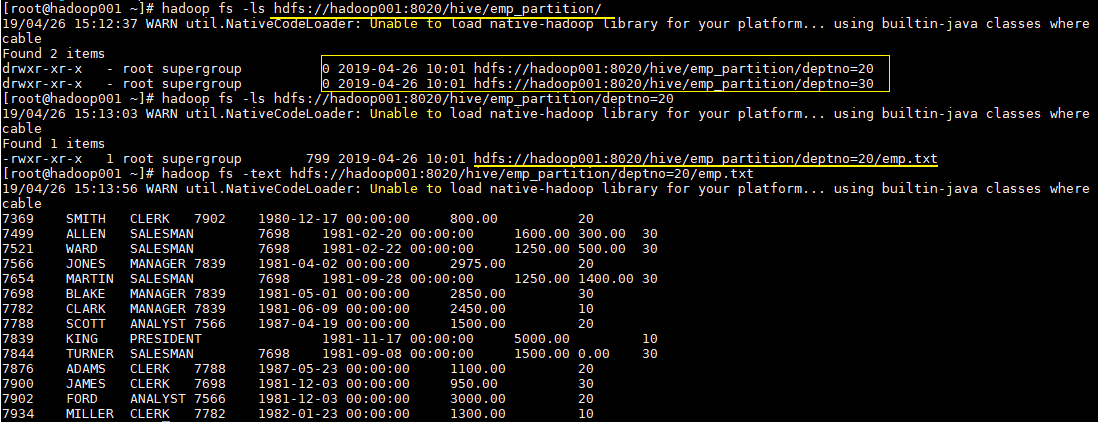
一、分区表1.1 概念Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中。如果查询的where字句的中包含分区条件...

一、分区表1.1 概念Hive中的表对应为HDFS上的指定目录,在查询数据时候,默认会对全表进行扫描,这样时间和性能的消耗都非常大。 分区为HDFS上表目录的子目录,数据按照分区存储在子目录中。如果查询的where字句的中包含分区条件...
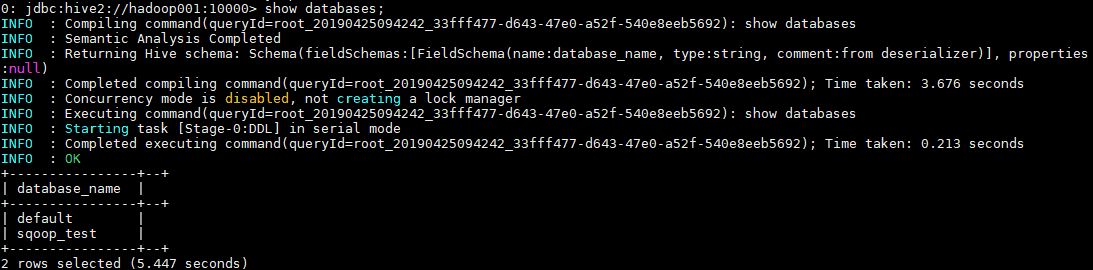
一、Database1.1 查看数据列表1show databases; 1.2 使用数据库1USE database_name; 1.3 新建数据库语法: 1234CREATE (DATABASE|SCHEMA) [IF...
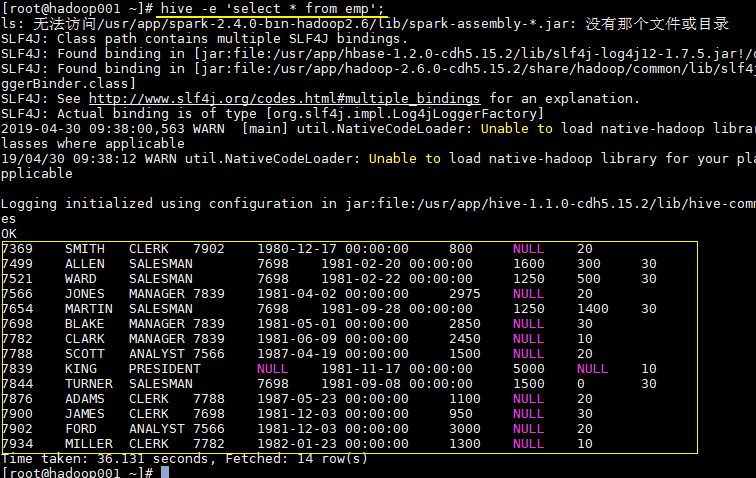
一、Hive CLI1.1 Help使用hive -H或者 hive --help命令可以查看所有命令的帮助,显示如下: 12345678910111213usage: hive -d,--define <key=value&g...
