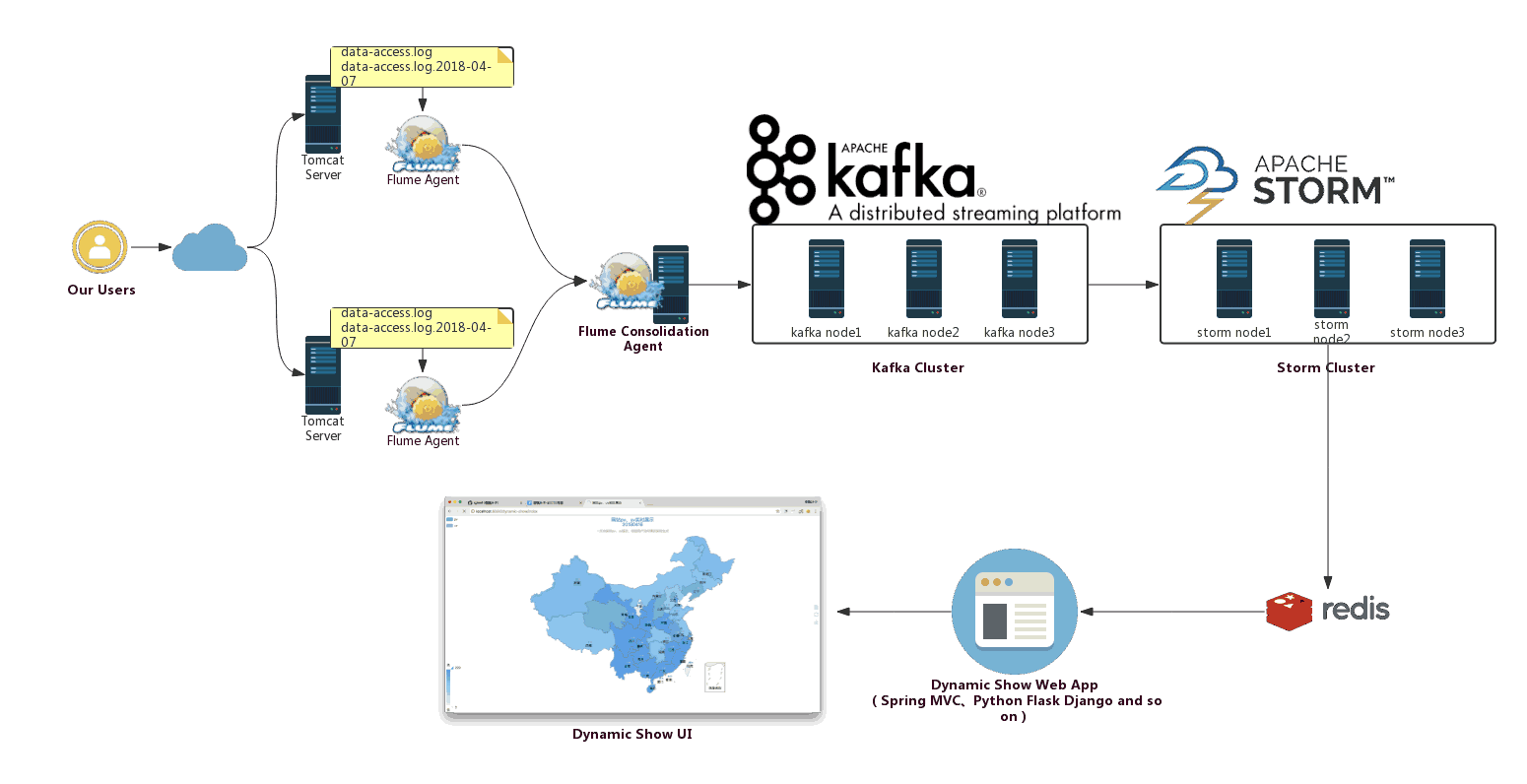
一、背景先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将Flume聚合后的数据输入到Storm等分布式计算框架...
一、背景先说一下,为什么要使用 Flume + Kafka? 以实时流处理项目为例,由于采集的数据量可能存在峰值和峰谷,假设是一个电商项目,那么峰值通常出现在秒杀时,这时如果直接将Flume聚合后的数据输入到Storm等分布式计算框架...
