#第一次都要用ssh密码登录太麻烦,我们想办法采用无密码登录 chu888chu888@ubuntu2:~$ cd ~/.ssh/ chu888chu888@ubuntu2:~/.ssh$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/chu888chu888/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/chu888chu888/.ssh/id_rsa. Your public key has been saved in /home/chu888chu888/.ssh/id_rsa.pub. The key fingerprint is: 3a:51:9b:99:3e:65:9d:9a:b4:60:35:4f:79:d9:5b:89 chu888chu888@ubuntu2 The key's randomart image is: +--[ RSA 2048]----+ || | ..o.| | . o oEo.o| | . * = o o| | . S + + . | | = = + | | o o + | | . . | || +-----------------+ chu888chu888@ubuntu2:~/.ssh$ cat ./id_rsa.pub >>./authorized_keys chu888chu888@ubuntu2:~/.ssh$ ssh localhost #但是这里面有一个小问题就是,我是用chu888chu888这个用户做的,如果您想用 #hadoop用户登录的话,这个过程需要再来一次 hadoop@ubuntu2:~$ ssh hadoop@localhost
chu888chu888@ubuntu1:~$ source ~/.bashrc chu888chu888@ubuntu1:/usr/local/hadoop$ sudo nano /usr/local/hadoop/etc/hadoop/hadoop-env.sh chu888chu888@ubuntu1:~$ cd /usr/local/hadoop/
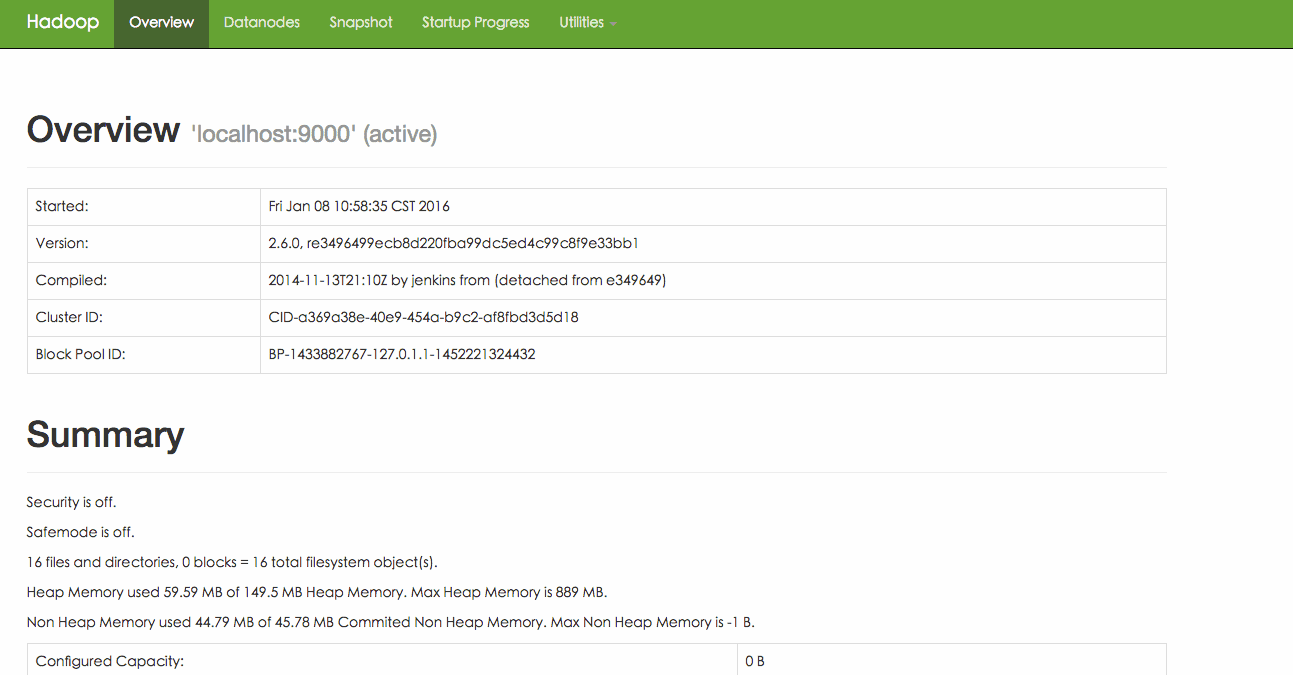
#hadoop安装后的查看hadoop的版本 hadoop@ubuntu2:/usr/local/hadoop$ ./bin/hadoop version Hadoop2.6.0 Subversionhttps://git-wip-us.apache.org/repos/asf/hadoop.git -r e3496499ecb8d220fba99dc5ed4c99c8f9e33bb1 Compiled