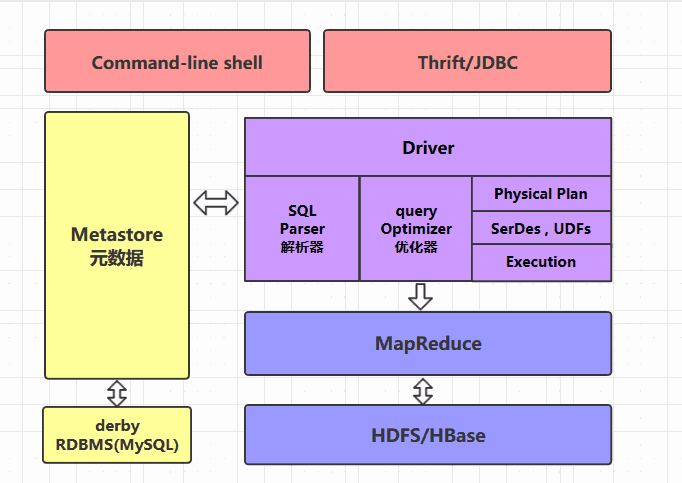
一、简介Hive是一个构建在Hadoop之上的数据仓库,它可以将结构化的数据文件映射成表,并提供类SQL查询功能,用于查询的SQL语句会被转化为MapReduce作业,然后提交到Hadoop上运行。 特点: 简单、容易上手(提供了类...

一、 简介想要使用HDFS API,需要导入依赖hadoop-client。如果是CDH版本的Hadoop,还需要额外指明其仓库地址: 1234567891011121314151617181920212223242526272829...
HDFS文件操作       HDFS是一种文件系统,专为MapReduce这类框架下的大规模分布式数据处理而设计,你可以把一个大数据集(比如说100TB)在HDFS中存储为单个文件,而大多数其...
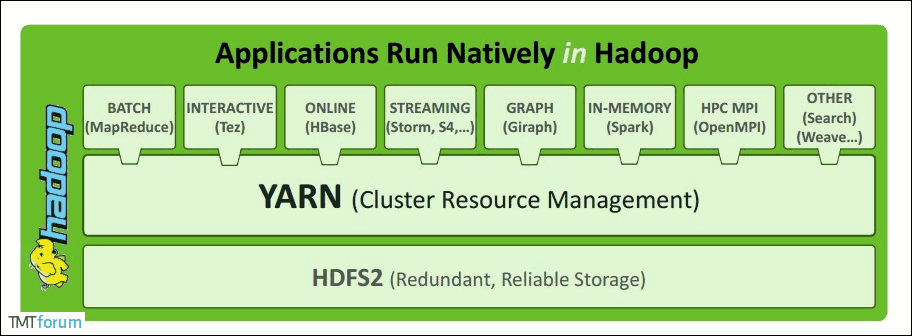
一、hadoop yarn 简介Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统。用户可以将各种服务框架部署在YARN上,由YARN进行统一地...
