一、作业提交1.1 spark-submitSpark所有模式均使用spark-submit命令提交作业,其格式如下: 12345678./bin/spark-submit \ --class <main-class>...
一、作业提交1.1 spark-submitSpark所有模式均使用spark-submit命令提交作业,其格式如下: 12345678./bin/spark-submit \ --class <main-class>...
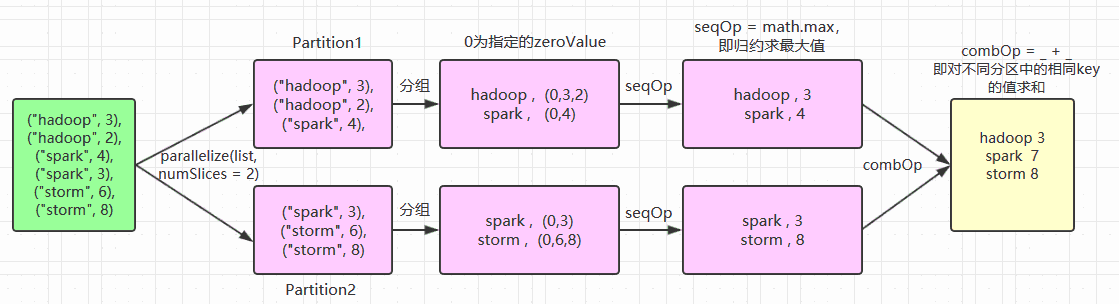
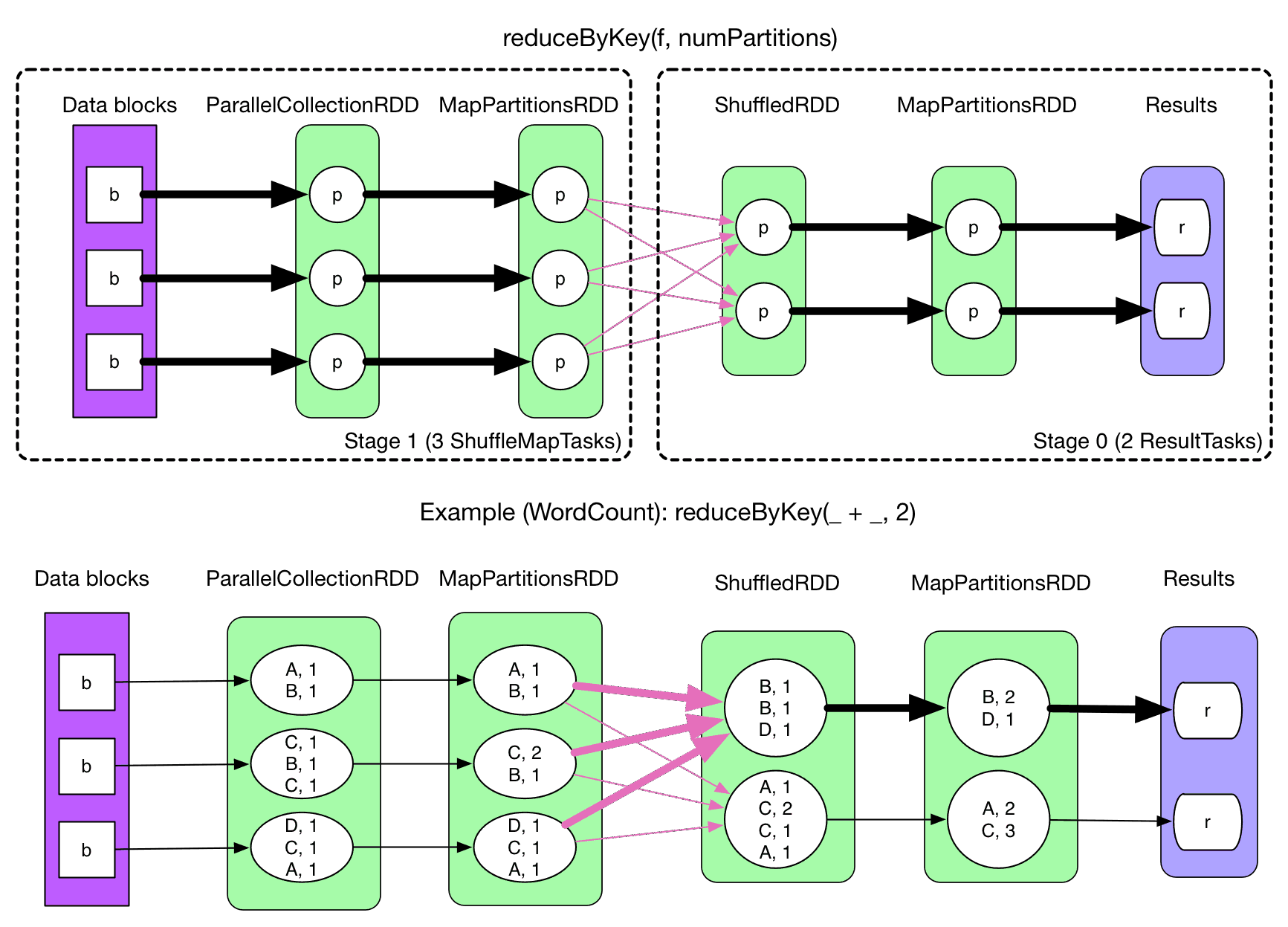
一、Transformationspark常用的Transformation算子如下表: Transformation算子 Meaning(含义) map(func) 对原RDD中每个元素运用 func 函数,并生成新的R...