by jenkins on 2014-11-13T21:10Z Compiledwith protoc 2.5.0 From source with checksum 18e43357c8f927c0695f1e9522859d6a This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-2.6.0.jar hadoop@ubuntu2:/usr/local/hadoop$
hadoop@ubuntu2:/usr/local/hadoop$ ./bin/hdfs namenode -format 16/01/1321:26:01 INFO namenode.NameNode:STARTUP_MSG: /************************************************************ STARTUP_MSG: Starting NameNode STARTUP_MSG: host = ubuntu2/127.0.1.1 STARTUP_MSG: args = [-format] STARTUP_MSG: version = 2.6.0 16/01/13 21:26:02 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 16/01/13 21:26:02 INFO util.ExitUtil: Exiting with status 0 16/01/13 21:26:02 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at ubuntu2/127.0.1.1 ************************************************************/
成功的话,会看到 “successfully formatted” 和 “Exitting with status 0″ 的提示,若为 “Exitting with status 1″ 则是出错。
>>>注意 在这一步时若提示 Error: JAVA_HOME is not set and could not be found. 的错误,则需要在文件 ./etc/hadoop/hadoop-env.sh 中设置 JAVA_HOME 变量,即在该文件中找到: export JAVA_HOME=${JAVA_HOME} 将这一行改为JAVA安装位置: export JAVA_HOME=/usr/lib/jvm/ 再重新尝试格式化即可。
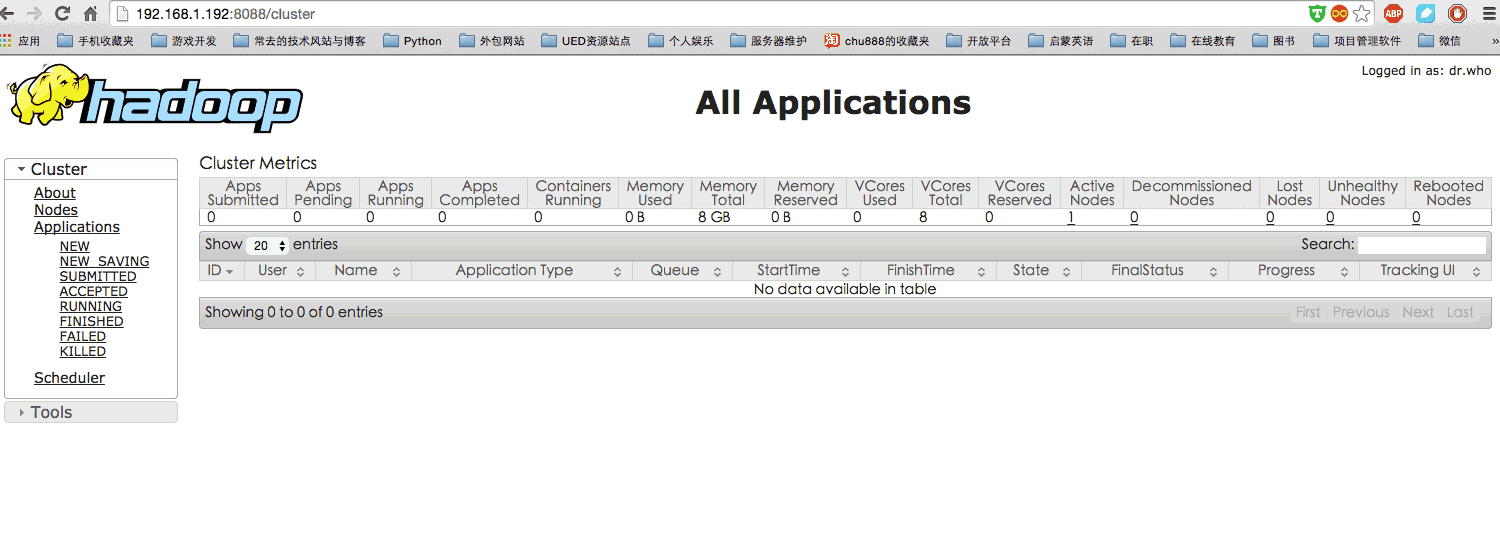
