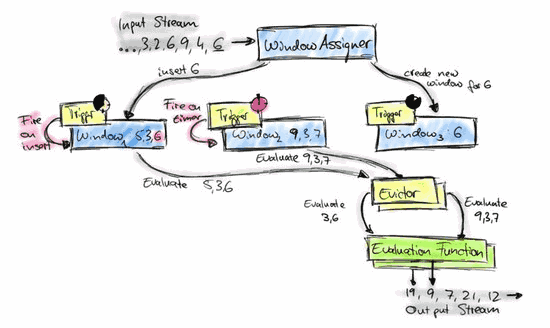
1、 Window & Time 介绍Apache Flink(以下简称 Flink) 是一个天然支持无限流数据处理的分布式计算框架,在 Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 F...
1、 Window & Time 介绍Apache Flink(以下简称 Flink) 是一个天然支持无限流数据处理的分布式计算框架,在 Flink 中 Window 可以将无限流切分成有限流,是处理有限流的核心组件,现在 F...

Flink附带了一个集成的交互式Scala Shell。它可以在本地设置和群集设置中使用。 要将shell与集成的Flink集群一起使用,只需执行: 1bin/start-scala-shell.sh local 在二进制Flink...
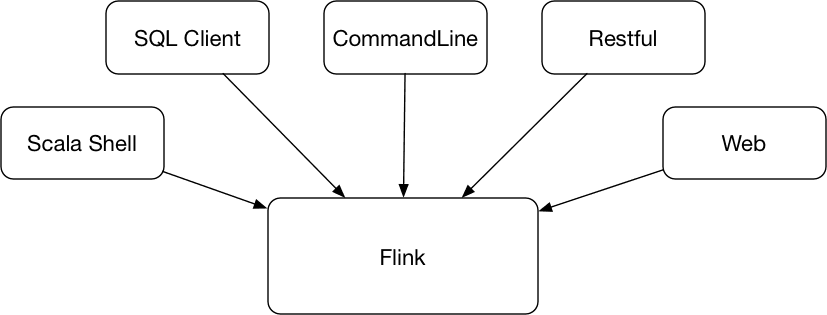
1. 概要如下图所示,Flink 提供了丰富的客户端操作来提交任务和与任务进行交互,包括 Flink 命令行,Scala Shell,SQL Client,Restful API 和 Web。Flink 首先提供的最重要的是命令行,其...
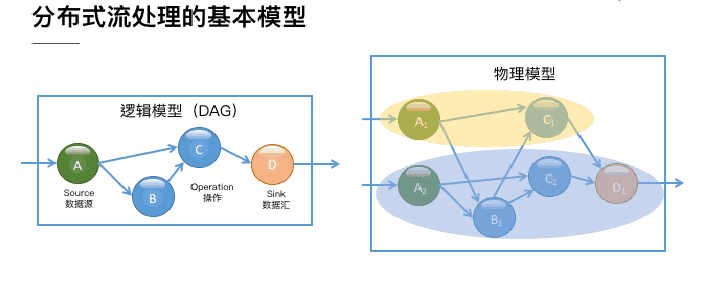
1. 流处理基本概念对于什么是流处理,从不同的角度有不同的定义。其实流处理与批处理这两个概念是对立统一的,它们的关系有点类似于对于 Java 中的 ArrayList 中的元素,是直接看作一个有限数据集并用下标去访问,还是用迭代器去访...
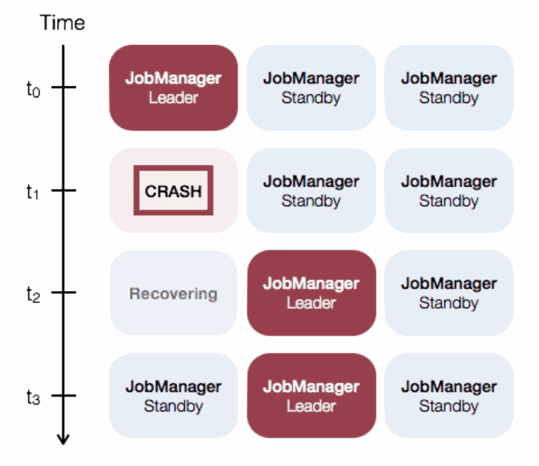
本文主要内容包括: Flink 开发环境的部署和配置 运行 Flink 应用(包括:单机 Standalone 模式、多机 Standalone 模式和 Yarn 集群模式) 一、Flink 开发环境部署和配置Flink 是一个以...