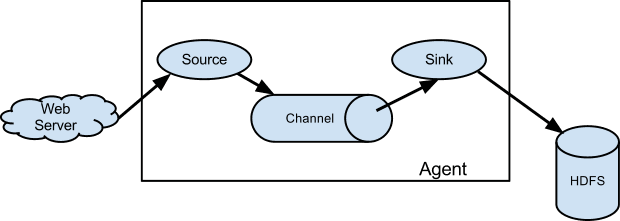
一、Flume简介Apache Flume是一个分布式,高可用的数据收集系统。它可以从不同的数据源收集数据,经过聚合后发送到存储系统中,通常用于日志数据的收集。Flume 分为 NG 和 OG (1.0 之前)两个版本,NG在OG的基...
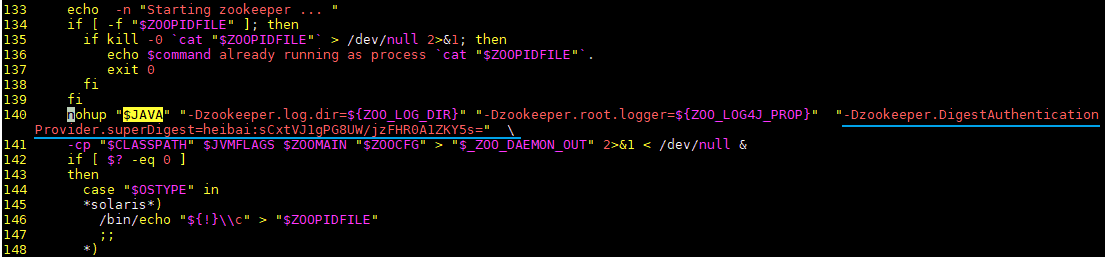
一、前言为了避免存储在Zookeeper上的数据被其他程序或者人为误修改,Zookeeper提供了ACL(Access Control Lists)进行权限控制。只有拥有对应权限的用户才可以对节点进行增删改查等操作。下文分别介绍使用原...
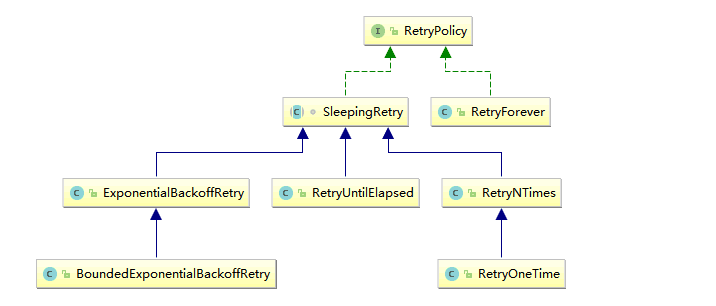
一、基本依赖Curator是Netflix公司开源的一个Zookeeper客户端,目前由Apache进行维护。与Zookeeper原生客户端相比,Curator的抽象层次更高,功能也更加丰富,是目前Zookeeper使用范围最广的Ja...

一、节点增删改查1.1 启动服务和连接服务12345# 启动服务bin/zkServer.sh start#连接服务 不指定服务地址则默认连接到localhost:2181zkCli.sh -server hadoop001:2181...
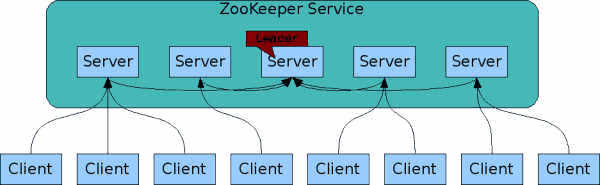
一、Zookeeper简介Zookeeper是一个开源的分布式协调服务,目前由Apache进行维护。Zookeeper可以用于实现分布式系统中常见的发布/订阅、负载均衡、命令服务、分布式协调/通知、集群管理、Mas...

一、前言使用Spring+Mybatis操作Phoenix和操作其他的关系型数据库(如Mysql,Oracle)在配置上是基本相同的,下面会分别给出Spring/Spring Boot 整合步骤,完整代码见本仓库: Spr...