一、RDD简介RDD全称为Resilient Distributed Datasets,是Spark最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他RDD转换而来,它具有以下特性: 一个RDD由一个...
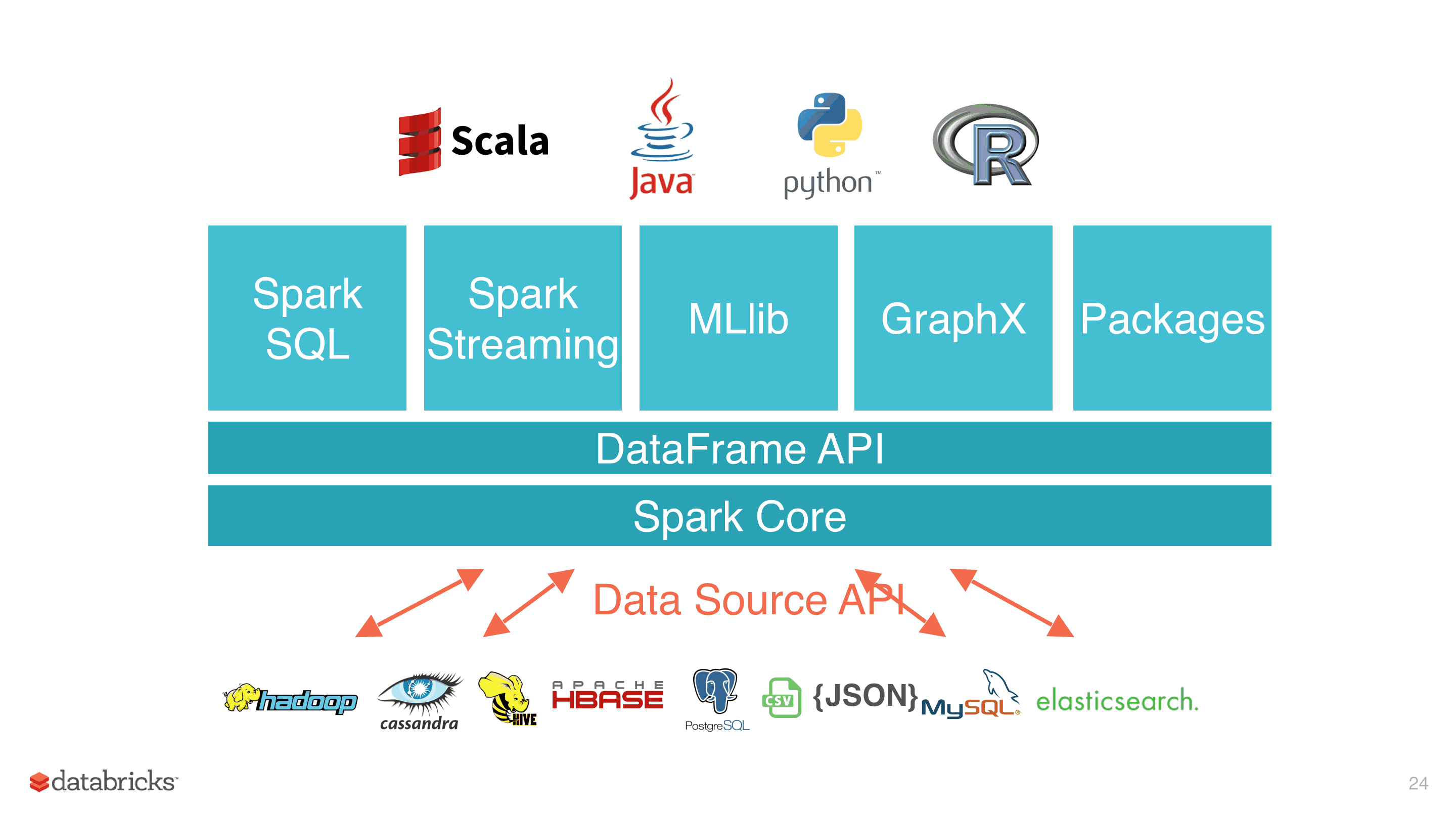
一、简介Spark于2009年诞生于加州大学伯克利分校AMPLab,2013年被捐赠给Apache软件基金会,2014年2月成为Apache的顶级项目。相对于MapReduce的批处理计算,Spark可以带来上百倍的性能提升,因此它成...
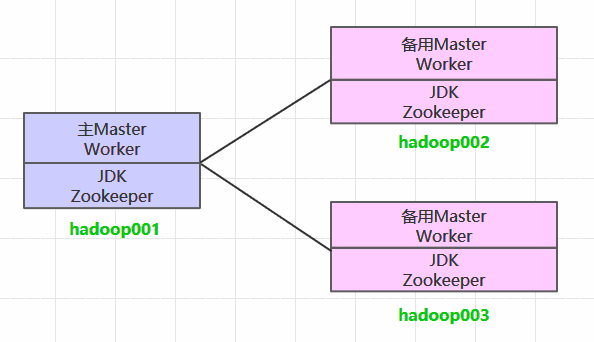