#接着开启 NaneNode 和 DataNode 守护进程。 hadoop@ubuntu2:/usr/local/hadoop$ ./sbin/start-dfs.sh 16/01/1321:29:20 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Starting namenodes on [localhost] localhost: starting namenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-namenode-ubuntu2.out localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-hadoop-datanode-ubuntu2.out Starting secondary namenodes [0.0.0.0] The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established. ECDSA key fingerprint is 87:f6:48:6b:0f:52:1f:27:3f:62:8c:c0:39:2d:87:e3. Are you sure you want to continue connecting (yes/no)? yes 0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts. 0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-hadoop-secondarynamenode-ubuntu2.out 16/01/1321:29:39 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
启动时可能会出现如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable WARN 提示可以忽略,并不会影响正常使用。
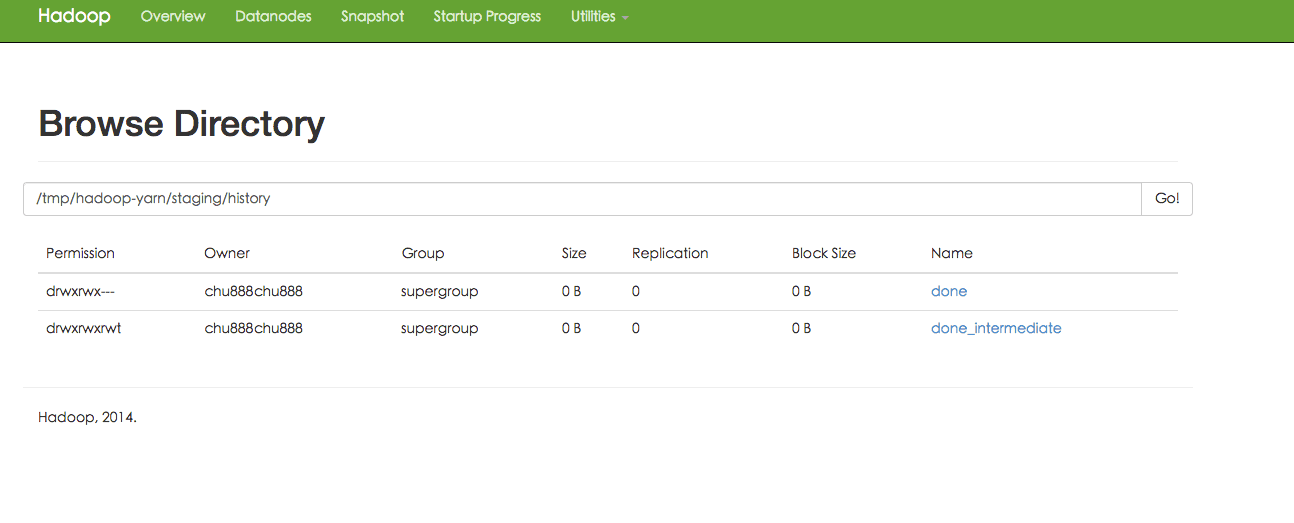
hadoop@ubuntu2:/usr/local/hadoop$ ./bin/hdfs dfs -mkdir -p /user/hadoop 16/01/1321:37:47WARNutil.NativeCodeLoader:Unable to load native-hadoop library for your platform... using builtin-java classes where applicable hadoop@ubuntu2:/usr/local/hadoop$