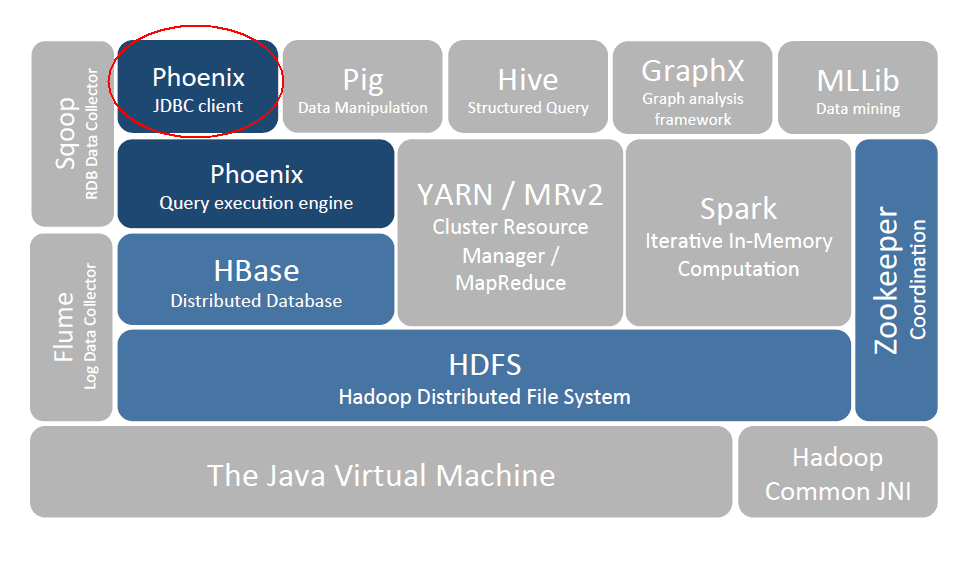
一、Phoenix简介Phoenix是HBase的开源SQL中间层,它允许你使用标准JDBC的方式来操作HBase上的数据。在Phoenix之前,如果你要访问HBase,只能调用它的Java API,但相比于使用一行SQL就能实现数据...
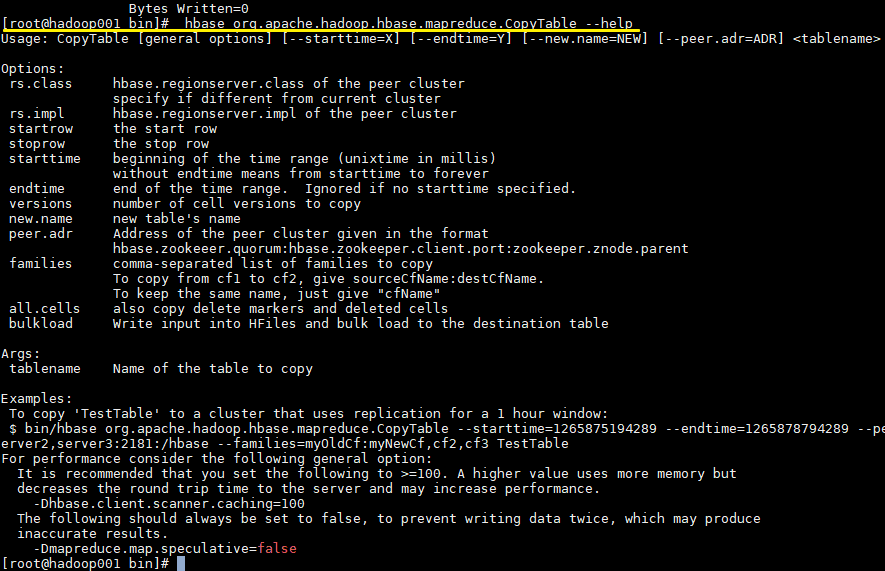
一、前言本文主要介绍Hbase常用的三种简单的容灾备份方案,即CopyTable、Export/Import、Snapshot。分别介绍如下: 二、CopyTable2.1 简介CopyTable可以将现有表的数据复制到新表...
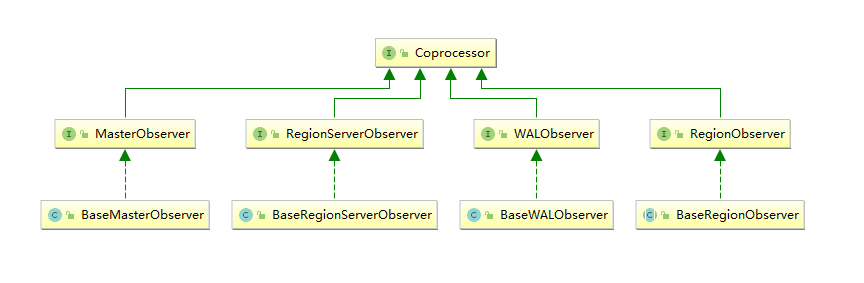
一、简述在使用HBase时,如果你的数据量达到了数十亿行或数百万列,此时能否在查询中返回大量数据将受制于网络的带宽,即便网络状况允许,但是客户端的计算处理也未必能够满足要求。在这种情况下,协处理器(Coprocessors)应运而生。...