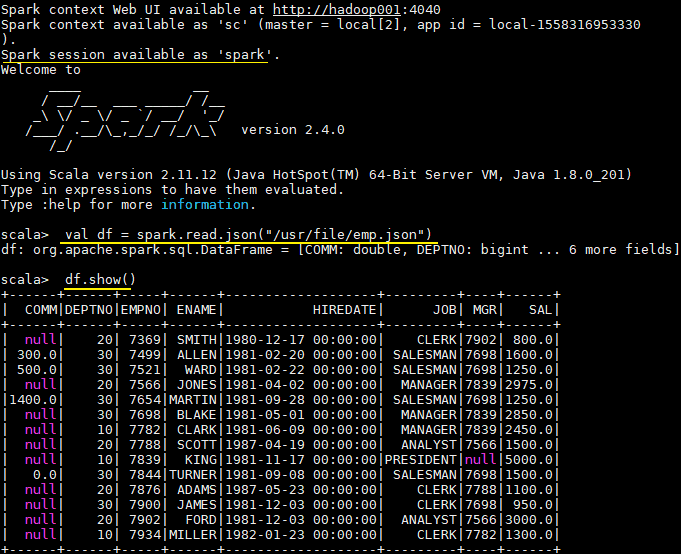
一、创建DataFrame和Dataset1.1 创建DataFrameSpark中所有功能的入口点是SparkSession,可以使用SparkSession.builder()创建。创建后应用程序就可以从现有RDD,Hive表或S...

一、创建DataFrame和Dataset1.1 创建DataFrameSpark中所有功能的入口点是SparkSession,可以使用SparkSession.builder()创建。创建后应用程序就可以从现有RDD,Hive表或S...

一、Spark SQL简介Spark SQL是Spark中的一个子模块,主要用于操作结构化数据。它具有以下特点: 能够将SQL查询与Spark程序无缝混合,允许您使用SQL或DataFrame API对结构化数据进行查询; 支持多种...
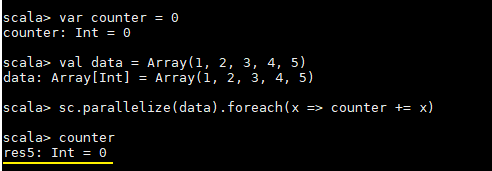
一、简介在Spark中,提供了两种类型的共享变量:累加器(accumulator)与广播变量(broadcast variable): 累加器:用来对信息进行聚合,主要用于累计计数等场景; 广播变量:主要用于在节点间高效分发大对象。...
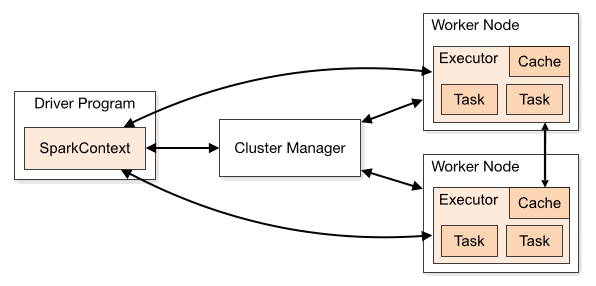
一、作业提交1.1 spark-submitSpark所有模式均使用spark-submit命令提交作业,其格式如下: 12345678./bin/spark-submit \ --class <main-class>...
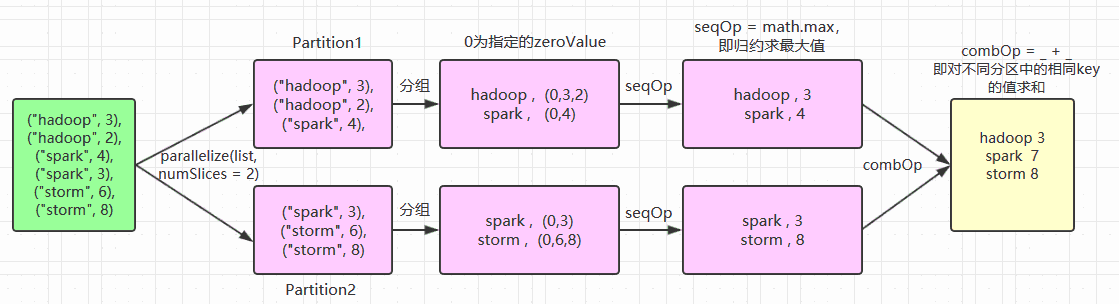
一、Transformationspark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 func 函数,并生成新的R...