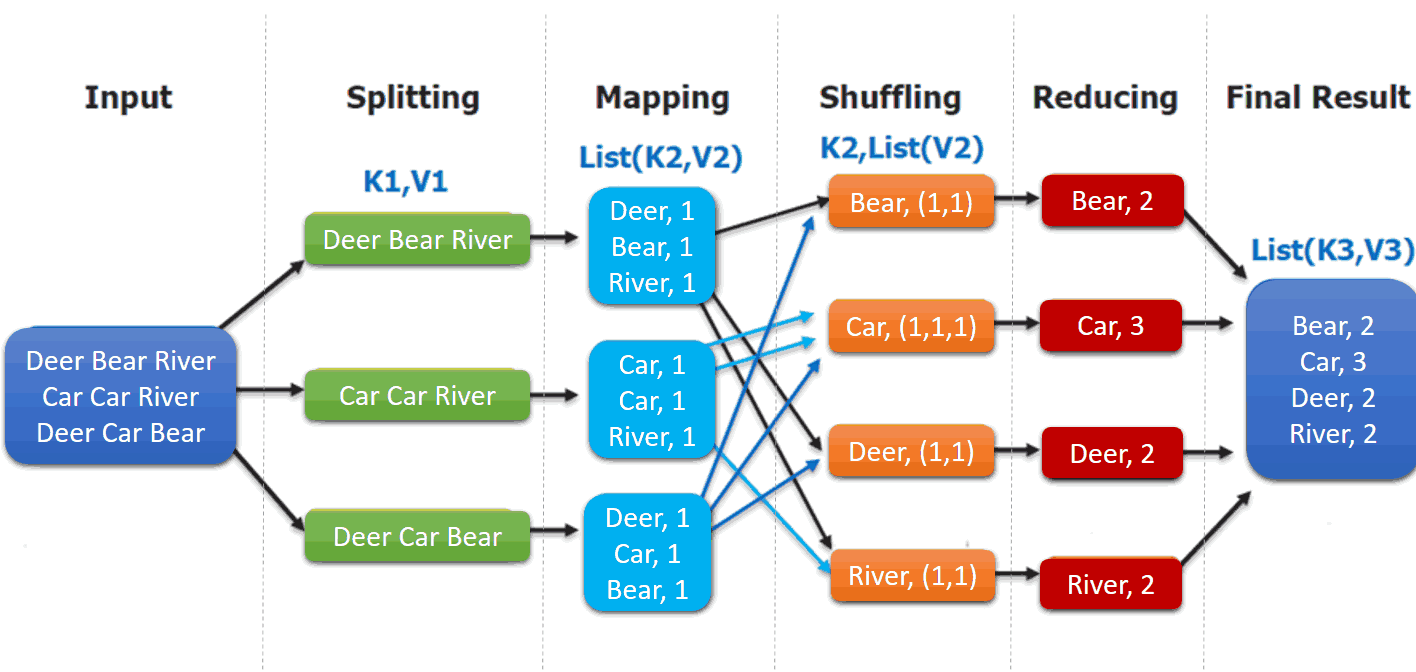
一、MapReduce概述Hadoop MapReduce是一个分布式计算框架,用于编写批处理应用程序。编写好的程序可以提交到Hadoop集群上用于并行处理大规模的数据集。 MapReduce作业通过将输入的数据集拆分为独立的块,这些...
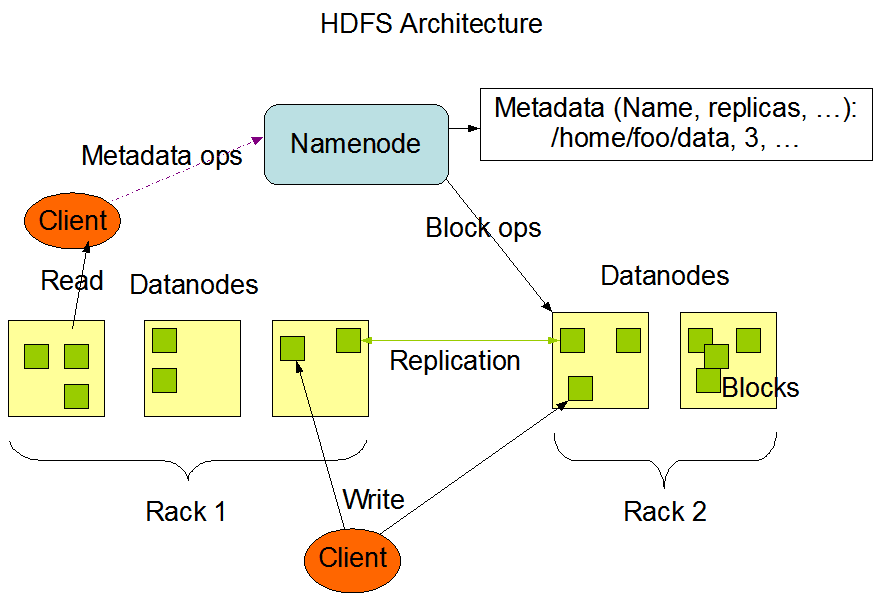
一、介绍HDFS (Hadoop Distributed File System)是Hadoop下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。 二、HDFS 设计原理 2.1 HDFS 架构HDFS ...