertmanager-main namespace: monitoring port: web baseImage: quay.io/prometheus/prometheus nodeSelector: beta.kubernetes.io/ os: linux replicas: 2 secrets: - etcd-certs resources: requests: memory: 400 Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 additionalScrapeConfigs: name: additional-configs key: prometheus-additional.yaml serviceAccountName: prometheus-k8s serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: v2.5.0
添加完成后,直接更新 prometheus 这个 CRD 资源对象:
1 2 $ kubectl apply -f prometheus-prometheus.yaml prometheus.monitoring .coreos .com "k8s" configured
隔一小会儿,可以前往 Prometheus 的 Dashboard 中查看配置是否生效:

config
在 Prometheus Dashboard 的配置页面下面我们可以看到已经有了对应的的配置信息了,但是我们切换到 targets 页面下面却并没有发现对应的监控任务,查看 Prometheus 的 Pod 日志:
1 2 3 4 5 $ kubectl logs -f prometheus-k8s-0 prometheus -n monitoring level =error ts =2018-12-20T15:14:06.772903214Z caller =main.go:240 component =k8s_client_runtime err ="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:302: Failed to list *v1.Pod: pods is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list pods at the cluster scope" level =error ts =2018-12-20T15:14:06.773096875Z caller =main.go:240 component =k8s_client_runtime err ="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:301: Failed to list *v1.Service: services is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list services at the cluster scope" level =error ts =2018-12-20T15:14:06.773212629Z caller =main.go:240 component =k8s_client_runtime err ="github.com/prometheus/prometheus/discovery/kubernetes/kubernetes.go:300: Failed to list *v1.Endpoints: endpoints is forbidden: User \"system:serviceaccount:monitoring:prometheus-k8s\" cannot list endpoints at the cluster scope" .. .. ..
可以看到有很多错误日志出现,都是xxx is forbidden,这说明是 RBAC 权限的问题,通过 prometheus 资源对象的配置可以知道 Prometheus 绑定了一个名为 prometheus-k8s 的 ServiceAccount 对象,而这个对象绑定的是一个名为 prometheus-k8s 的 ClusterRole:(prometheus-clusterRole.yaml)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion : rbac.authorization.k8s.io/v1 kind : ClusterRole metadata : name : prometheus-k8s rules : - apiGroups: - "" resources : - nodes/metrics verbs : - get - nonResourceURLs: - /metrics verbs : - get
上面的权限规则中我们可以看到明显没有对 Service 或者 Pod 的 list 权限,所以报错了,要解决这个问题,我们只需要添加上需要的权限即可:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 apiVersion : rbac.authorization.k8s.io/v1 kind : ClusterRole metadata : name : prometheus-k8s rules : - apiGroups: - "" resources : - nodes - services - endpoints - pods - nodes/proxy verbs : - get - list - watch - apiGroups: - "" resources : - configmaps - nodes/metrics verbs : - get - nonResourceURLs: - /metrics verbs : - get
更新上面的 ClusterRole 这个资源对象,然后重建下 Prometheus 的所有 Pod,正常就可以看到 targets 页面下面有 kubernetes-service-endpoints 这个监控任务了:
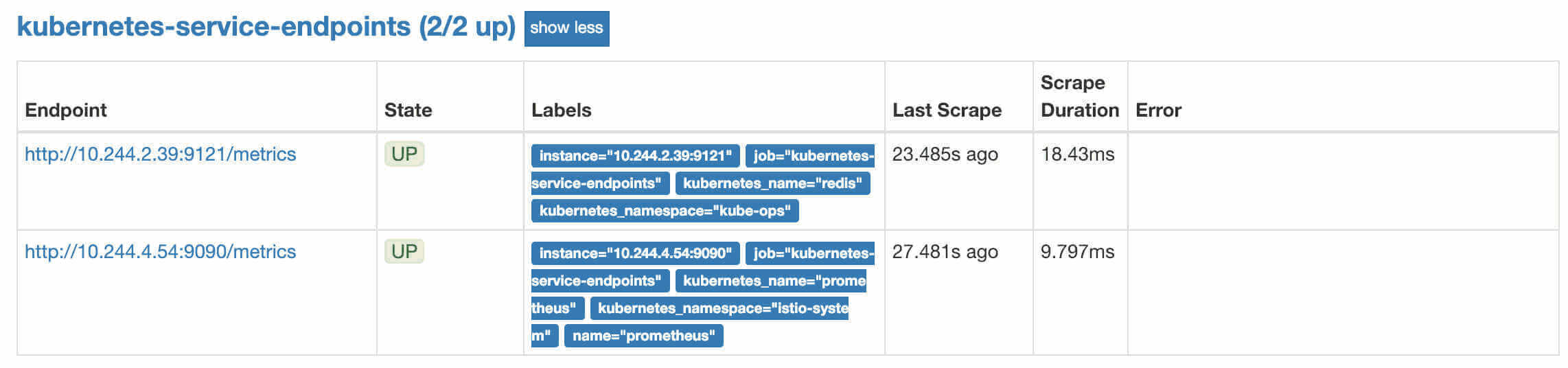
endpoints
我们这里自动监控了两个 Service,第一个就是我们之前创建的 Redis 的服务,我们在 Redis Service 中有两个特殊的 annotations:
1 2 3 annotations: prometheus.io/ scrape: "true" prometheus.io/ port: "9121"
所以被自动发现了,当然我们也可以用同样的方式去配置 Pod、Ingress 这些资源对象的自动发现。
数据持久化 上面我们在修改完权限的时候,重启了 Prometheus 的 Pod,如果我们仔细观察的话会发现我们之前采集的数据已经没有了,这是因为我们通过 prometheus 这个 CRD 创建的 Prometheus 并没有做数据的持久化,我们可以直接查看生成的 Prometheus Pod 的挂载情况就清楚了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 $ kubectl get pod prometheus-k8s-0 -n monitoring -o yaml ...... volumeMounts: - mountPath: /etc/prometheus/config_out name: config-out readOnly: true - mountPath: /prometheus name: prometheus-k8s-db ...... volumes: ...... - emptyDir: {} name: prometheus-k8s-db ......