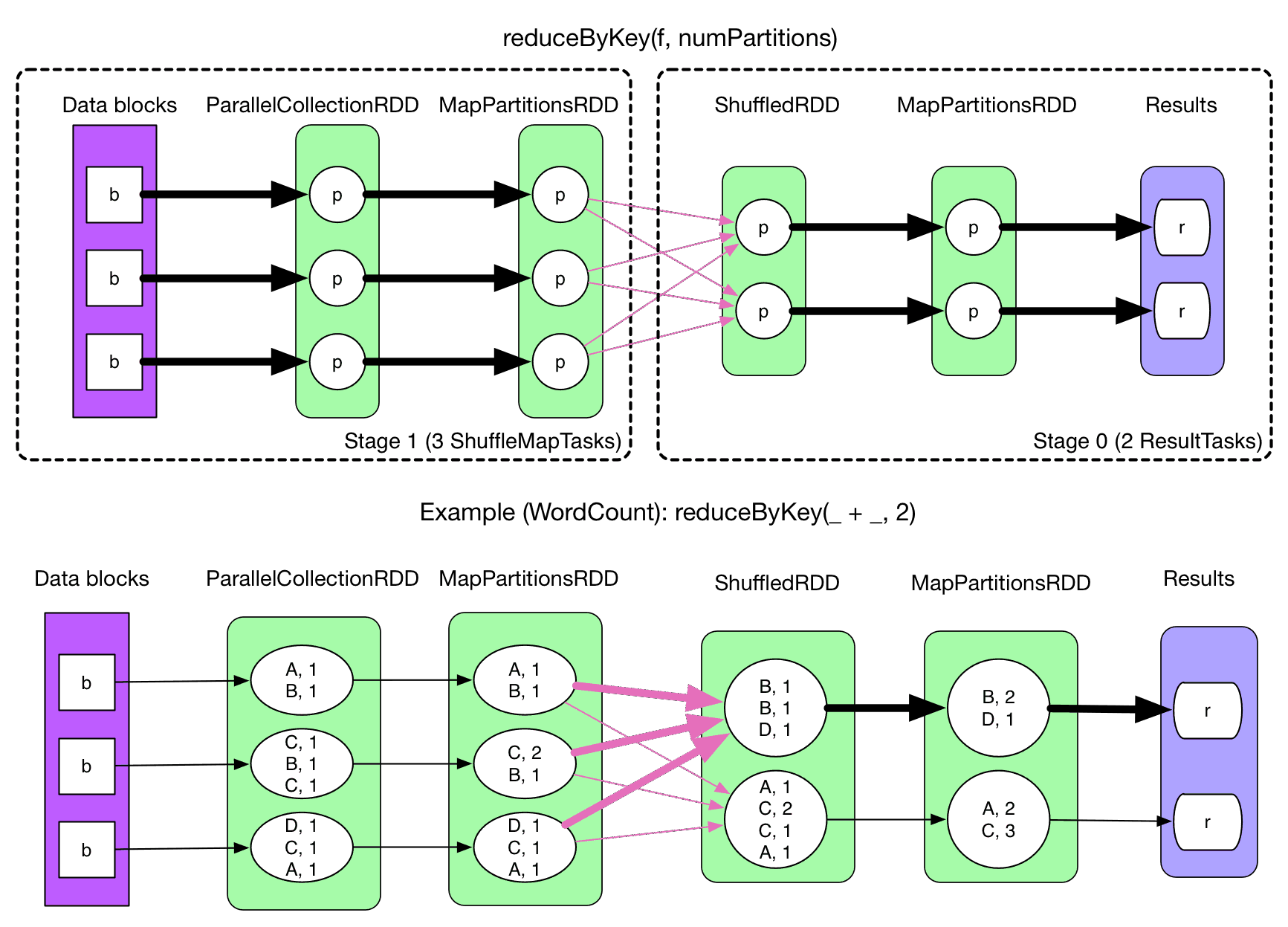
一、RDD简介RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他RDD转换而来,它具有以下特性: 一个RDD由一个...
