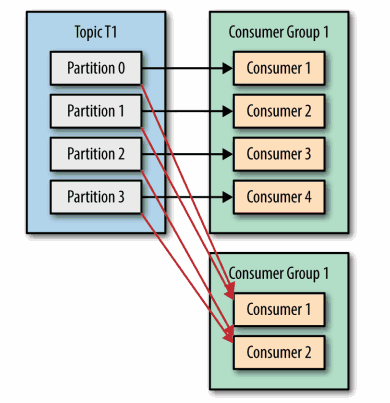
一、消费者和消费者群组在Kafka中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka之所以要引入消费者群组这个概念是因为Kafka消费者经常会做一些高延迟的操作,比如把数据写到数据库或...

一、消费者和消费者群组在Kafka中,消费者通常是消费者群组的一部分,多个消费者群组共同读取同一个主题时,彼此之间互不影响。Kafka之所以要引入消费者群组这个概念是因为Kafka消费者经常会做一些高延迟的操作,比如把数据写到数据库或...
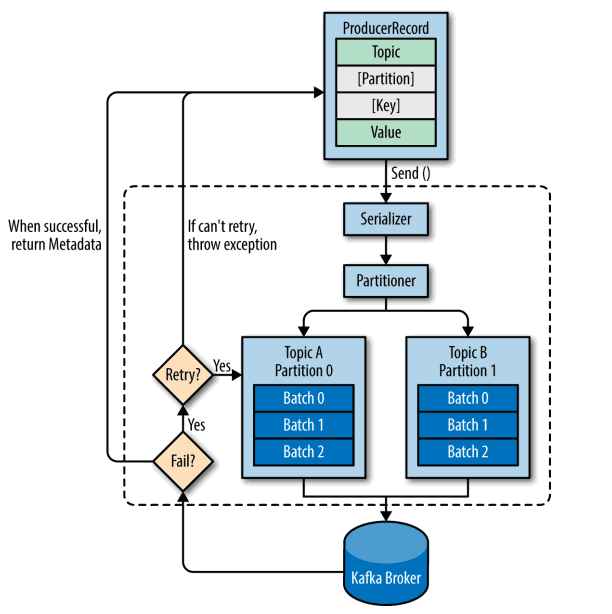
一、生产者发送消息的过程首先介绍一下Kafka生产者发送消息的过程: Kafka会将发送消息包装为ProducerRecord对象, ProducerRecord对象包含了目标主题和要发送的内容,同时还可以指定键和分区。在发送Pro...
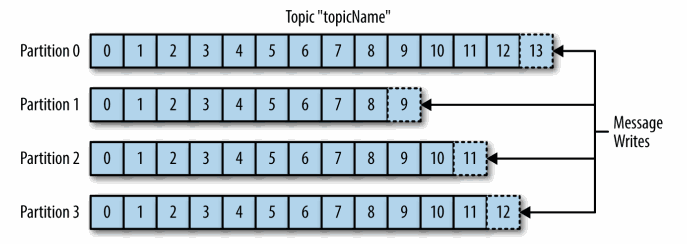
一、简介ApacheKafka是一个分布式的流处理平台。它具有以下特点: 支持消息的发布和订阅,类似于RabbtMQ、ActiveMQ等消息队列; 支持数据实时处理; 能保证消息的可靠性投递; 支持消息的持久化存储,并通过多副本分布...
一、版本说明Spark针对Kafka的不同版本,提供了两套整合方案:spark-streaming-kafka-0-8和spark-streaming-kafka-0-10,其主要区别如下: spark-streaming-k...
一、简介Apache Flume是一个分布式,高可用的数据收集系统,可以从不同的数据源收集数据,经过聚合后发送到分布式计算框架或者存储系统中。Spark Straming提供了以下两种方式用于Flume的整合。 二、推送式方法在推送式...
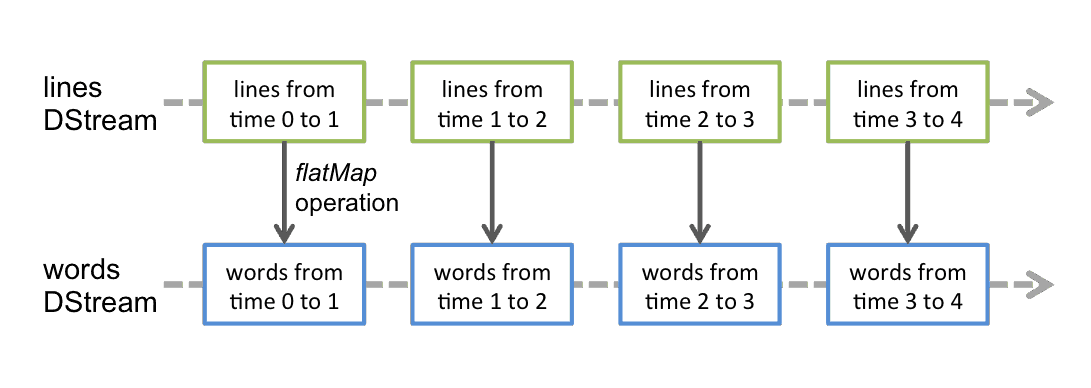
一、案例引入这里先引入一个基本的案例来演示流的创建:获取指定端口上的数据并进行词频统计。项目依赖和代码实现如下: 12345<dependency> <groupId>org.apache.spark&l...
