
一、基本概念一个典型的Hbase Table 表如下: 1.1 Row Key (行键)Row Key是用来检索记录的主键。想要访问HBase Table中的数据,只有以下三种方式: 通过指定的Row Key进行访问; 通...

一、基本概念一个典型的Hbase Table 表如下: 1.1 Row Key (行键)Row Key是用来检索记录的主键。想要访问HBase Table中的数据,只有以下三种方式: 通过指定的Row Key进行访问; 通...
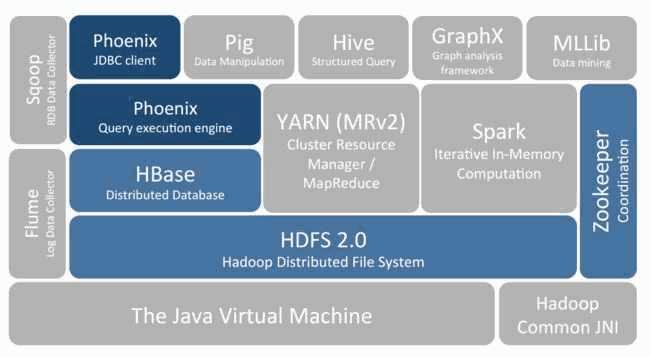
一、Hadoop的局限HBase是一个构建在Hadoop文件系统之上的面向列的数据库管理系统。 要想明白为什么产生HBase,就需要先了解一下Hadoop存在的限制?Hadoop可以通过HDFS来存储结构化、半结构甚至非结构化...
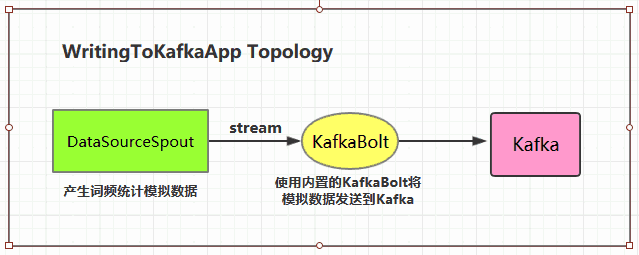
一、整合说明Storm官方对Kafka的整合分为两个版本,官方说明文档分别如下: Storm Kafka Integration : 主要是针对0.8.x版本的Kafka提供整合支持; Storm Kafka Integration...
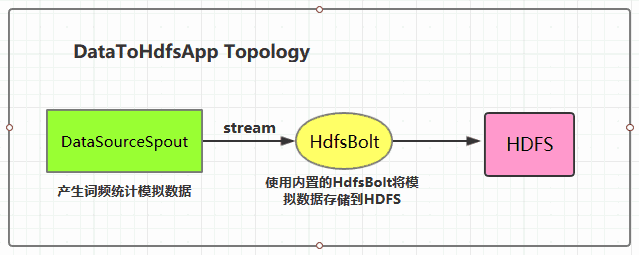
一、Storm集成HDFS1.1 项目结构 本用例源码下载地址:storm-hdfs-integration 1.2 项目主要依赖项目主要依赖如下,有两个地方需要注意: 这里由于我服务器上安装的是CDH版本的Hadoop,...
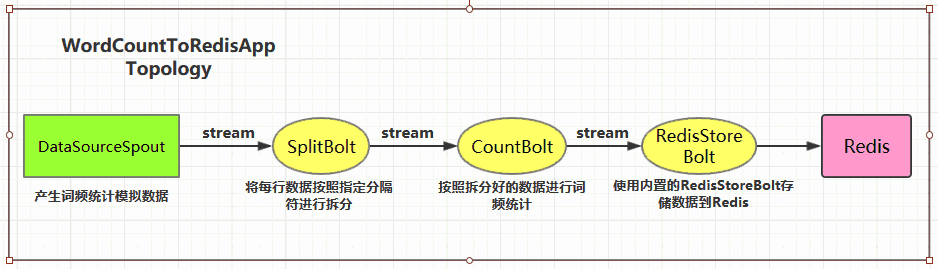
一、简介Storm-Redis提供了Storm与Redis的集成支持,你只需要引入对应的依赖即可使用: 123456<dependency> <groupId>org.apache.storm</g...
一、简介在将Storm Topology提交到服务器集群运行时,需要先将项目进行打包。本文主要对比分析各种打包方式,并将打包过程中需要注意的事项进行说明。主要打包方式有以下三种: 第一种:不加任何插件,直接使用mvn package...