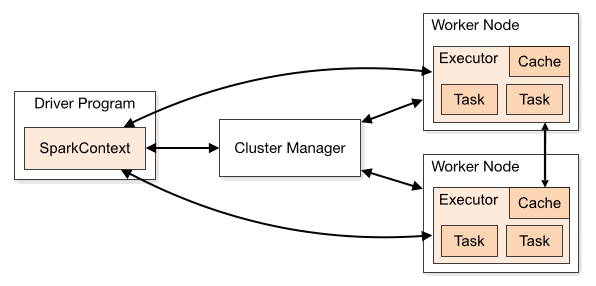
一、集群规划这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop003上分别部署备用的Master服务,...
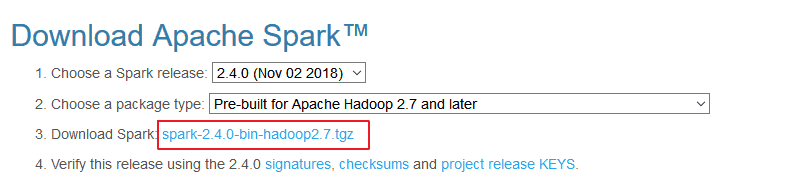
一、安装Spark1.1 下载并解压官方下载地址:http://spark.apache.org/downloads.html ,选择Spark版本和对应的Hadoop版本后再下载: 解压安装包: 12# tar -zxvf ...

概述       谈到大数据,相信大家对Hadoop和Apache Spark这两个名字并不陌生。但我们往往对它们的理解只是提留在字面上,并没有对它们进行深入的思考,下面不妨跟我一块看下它们究竟...
