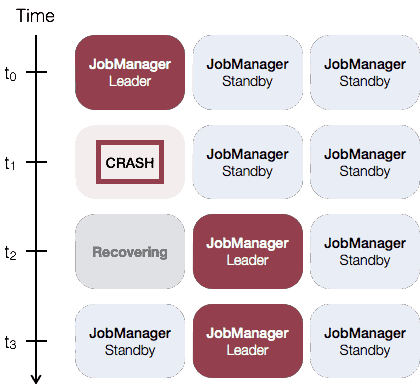
JobManager高可用性(HA)JobManager协调每个Flink部署。它负责调度和资源管理。 默认情况下,每个Flink群集都有一个JobManager实例。这会产生单点故障(SPOF):如果JobManager崩溃,则无法...
JobManager高可用性(HA)JobManager协调每个Flink部署。它负责调度和资源管理。 默认情况下,每个Flink群集都有一个JobManager实例。这会产生单点故障(SPOF):如果JobManager崩溃,则无法...
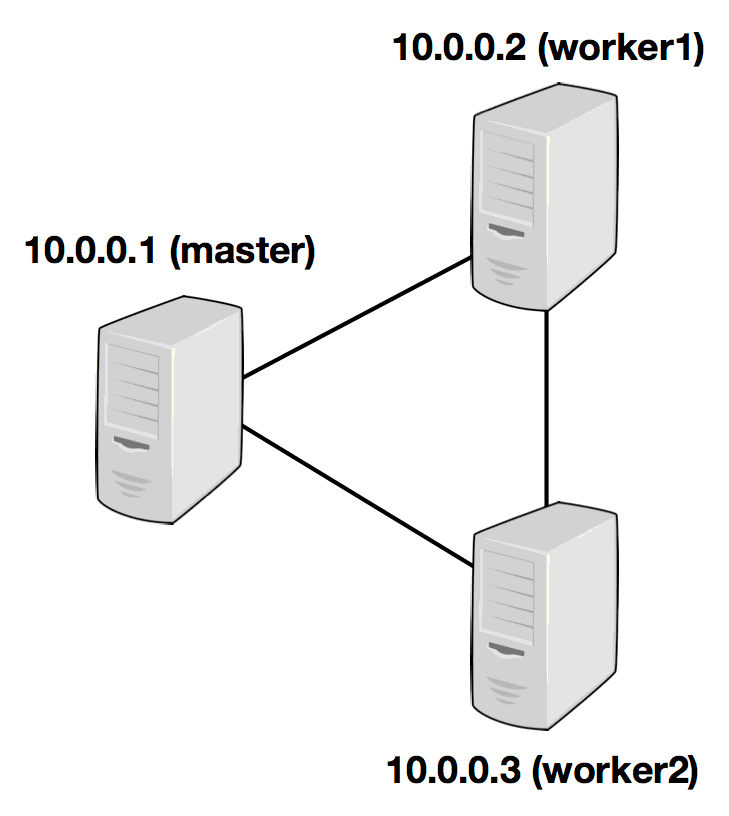
独立群集此页面提供有关如何在静态(但可能是异构)集群上以完全分布式方式运行Flink的说明。 要求软件要求Flink可在所有类UNIX环境中运行,例如Linux,Mac OS X和Cygwin(适用于Windows),并期望集群由一个...
Flink可在Linux,Mac OS X和Windows上运行。为了能够运行Flink,唯一的要求是安装一个有效的**Java 8.x.** 在Linux,Mac OS X上设置:下载并启动Flink您可以通过发出以下命令来检查J...
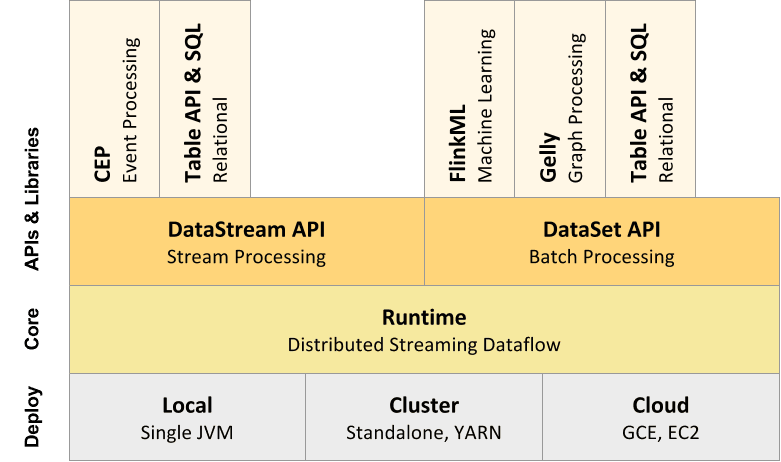
一、组件堆栈作为软件堆栈,Flink是一个分层系统。堆栈的不同层构建在彼此之上,并提高它们接受的程序表示的抽象级别: 在运行时层中的形式接收节目JobGraph。JobGraph是一个通用的并行数据流,具有消耗和生成数据流的任意任务...

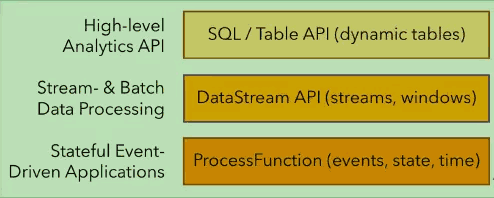
一、数据流编程模型抽象层次Flink提供不同级别的抽象来开发流/批处理应用程序。 最低级抽象只提供有状态流。它 通过Process Function(过程函数)嵌入到DataStream API(流式传输)中。它允许用户...