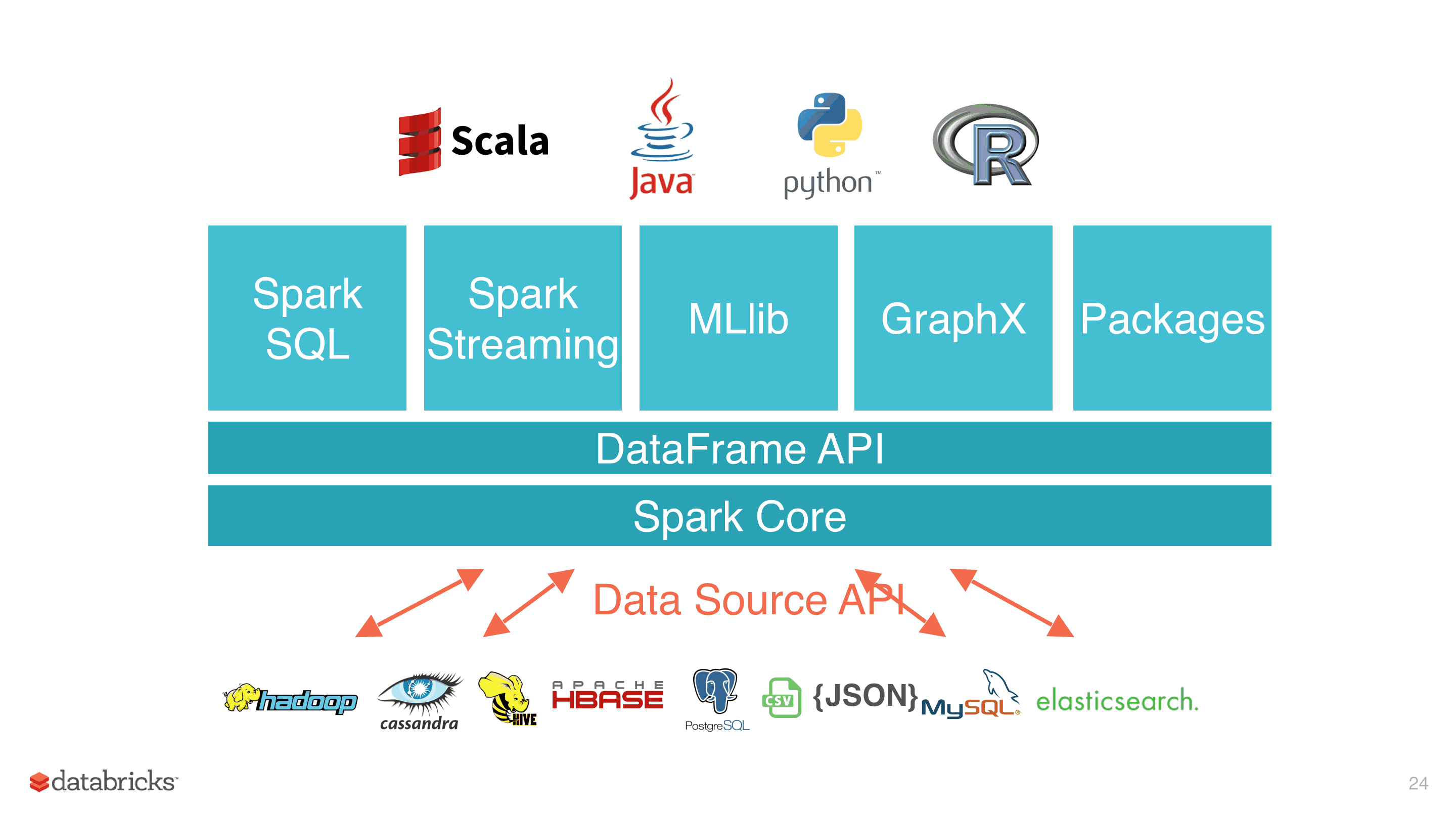
一、简介Spark于2009年诞生于加州大学伯克利分校AMPLab,2013年被捐赠给Apache软件基金会,2014年2月成为Apache的顶级项目。相对于MapReduce的批处理计算,Spark可以带来上百倍的性能提升,因此它成...