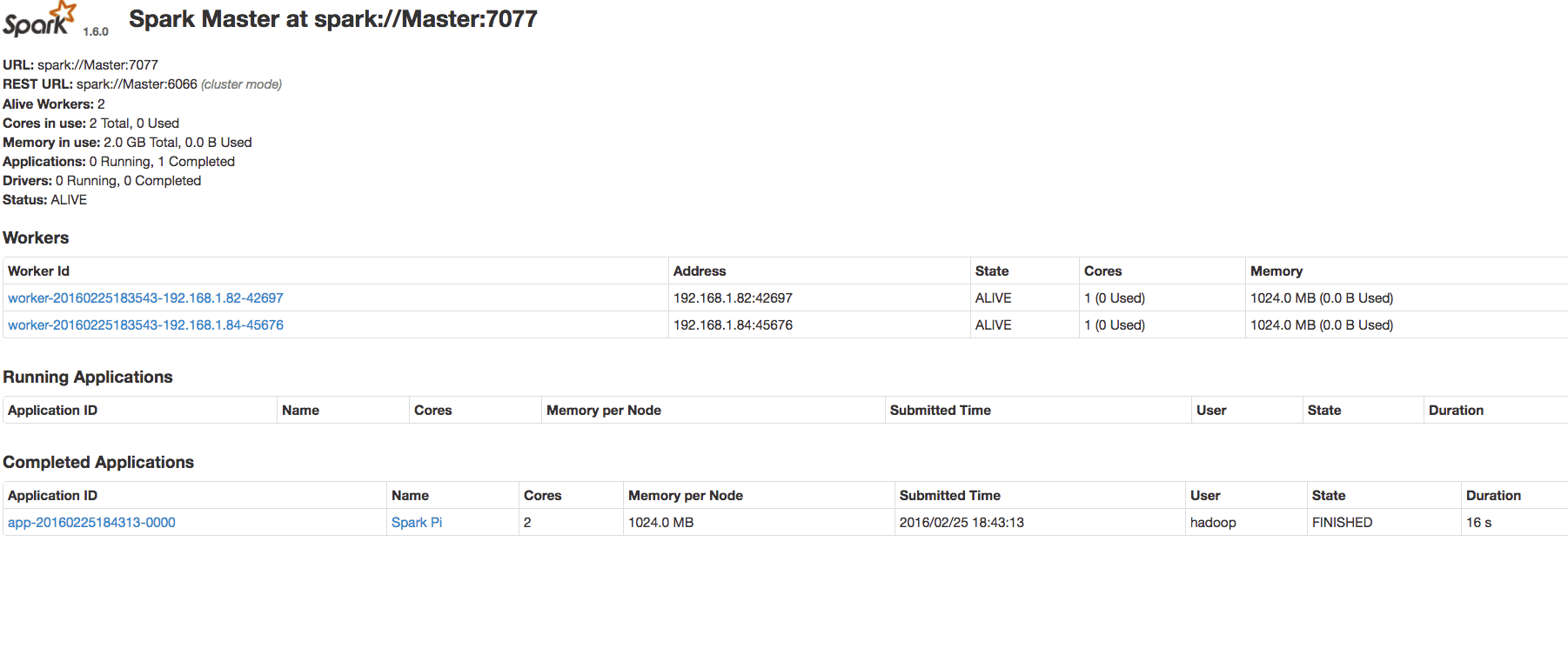
1. 软件环境123Ubuntu 14.04.1 LTS (GNU/Linux 3.13.0-32-generic x86_64)Hadoop: 2.6.0Spark: 1.6.0 2. 环境准备修改主机名 我们将搭建1个Maste...
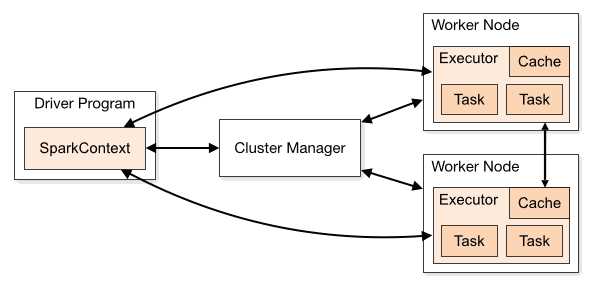
一. Apache Spark是什么?Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。S...
MySQL创建存储offset的表格123456789mysql> use testmysql> create table hlw_offset( topic varchar(32), grou...