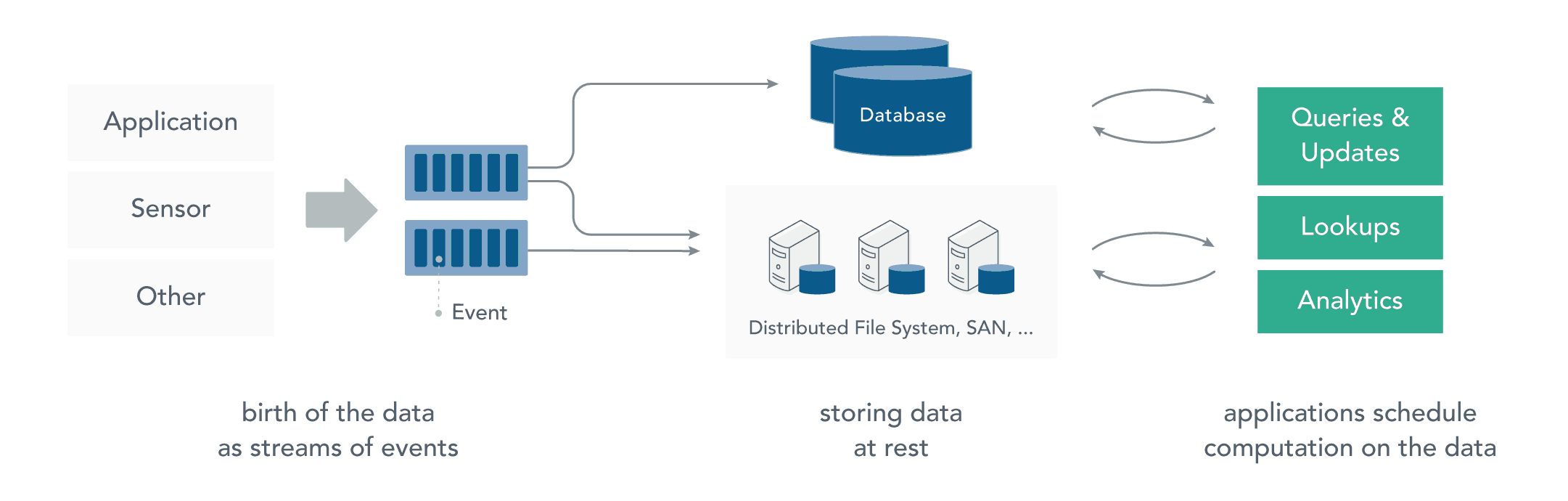
一、流处理1.1 静态数据处理在流处理之前,数据通常存储在数据库,文件系统或其他形式的存储系统中。应用程序根据需要查询数据或计算数据。这就是传统的静态数据处理架构。Hadoop采用HDFS进行数据存储,采用MapReduce进行数据查...
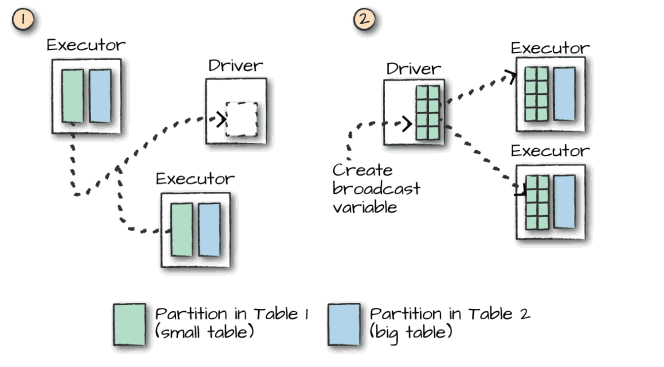
一、 数据准备本文主要介绍Spark SQL的多表连接,需要预先准备测试数据。分别创建员工和部门的Datafame,并注册为临时视图,代码如下: 1234567val spark = SparkSession.builder().ap...
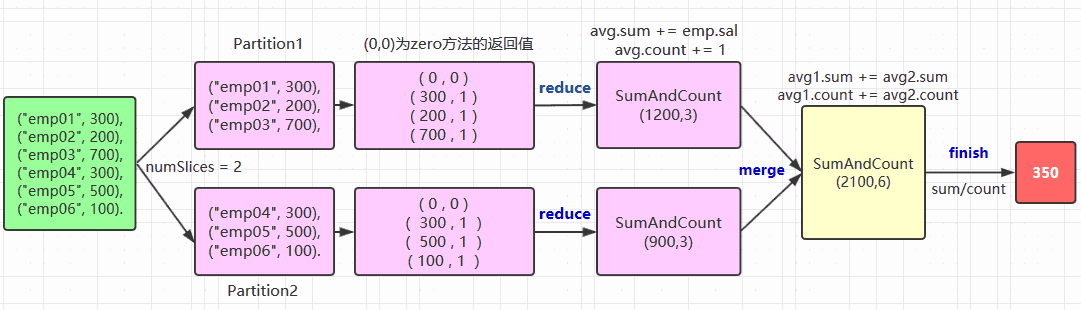
一、简单聚合1.1 数据准备12345678// 需要导入spark sql内置的函数包import org.apache.spark.sql.functions._val spark = SparkSession.builder()...

一、简介1.1 多数据源支持Spark支持以下六个核心数据源,同时Spark社区还提供了多达上百种数据源的读取方式,能够满足绝大部分使用场景。 CSV JSON Parquet ORC JDBC/ODBC connecti...