一. 简介前面使用 Silk 工具进行知识融合。但实际操作中发现,当数据量较大时,会出现内存爆掉的情况。同时由于 Silk 的 SPARQL 查询语句比较复杂,当数据量大时,获取同样的数据要慢上很多倍。因此我这里将数据分成一个一个的小...
一. 简介前面使用 Silk 工具进行知识融合。但实际操作中发现,当数据量较大时,会出现内存爆掉的情况。同时由于 Silk 的 SPARQL 查询语句比较复杂,当数据量大时,获取同样的数据要慢上很多倍。因此我这里将数据分成一个一个的小...
一. 简介silk 是一个集成异构数据源的开源框架。编程语言为Python。其特点为: 提供了专门的 Silk-LSL 语言来进行具体处理。 提供图形化用户界面- Silk Workbench,用户可以很方便的进行记录链接。 Si...
一. 简介 Apache Jena是专门用于语义网本体操作的开源Java框架,其提供RDF和SPARQL API,来查询、修改本体和进行本体推理,并且提供了TDB和Fuseki来存储和管理三元组。 Fuseki是Jena提供的SP...
一. 简介Direct mapping 本质上是通过编写启发式规则将数据库中的表转换为RDF三元组, 但该方式灵活性不强。这里我们用 D2RQ 工具,它的主要功能是提供以虚拟的、只读的RDF图形式进入到关系型数据库中。也就是说比如你通...
一. 简介 在数据爬取过程中,想尝试复现一个经典的神经网络关系抽取模型。经过看论文筛选最终确定清华的Neural Relation Extraction with Selective Attention over Instances。...
一. 简介 前面我们爬取了百度百科的数据,获取400W的数据大概需要10天左右。接下来我们需要把它存到图数据库里来,这里我还是使用neo4j,没选Jena的原因是我个人认为在没有本体模型的情况下,在neo4j上好好的建立上下位关系也许...
一. 简介之前做的知识图谱还是太小,而且单一领域的图谱构建技术和通用百科类图谱间的技术差别也较大,因此根据前人的论文,尝试构建百科类知识图谱。 为了构建中文百科类知识图谱,我们参考漆桂林老师团队做的zhishi.me。目标是包含百度百...
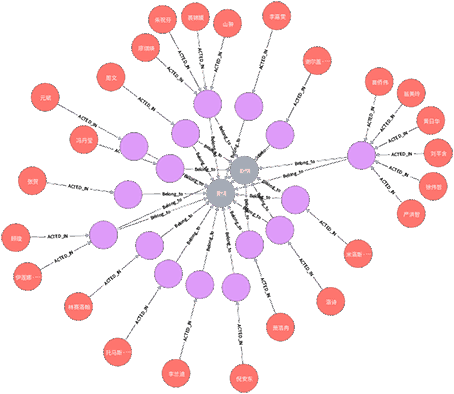
一. 简介图数据库是基于图论实现的一种新型NoSQL数据库。它的数据数据存储结构和数据的查询方式都是以图论为基础的。图论中图的节本元素为节点和边,对应于图数据库中的节点和关系。 Neo4j 是由 Java 实现的开源 NoSQL 图数...
一. 简介前面完成了针对结构化数据和半结构化数据的知识抽取工作,本节我们进行基于Deepdive框架的非结构化文本关系抽取。所采用的文本来自于百度百科的人物介绍。本次实战基于OpenKG上的支持中文的deepdive:斯坦福大学的开源...
一. 简介 本次我们基于浙江大学在openKG上提供的基于elasticsearch的KBQA实现及示例,我们将其精简并将应用到自己的知识图谱上。 ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用...