一、Flink介绍既然有了Apache Spark,为什么还要使用Apache Flink? 因为Flink是一个纯流式计算引擎,而类似于Spark这种微批的引擎,只是Flink流式引擎的一个特例。 Flink是一款分布式的计算引擎,...

这里分享一些自己学习过程中觉得不错的资料和开发工具。 经典书籍 《hadoop 权威指南(第四版)》 2017年 《Kafka权威指南》 2017年 《从Paxos到Zookeeper 分布式一致性原理与实践》 2015年 《Sp...
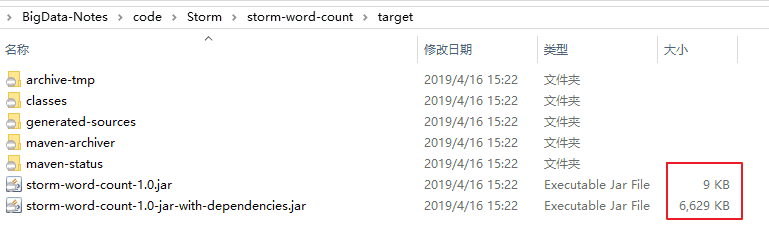
一、简介在提交大数据作业到集群上运行时,通常需要先将项目打成JAR包。这里以Maven为例,常用打包方式如下: 不加任何插件,直接使用mvn package打包; 使用maven-assembly-plugin插件; 使用maven...
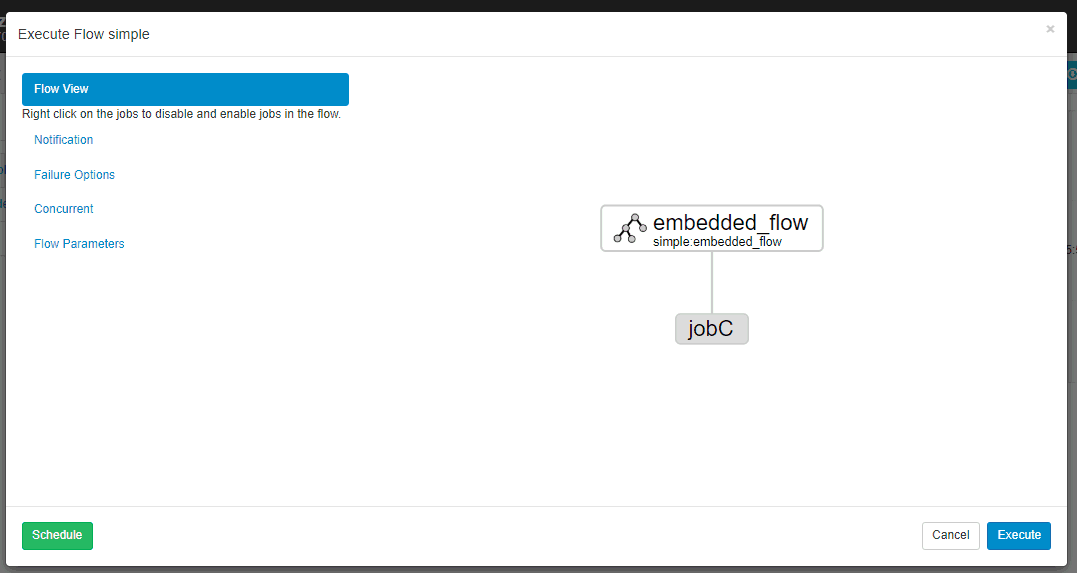
一、Flow 2.0 简介1.1 Flow 2.0 的产生Azkaban 目前同时支持 Flow 1.0 和 Flow2.0 ,但是官方文档上更推荐使用Flow 2.0,因为Flow 1.0会在将来的版本被移除。Flow 2.0的主要...
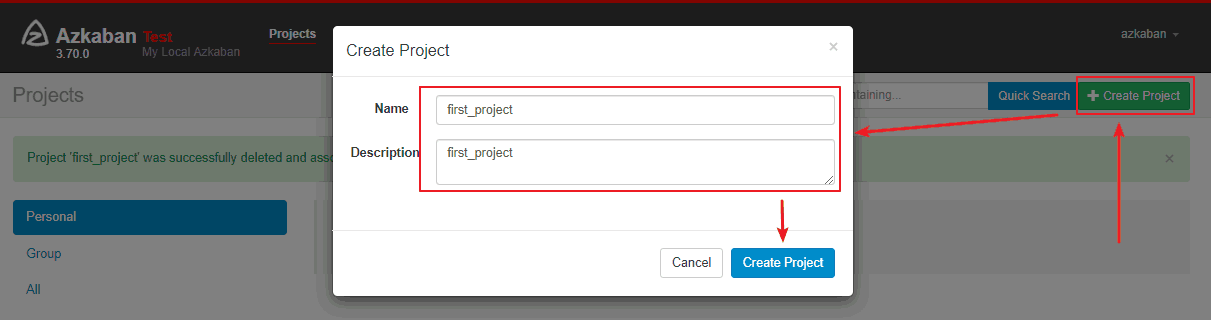
一、简介Azkaban主要通过界面上传配置文件来进行任务的调度。它有两个重要的概念: Job: 你需要执行的调度任务; Flow:一个获取多个Job及它们之间的依赖关系所组成的图表叫做Flow。 目前 Azkaban 3.x 同时...