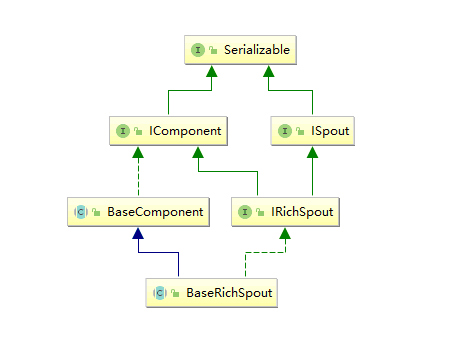
一、简介下图为Strom的运行流程图,在开发Storm流处理程序时,我们需要采用内置或自定义实现spout(数据源)和bolt(处理单元),并通过TopologyBuilder将它们之间进行关联,形成Topology。 二、I...
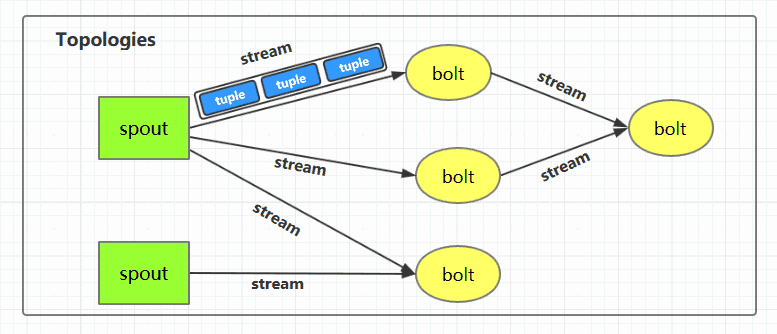
一、Storm核心概念 1.1 Topologies(拓扑)一个完整的Storm流处理程序被称为Storm topology(拓扑)。它是一个是由Spouts 和Bolts通过Stream连接起来的有向无环图,Storm会保持...
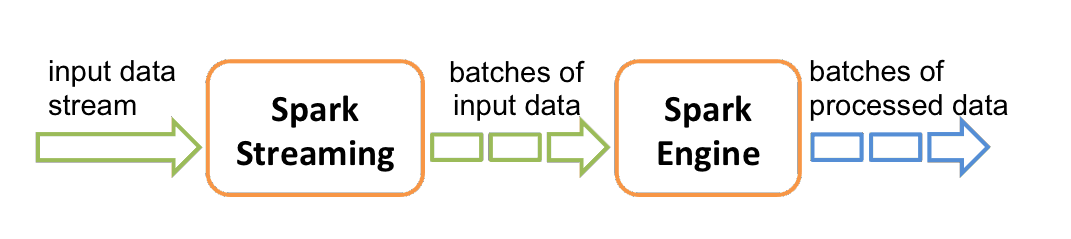
一、Storm1.1 简介Storm 是一个开源的分布式实时计算框架,可以以简单、可靠的方式进行大数据流的处理。通常用于实时分析,在线机器学习、持续计算、分布式RPC、ETL等场景。Storm具有以下特点: 支持水平横向扩展; 具有...
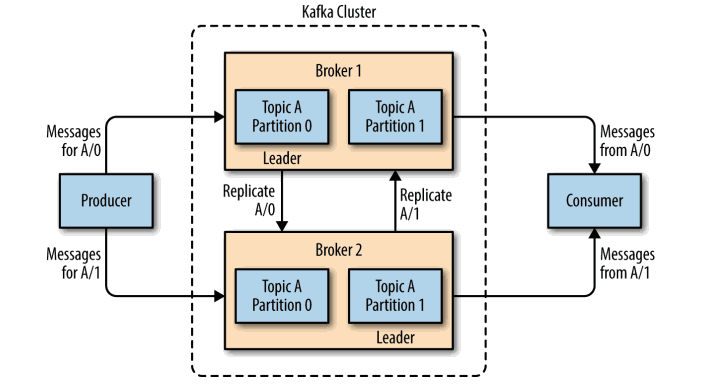
一、Kafka集群Kafka使用Zookeeper来维护集群成员(brokers)的信息。每个broker都有一个唯一标识broker.id,用于标识自己在集群中的身份,可以在配置文件server.properties中进行配置,或者...