我们可以看到 Prometheus 的数据目录 /prometheus 实际上是通过 emptyDir 进行挂载的,我们知道 emptyDir 挂载的数据的生命周期和 Pod 生命周期一致的,所以如果 Pod 挂掉了,数据也就丢失了,这也就是为什么我们重建 Pod 后之前的数据就没有了的原因,对应线上的监控数据肯定需要做数据的持久化的,同样的 prometheus 这个 CRD 资源也为我们提供了数据持久化的配置方法,由于我们的 Prometheus 最终是通过 Statefulset 控制器进行部署的,所以我们这里需要通过 storageclass 来做数据持久化,首先创建一个 StorageClass 对象:
1 2 3 4 5 apiVersion: storage.k8s.io/v1 kind: StorageClassmetadata: name: prometheus-data-db provisioner: fuseim.pri/ ifs
这里我们声明一个 StorageClass 对象,其中 provisioner=fuseim.pri/ifs,则是因为我们集群中使用的是 nfs 作为存储后端,而前面我们课程中创建的 nfs-client-provisioner 中指定的 PROVISIONER_NAME 就为 fuseim.pri/ifs,这个名字不能随便更改,将该文件保存为 prometheus-storageclass.yaml:
1 2 $ kubectl create -f prometheus-storageclass.yaml storageclass.storage .k8s .io "prometheus-data-db" created
然后在 prometheus 的 CRD 资源对象中添加如下配置:
1 2 3 4 5 6 7 storage: volumeClaimTemplate: spec: storageClassName: prometheus-data-db resources: requests: storage: 10 Gi
注意这里的 storageClassName 名字为上面我们创建的 StorageClass 对象名称,然后更新 prometheus 这个 CRD 资源。更新完成后会自动生成两个 PVC 和 PV 资源对象:
1 2 3 4 5 6 7 8 $ kubectl get pvc -n monitoring NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE prometheus-k8s-db-prometheus-k8s-0 Bound pvc-0 cc03d41-047 a-11 e9-a777-525400 db4df7 10Gi RWO prometheus-data-db 8m prometheus-k8s-db-prometheus-k8s-1 Bound pvc-1938 de6b-047 b-11 e9-a777-525400 db4df7 10Gi RWO prometheus-data-db 1m $ kubectl get pv NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE pvc-0 cc03d41-047 a-11 e9-a777-525400 db4df7 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-0 prometheus-data-db 2m pvc-1938 de6b-047 b-11 e9-a777-525400 db4df7 10Gi RWO Delete Bound monitoring/prometheus-k8s-db-prometheus-k8s-1 prometheus-data-db 1m
现在我们再去看 Prometheus Pod 的数据目录就可以看到是关联到一个 PVC 对象上了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 $ kubectl get pod prometheus-k8s-0 -n monitoring -o yaml ...... volumeMounts: - mountPath: /etc/prometheus/config_out name: config-out readOnly: true - mountPath: /prometheus name: prometheus-k8s-db ...... volumes: ...... - name: prometheus-k8s-db persistentVolumeClaim: claimName: prometheus-k8s-db-prometheus-k8s-0 ......
现在即使我们的 Pod 挂掉了,数据也不会丢失了,最后,下面是我们 Prometheus Operator 系列课程中最终的创建资源清单文件,更多的信息可以在https://github.com/myhhub/kubernetes-learning 下面查看。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 apiVersion: monitoring.coreos.com/v1 kind: Prometheusmetadata: labels: prometheus: k8s name: k8s namespace: monitoring spec: alerting: alertmanagers: - name: alertmanager-main namespace: monitoring port: web storage: volumeClaimTemplate: spec: storageClassName: prometheus-data-db resources: requests: storage: 10 Gi baseImage: quay.io/prometheus/prometheus nodeSelector: beta.kubernetes.io/ os: linux replicas: 2 secrets: - etcd-certs additionalScrapeConfigs: name: additional-configs key: prometheus-additional.yaml resources: requests: memory: 400 Mi ruleSelector: matchLabels: prometheus: k8s role: alert-rules securityContext: fsGroup: 2000 runAsNonRoot: true runAsUser: 1000 serviceAccountName: prometheus-k8s serviceMonitorNamespaceSelector: {} serviceMonitorSelector: {} version: v2.5.0
接下文:kubernetes集群监控之 三.Grafana