一、Apache Flink 的定义、架构及原理Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。 1. Flink A...
以下示例程序展示了Flink的不同应用程序,从简单的字数统计到图形算法。代码示例说明了Flink的DataSet API的使用。 可以在Flink源存储库的flink-examples-batch模块中找到以下和更多示例的完整源代码。...
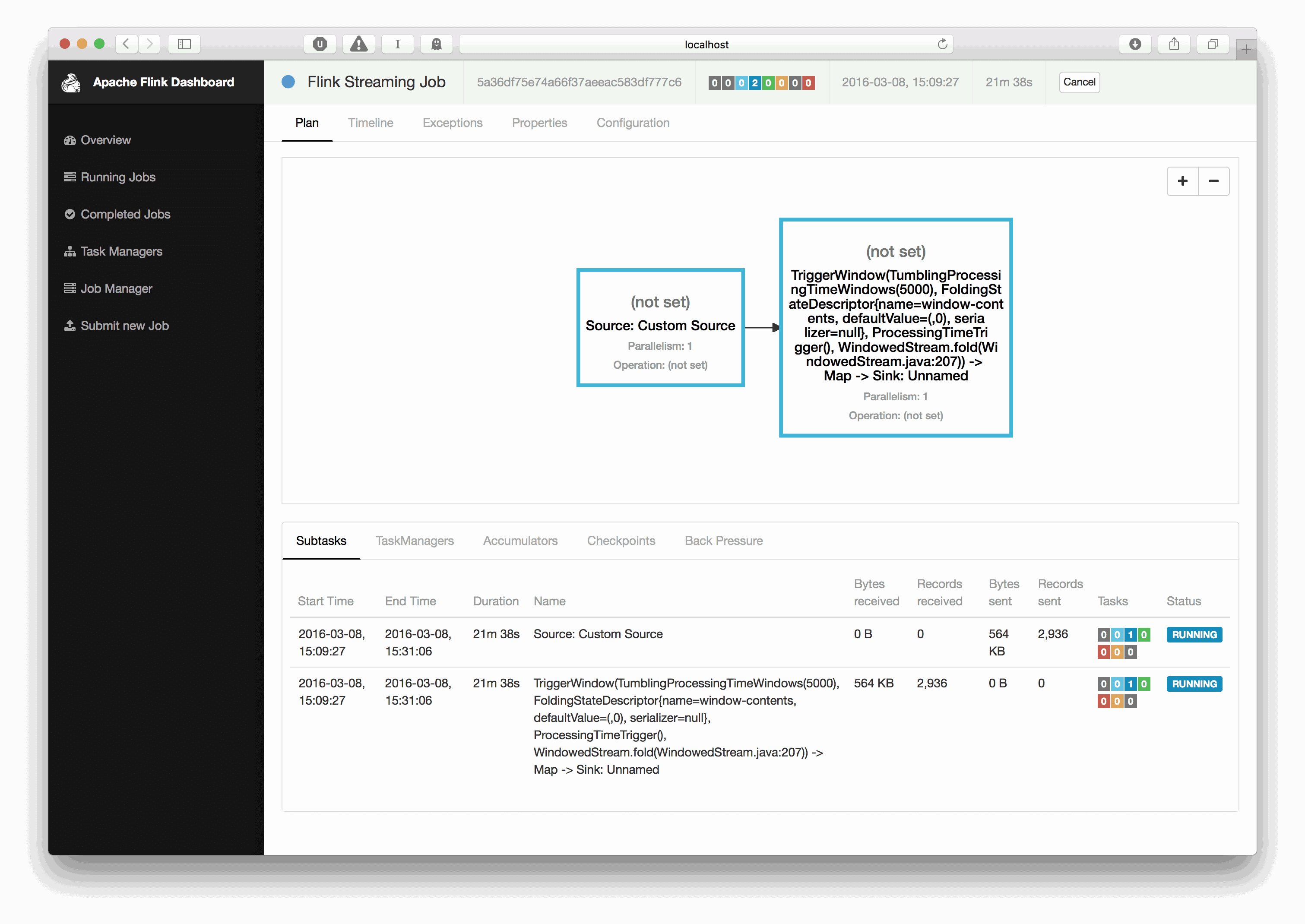
从头开始,从设置Flink项目到在Flink集群上运行流分析程序。 Wikipedia提供了一个IRC频道,其中记录了对Wiki的所有编辑。我们将在Flink中读取此通道,并计算每个用户在给定时间窗口内编辑的字节数。这很容易使用Fli...
Flink提供命令行界面(CLI)来运行打包为JAR文件的程序,并控制它们的执行。CLI是任何Flink设置的一部分,可在本地单节点设置和分布式设置中使用。它位于<flink-home>/bin/flink 默认情况下,并...

对于单节点设置,Flink已准备好开箱即用,您无需更改默认配置即可开始使用. 开箱即用的配置将使用您的默认Java安装.您可以手动设置环境变量JAVA_HOME或配置项env.java.home中conf/flink-con...