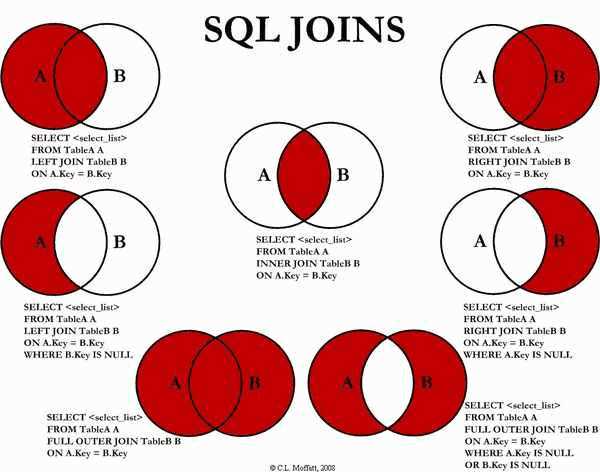
一、数据准备为了演示查询操作,这里需要预先创建三张表,并加载测试数据。 数据文件emp.txt和dept.txt可以从本仓库的resources目录下载。 1.1 员工表1234567891011121314 -- 建表语句 CR...
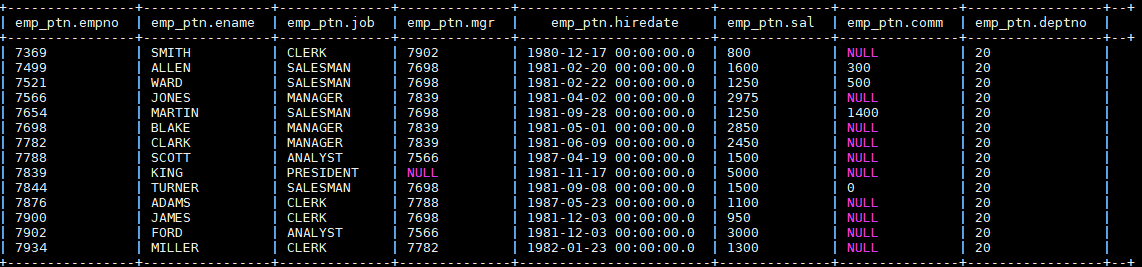
一、加载文件数据到表1.1 语法123LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol...
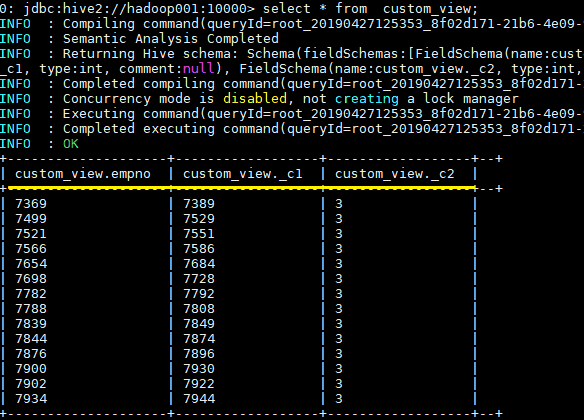
一、视图1.1 简介Hive 中的视图和RDBMS中视图的概念一致,都是一组数据的逻辑表示,本质上就是一条SELECT语句的结果集。视图是纯粹的逻辑对象,没有关联的存储(Hive 3.0.0引入的物化视图除外),当查询引用视图时,Hi...