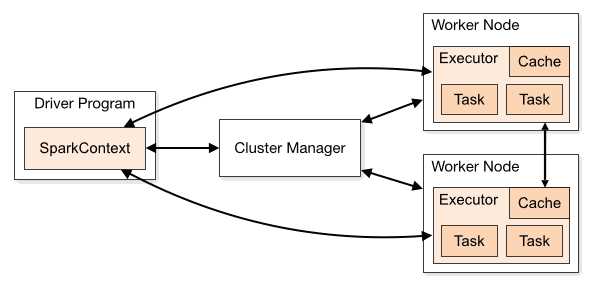
一. Apache Spark是什么?Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。S...
一. Apache Spark是什么?Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。S...
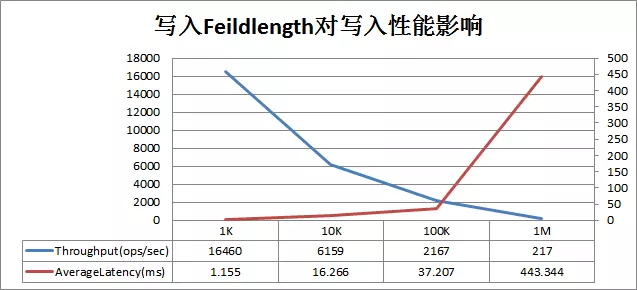
一. 监控为什么需要监控?为了保证系统的稳定性,可靠性,可运维性。 掌控集群的核心性能指标,了解集群的性能表现。 集群出现问题时及时报警,便于运维同学及时修复问题。 集群重要指标值异常时进行预警,将问题扼杀在摇篮中,不用等集群真正不...
一 简介       若在生产环境中使用HBase,必须了解备份HBase的各种可选方案和操作方法.备份HBase时的难点是其待备份的数据集可能非常巨大,因此备份方案必须有很高的效果.HBase...
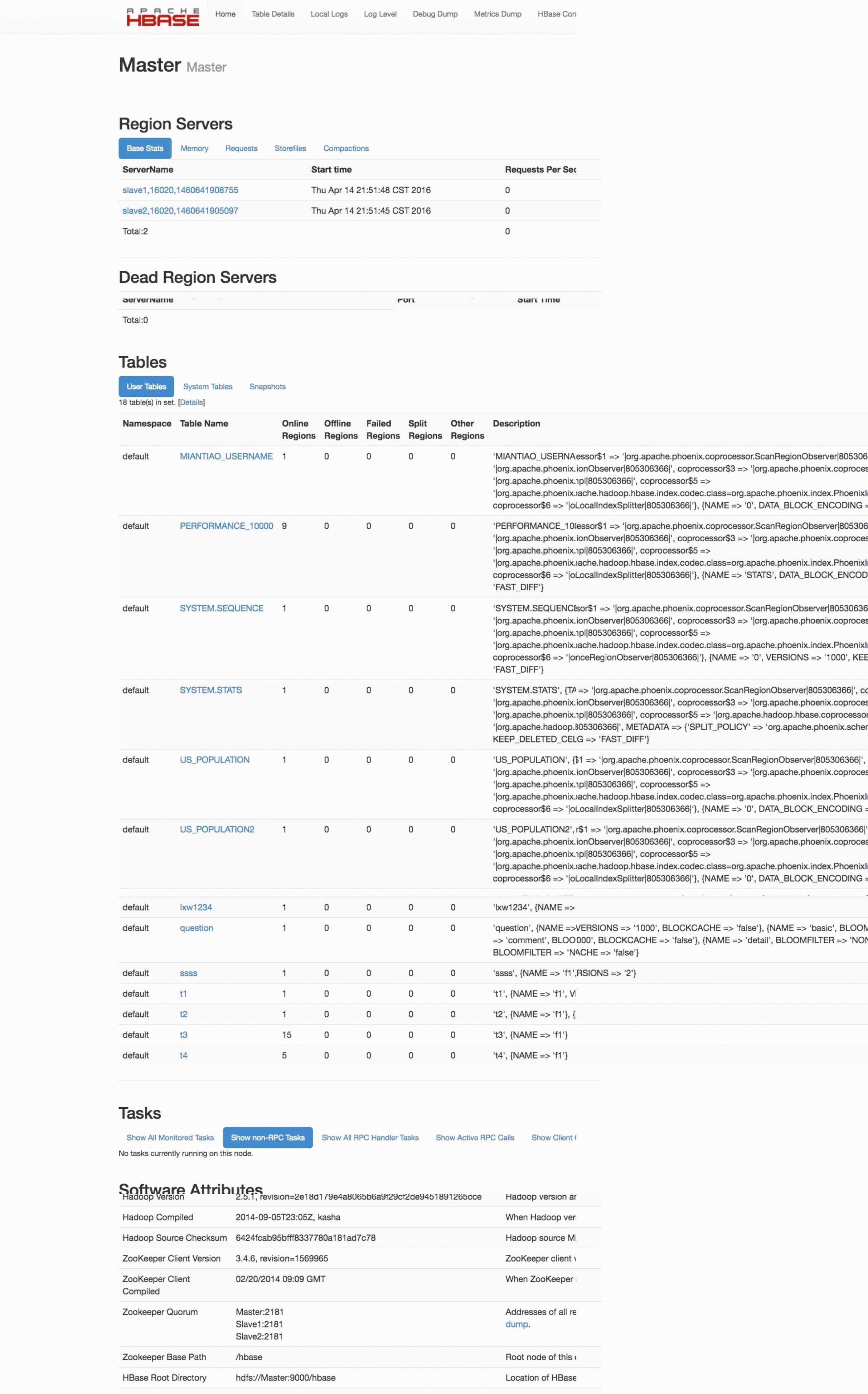
每个人都希望自已的HBASE管理员能够让集群运行流畅,存储大量的数据,并且能同时,迅速和可靠地处理几百万的并发请求.对于管理员来说,让HBASE中海量数据一直保持可存取,易管理和便于查询是一项至关重要的任务. 除了对于你运行的集群要有...
通过PutAPI的方法来导出数据概述HBase本身提供了很多种数据导入的方式,通常有两种常用方式: 使用HBase提供的TableOutputFormat,原理是通过一个Mapreduce作业将数据导入HBase 另一种方式就是使用...
概述将数据移到Hbase的方法有以下几种: 使用Hbase的Put API 使用HBase的批量加载工具 使用自定义的MapReduce方法 使用HBase的Put API是最直接的方法.这种方法的使用并不难学,但大多数情况下,它...

一 整合SQL引擎层 NOSQL(Not only SQL 非关系型数据库)的特性之一是不使用SQL作为查询语言,本节简单介绍NOSQL定义,为何NOSQL 上定义SQL引擎,以及现有基于HBASE的SQL引擎的具体实现 NOSQL...
1 两者分别是什么?       Apache Hive是一个构建在Hadoop基础设施之上的数据仓库。通过Hive可以使用HQL语言查询存放在HDFS上的数据。HQL是一种类SQL语言,这种语...
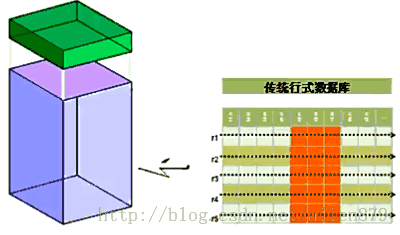
一 主要区别 Hbase适合大量插入同时又有读的情况 Hbase的瓶颈是硬盘传输速度,Oracle的瓶颈是硬盘寻道时间。 Hbase本质上只有一种操作,就是插入,其更新操作是插入一个带有新的时间戳的行,而删除是插入一个带有插...
一. 安装包安装happybase和thrift pip install happybase pip install thrift 二. 表操作DDL创建连接:1connection = happybase.Connectio...